4 معیار مناسب برای ارزیابی مدلها در مسائل رگرسیون
رگرسیون یکی از رایجترین مسائل یادگیری ماشین هست که در آن خروجی مقادیر پیوسته و نامحدود هست. همانند مسائل طبقه بندی، در مسائل رگرسیون نیز نیاز به معیارهای ارزیابی هستیم تا بتوانیم عملکرد مدلهای رگرسیون را بررسی کنیم. در این پست 4 معیار معروف جهت ارزیابی مدلهای رگرسیون را توضیح میدهیم.
رگرسیون
زمانی که شما میخواهد خروجی ای تخمین بزنید که مقادیری آن پیوسته و نامتناهی هست، شما با یک مسئله رگرسیون سروکار دارید! چندتا از مسائل رگرسیون عبارت اند از:
- تخمین میزان درآمد یک فرد براساس میزان تحصیلات، تجربه کاری و ….
- تخمین قیمت یک خانه براساس مشخصات آن…
- پیش بینی میزان آلودگی هوا براساس میزان آلاینده های موجود در هوا…
جهت بررسی بیشتر رگرسیون پیشنهاد میکنم پست “ فرق بین کلاسبندی و رگرسیون” را مطالعه کنید.
بعد از طراحی مدل یادگیری ماشین برای مسئله رگرسیون، شما نیاز دارید که مدل رگرسیون را با پارامترهای مناسبی ارزیابی کنید تا از عملکرد مدل خود اطمینان حاصل کنید. معیارهای زیادی جهت ارزیابی مدل رگرسیون وجود دارد که هر کدام از آنها ویژگی های خاص خودشان را دارند. در این بخش چندتا از این معیارها رو بررسی میکنیم.
معیار correlation
Correlation میزان شباهت(همبستگی) خروجی تخمین زده شده توسط مدل رگرسیون با خروجی واقعی را محاسبه میکند. اگر مدل رگرسیون خوب عمل کند، خروجی های تخمین زده شده توسط مدل شباهت زیادی با خروجی واقعی خواهند داشت و در نتیجه همبستگی بین خروجی های تخمین زده شده و خروجی های واقعی نزدیک یک خواهد بود.
Correlation طبق رابطه زیر محاسبه می شود:
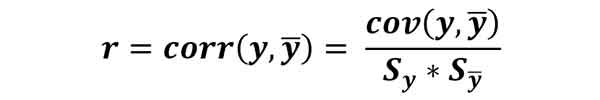
مقادیر Correlation بین -1 و 1 هست، هر چقدر مقدار به یک نزدیکتر باشد، یعین خروجی های تخمین زده شده شبیه خروجی های واقعی هستند و هرچقدر نزدیک به -1 باشد یعنی نه تنها شباهتی بین دو خروجی وجود ندارد بلکه رفتاری کاملا متضاد دارند.
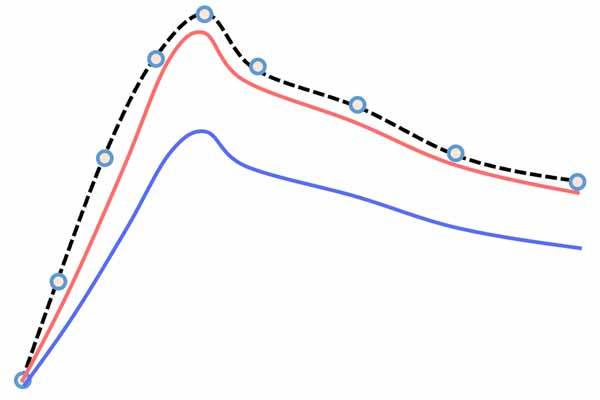
لازم به ذکر هست که معیار correlation به دامنه حساس نیست و میزان شباهت دو خروجی را تنها براساس رفتار متقابل دو خروجی محاسبه میکند. اگر فرض کنید در شکل زیر منحنی خط چین مشکی رنگ خروجی واقعی باشد و منحنی قرمز و آبی خروجی تخمین زده شده دو تا مدل متفاوت باشند. با اینکه منحنی قرمز رنگ از لحاظ دامنه خیلی نزدیک به خروجی واقعی هست اما هر دو خروجی تخمین زده شده(قرمز و آبی) با خروجی واقعی همبستگی یکسانی خواهند داشت. چرا که هر دو خروجی رفتاری شبیه به خروجی واقعی دارند.
