
شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 3 دیدگاه
یادگیری جمعی (ensemble learning) حوزهای در یادگیری ماشین است که در این حوزه تکنیکهایی مطرح شده است که به کمک آنها از چندین مدل به صورت ترکیبی و همزمان جهت تصمیم گیری استفاده میکنند تا توان مدل در تخمین خروجی داده را بالا ببرند. در این فصل تکنیکهای یادگیری جمعی از قبیل voting, staking, bagging و boosting را برای برای ترکیب مدلها در مسائل رگرسیون و طبقهبندی آموزش داده و پیاده سازی میکنیم و در انتها چندین پروژه عملی انجام میدهیم. این فصل یکی از مهمترین فصلهای دوره جامع شناسایی الگو و یادگیری ماشین است، چرا که مباحث آموزش داده شده در پروژه های عملی جهت افزایش عملکرد خیلی میتواند کمکمان کند.
فصل پنجم: یادگیری جمعی (Ensemble learning)
همه ما تجربه کار گروهی را داشتیم و میدانیم که اگر یک گروه متحدی داشته باشیم و همه برای هم و به یک هدف تلاش کنند، مطمئنا نتیجه کار بهتر خواهد شد. اما این وسط یکی باید باشد که بین افراد یک هماهنگی ایجاد کند تا همه بتوانند در راستای هدف حرکت کنند. اگر مدیریت خوبی اتفاق نیافتد معلوم نیست سرانجام کار به کجا برسد. همانطور که در کلیپ کوتاه زیر می بینیم، اگر در کارها به صورت تیمی اما متحد عمل کنیم کارها بسیار آسان خواهد بود. تکنیکهای یادگیری جمعی(ensemble learning) نقش یک مدیر در گروه را دارند و مدلهای مختلف با یک رویکردی ترکیب می کنند تا یک سیستم بهنیه طراحی کنند که توانایی حل پیچیده ترین مسائل باشد.
همان رویکرد را ما در پروژه های تخصصی یادگیری ماشین و شناسایی الگو داریم، مطمئنا یک سری مسائل پیچیده داریم که یک مدل هر چقدر هم که خوب باشد، به تنهایی توانایی حل مسئله را ندارد، برای حل چنین مسائلی ما از رویکرد یادگیری جمعی استفاده میکنیم، و به جای اینکه از یک مدل یادگیری ماشین استفاده کنیم، از چندین مدل به صورت ترکیبی استفاده میکنیم و توان تخمین مدل نهایی را بالا میبریم. این فصل یکی از مهمترین فصلهای دوره شناسایی الگو و یادگیری ماشین است که مباحث آموزش داده شده در پروژه های عملی خیلی میتواند کمکمان کند.
جلسه اول: هدف یادگیری جمعی
در جلسه اول فصل پنجم دوره پترن و یادگیری ماشین ما هدف یادگیری جمعی را توضیح میدهیم و نشان میدهیم که چرا از این حوزه یادگیری ماشین در بین محققان استقبال زیادی می شود. یادگیری جمعی حوزه از یادگیری ماشین هست که در آن به جای اینکه از یک مدل برای حل یک مسئله استفاده کنند، از چندین مدل به صورت ترکیبی استفاده می کنند تا توان توان تخمین خروجی مدل را بالا تر ببرند.
شاید برای خیلی ها سوال ایجاد شود که چرا ما از یک مدل استفاده نمی کنیم و میخواهیم از چندین مدل استفاده کنیم، دلایل زیادی برای اینکار وجود دارد که به سه تا از مهمترین دلایل را در زیر توضیح میدهیم: تعداد پایگاه داده: مهمترین بخش یک پروژه یادگیری ماشین و شناسایی الگو پایگاه داده است، قدم اول ما در یک پروژه، تهیه پایگاه داده مناسب و هدفمند برای تسک مورد نظر است تا بعدا بتوانیم در مراحل بعدی با کمک این داده مدل خود را طراحی کنیم تا تسک مورد نظر را انجام دهد. مسئله ای که هست در بعضی موارد پایگاه داده ای که داریم ممکن است تعداد داده های ثبت شده بسیار زیاد باشد و یا برعکس، خیلی کم باشد. در هر دو حالت ما با مشکل مواجه می شویم، مسئله ای که هست ما همیشه دوست داریم تعداد داده بسیار زیادی داشته باشیم تا مدلی که طراحی میکنیم بتواند با کمک پایگاه داده تمام فضای ویژگی و تمام حالت های ممکن داده را بشناسد تا در عمل بتواند به خوبی عمل کند. وقتی تعداد داده ها خیلی زیاد باشد، آموزش یک مدل با این حجم از داده عملا امکان پذیر نیست و باید به نوعی حجم داده را کم کنیم تا بتوانیم مدل را آموزش دهیم ولی خب وقتی حجم داده را کم می کنیم در این صورت تمام فضای ویژگی برای مدل قابل شناسایی نخواهد بود، و اگه کم نکنیم مدل نمیتواند آموزش ببیند! در چنین مسائلی راه چاره این است که از رویکرد یادگیری جمعی استفاده کنیم، و بیاییم داده را به چندین زیرمجموعه کوچک تقسیم کنیم و با هر زیر مجموعه کوچک یک مدل را آموزش دهیم، اینطوری هم میتوانیم مدل را آموزش دهیم و سرعت آموزش را بالا ببریم و هم با کمک ترکیب مدلها کل فضای ویژگی را بشناسیم و مدل ترکیبی نهایی یک مدل بسیار قوی خواهد بود. چون تک تک مدلها هر کدام یک بخشی از فضای ویژگی را می شناسد و کنارهم کل فضای ویژگی را می شناسند. مشکل بعدی این است که در بعضی موارد تعداد داده بسیار کم است و اگر بخواهیم یک مدل را با این داده آموزش بدهیم دو تا مشکل اساسی ممکن است پیش بیاید، اگر مدل ساده استفاده کنیم، مدل underfit خواهد شد و اگر از مدل پیچیده استفاده کنیم، ممکن است مدل overfit شود. درهر دو حالت در عمل نتیجه مطلوب نخواهد بود، برای حل چنین مسائلی باز از رویکرد یادگیری جمعی استفاده می کنند، و با کمک bootstrap داده های مختلفی از روی داده اصلی میسازند و چندین مدل را با هر کدام داده های ساخته شده آموزش می دهند و در نهایت یک مدل بهینه ترکیبی ایجاد می کنند که توان تخمین مدل بالا رفته و در عمل خوب عمل خواهد کرد.
