بلاگ علمی
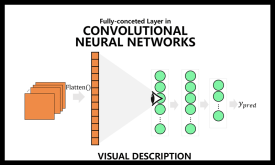
نقش لایههای Fully Connected در شبکههای عصبی کانولوشنی (CNN)
لایههای Fully Connected (FC) یا Dense Layers یکی از مهمترین بخشهای شبکههای عصبی کانولوشنی (CNN) هستند. این لایهها معمولاً در انتهای شبکه قرار میگیرند و وظیفه نهایی آنها تصمیمگیری برای طبقهبندی یا تخمین خروجی (regression) است. اما نقش لایههای Fully…

معرفی چندین کتاب خوب برای یادگیری عمیق (deep learning) و شبکههای عصبی
اگر به دنبال بهترین منابع یادگیری عمیق (deep learning) و شبکههای عصبی (neural networks) هستید، در این مقاله سه کتاب مرجع شامل Neural Networks and Learning Machines، Deep Learning و Dive into Deep Learning را بررسی میکنیم. این سه کتاب…
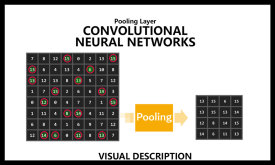
توضیح لایه Pooling در شبکههای عصبی کانولوشنالی CNNs
لایه Pooling یکی از اجزای کلیدی در معماری شبکههای عصبی کانولوشنال است که با کاهش ابعاد تصویر، ویژگیهای مهم آن را حفظ می کند. این لایه نه تنها پیچیدگی محاسباتی را به شدت کاهش میدهد، بلکه باعث بهبود تعمیمپذیری (Generalization)…
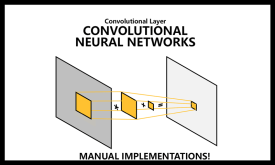
توضیح لایه کانولوشن در شبکه های عصبی کانولوشنالی CNNs
شبکه های عصبی کانولوشنالی (convolutional neural networks) یکی از مهمترین ابزار بینایی ماشین، پردازش تصویر، حتی پردازش سیگنال هستند. بعد از ظهور شبکه های عصبی CNNs، انقلاب بزرگی در حوزه بینایی ماشین و بعد در سایر حوزه ها اتفاق افتاد.…

معرفی کتابهای کدمحور برای پردازش سیگنال دیجیتال (Digital signal processing)
یادگیری پردازش سیگنال دیجیتال (DSP) زمانی مؤثرتر است که منابع آموزشی هم مفاهیم را شفاف توضیح دهند و هم مثالهای عملی و کدنویسی ارائه کنند. در این پست بهترین کتابها و منابع DSP مبتنی بر MATLAB را معرفی میکنیم. منابعی…

چگونه کشف اتفاقی Hubel و Wiesel پایهگذار بینایی ماشین و شبکههای عصبی کانولوشنی شد
در این پست داستان یکی از مهمترین کشفیات تاریخ علوم اعصاب و بینایی ماشین را بررسی میکنیم. David Hubel و Torsten Wiesel در دههٔ ۱۹۶۰ با یک آزمایش ساده و اتفاقی نشان دادند که نورونهای قشر بینایی چگونه به لبهها،…

راهنمای کامل یادگیری عمیق و PyTorch، مجموعه پستهای آموزشی
در طول یک سال گذشته تلاش کردیم مجموعه ای از مقالات آموزشی و عملی در زمینه برنامه نویسی پایتون (python)، یادگیری ماشین (Machine Learning)، یادگیری عمیق (Deep Learning) و فریم ورک PyTorch منتشر کنیم. در این آموزشها از مفاهیم پایه…

تکنیک Bag of Words در پردازش زبان طبیعی | آموزش کامل همراه با پروژهی عملی spam detection
تکنیک Bag of Words (BOW) یکی از مهمترین و پرکاربردترین روشها در استخراج ویژگیهای متنی در حوزهی پردازش زبان طبیعی (NLP) است. یکی از چالشهای اصلی در دادههای متنی، تفاوت اندازهی بردار ویژگی بین نمونه ها است که فرآیند آموزش…

دوره جامع یادگیری عمیق (RNNs, CNNs, Attention)
در فصل اول با مفاهیم پایه آشنا میشویم، از جمله پس انتشار خطا، توابع هزینه، روشهای بهینهسازی، dropout, batch normalization و ساخت dataloader در پایتورچ . در فصل دوم تئوری و ریاضیات شبکه های عصبی بازگشتی (RNNs, LSTMs, GRUs, BiLSTMs)…

تولباکس SSVEP-پیاده سازی تمام روشهای تشخیص فرکانس SSVEP
واسط مغز-کامپیوتر مبتنی بر SSVEP یکی از پارادایمهای معروف این حوزه هست که به خاطر داشتن نسبت سیگنال به نویز بالا، داشتن ITR نسبتا بالا و زمان آموزش کم کاربر نسبت به سایر پارادایمها، در بین محققین محبوبیت زیادی دارند.…

پیش پردازش خودکار سیگنالهای مغزی EEG با تولباکس HAPPE
تولباکس Harvard Automated Processing Pipeline for EEG (HAPPE) توسط گروه تحقیقاتی در دانشگاه Harvard توسعه داده شده است که از آن میتوان برای حذف خودکار آرتیفکتها در سیگنالهای EEG استفاده کرد. یکبار پارامترها توسط کاربر تعیین میشود، سپس این تولباکس…

چند منبع خوب برای یادگیری پردازش سیگنال مغزی EEG
برای پردازش سیگنال های مغزی (EEG) داشتن دانش پایه بسیار میتواند کمک کننده باشد. آشنا بودن با مباحثی مانند ساختار مغز، فرایند تولید امواج مغزی، نحوه ثبت سیگنال EEG، انواع نویزها در سیگنالهای مغزی و نحوه حذف آنها و روشهای…