معیار R square
R square مشخص میکند که مدل رگرسیون تا چه میزان خوب روی یک داده فیت شده است. یک مدل زمانی روی یک داده به طور مناسب فیت می شود که اختلاف بین خروجی واقعی و خروجی تخمین زده شده توسط مدل حداقل و غیربایاس باشد. معنی unbiased اینه که اختلاف بین خروجی تخمین زده شده و خروجی واقعی در هیچ جایی خیلی کم و یا خیلی زیاد نباشد.
R square میزان توضیح دهندگی مدل را بیان می کند. به عبارتی R square مشخص میکند که یک مدل تا چه میزان از تغییرپذیری متغیر وابسته را میتواند بیان کند. R square
طبق رابطه زیر محاسبه می شود:
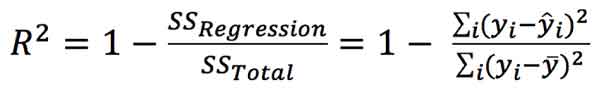
مقادیر R square بین صفر تا یک هست. بهترین حالت زمانی هست که R square مدل رگرسیون برابر با یک شود، و بدترین حالت زمانی هست که R square مدل برابر صفر شود. مقدار زیاد R square به معنی هست که اختلاف کمتری بین خروجی تخمین زده شده و خروجی واقعی وجود دارد.
معیار ارزیابی Mean Square Error(MSE)
در حالی کهR square یک معیار نسبی برای بررسی میزان فیت شدن مناسب مدل بر متغیرهای وابسته است، MSE یک معیار مطلق برای اینکار است. MSE میانگین مربعات خطا هست و طبق رابطه زیر محاسبه می شود:
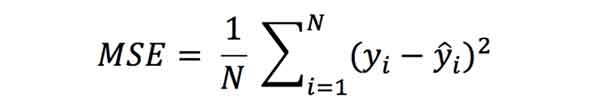
MSE مشخص میکند که نتایج بدست آمده توسط مدل شما چقدر با مقادیر واقعی متفاوت هست. این معیار به شما کمک میکند که بهترین مدل را انتخاب کنید. هر چقدر MSE کم باشد، بدین معنی هست که مدل شما خوب عمل کرده و اختلاف بین خروجی تخمین زده شده توسط مدل با خروجی واقعی کم هست.
معیار Mean Absolute Error(MAE)
معیار MAE از لحاظ مشخصات شبیه MSE هست، با این تفاوت که در MAE به جای محاسبه میانگین مربعات خطا( اختلاف بین خروجی تخمین زده شده و خروجی واقعی)، قدرمطلق خطا محاسبه می شود.
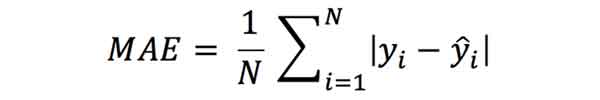
در مقایسه با MSE، معیار MAE ارائه مستقیم تری از مجموع خطا دارد. چراکه MSE با خطاها متفاوت برخورد میکند. برای مثال اگر خطا زیاد باشد، موقع به توان رسیدن مقدار خطا خیلی زیادتر می شود در حالی که اگر مقدار خطا کم باشد، با توان دو رسیدن خطا، مقدار خیلی تغییر نمیکند. این در حالی هست که در MAE تمامی خطا یکجور برخورد میشود و قدرمطلق خطا(اختلاف) محاسبه می شود.
در دوره جامع ” شناسایی الگو-یادگیری ماشین” و دوره “شبکه عصبی“، الگوریتمهای مختلفی برای رگرسیون به صورت پروژه محور آموزش داده شده است. پیشنهاد میکنیم که این دوره ها را مطالعه کرده و از الگوریتمهای آموزش داده شده، در پروژه های تخصصی خود استفاده کنید.
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)

ممنون بابت توضیحاتون