مسئله پیچیده: زمانی که یک مسئله پیچیده داریم، امکان حل مسئله با یک مدل به تنهایی امکان پذیر نیست، در چنین مواردی از یادگیری جمعی کمک میگیریم و با استفاده از چندین مدل به صورت ترکیبی مسئله را حل می کنیم. سطح اطمینان: ما همیشه میخواهیم سیستمی طراحی کنیم که بتوانیم در عمل با اطمینان بالا استفاده کنیم و نگرانی در این زمینه نداشته باشیم، خب مسلما ما به راحتی به یک مدل نمیتوانیم اعتماد کنیم، ولی اگر چندین مدل (خوب) داشته باشیم سطح اطمینان ما بالا می رود. چون زمان تصمیم گیری ما به جای اینکه ما به نظر یک مدل نگاه کنیم، به نظر چندین مدل نگاه می کنیم و طبق رای جمع تصمیم میگیریم و در این حالت ما سطح اطمینان بالایی داریم. در جلسه اول به طور مفصل در مورد این مباحث صحبت کرده ایم.جلسه دوم: ترکیب مدلهای یادگیری ماشین به روش voting در مسائل کلاسبندی و رگرسیون
در این جلسه ما یکی از تکینک های بسیار جالب و البته بسیار سادهی یادگیری جمعی را آموزش داده ایم. در این جلسه در ابتدا رویکرد ترکیب مدلها در روش voting برای مسائل کلاسبندی و رگرسیون را توضیح میدهیم و سپس مرحله به مرحله در متلب پیاده سازی میکنیم و سپس چندین پروژه عملی انجام میدهیم و همچنین یک سری آزمایشهایی انجام میدهیم تا هم با قابلیتهای خوب این تکنیک و هم با معایب این تکنیک آشنا شویم.
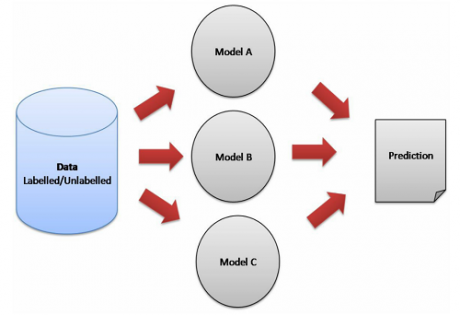
در این جلسه ما مدلهای یادگیری ماشین برای مسائل کلاسبندی و رگرسیون را توضیح میدهیم تا شخصی که فصل های قبل رو نگاه نکرده با مشکل مواجه نشود. ما برای پیاده سازی تکنیک voting از مدلهای یادگیری ماشین مختلفی از قبیل شبکه عصبی پرسپترون، ماشین بردار پشتیبان(svm- linear & non linear)، الگوریتم نزدیکترین همسایه(knn)، مدل LDA، Decision Tree، بیزین و ... استفاده کرده ایم تا یک سیستم خوب و قوی طراحی کنیم تا نتیجه کار افزایش پیدا کند.
پروژه های انجام شده:- تشخیص سرطان سینه با روش voting (پروژه کلاسبندی – مسئله دو کلاسه)
- کلاسبندی نوع گل زنبق(iris) با روش voting (پروژه کلاسبندی – مسئله 3 کلاسه)
- پیش بینی میزان آلودگی هوا با روش voting (پروژه رگرسیون)
جلسه سوم: ترکیب مدلهای یادگیری ماشین به روش stacking در مسائل کلاسبندی و رگرسیون
یکی از مشکلات اصلی تکنیک voting این است که در پروسه تصمیم گیری به تمامی مدل ها سهم یکسانی میدهد، بدون اینکه به قابلیت مدل ها توجهی شود و در چنین مواقعی مدلهای ضعیف تاثیر یکسانی با مدلهای قوی دارند و همین باعث کاهش عملکرد در سیستم نهایی می شود. ما این مشکلات را در جلسه سوم با آزمایشاتی که انجام دادیم به صورت عملی نشان دادیم. در این جلسه ما یکی از مهمترین تکنیکهای یادگیری جمعی را برای حل مشکل voting آموزش داده ایم. تکنیک stacking به نوعی حالت بهبود یافته شده تکنیک voting است. در این تکنیک هر مدل سهم متفاوتی در پروسه تصمیم گیری دارد و این سهم در پروسه آموزش توسط مدل تصمیم گیرنده مشخص میشود. همانند فلوچارت زیر، در این تکنیک دو مرحله آموزش داریم، در مرحله مدلهای پایه همانند تکنیک voting با یک داده ای آموزش داده می شوند و در مرحله دوم مدل نهایی سیستم آموزش می بیند که نقش تصمیم گیرنده نهایی را دارد و در پروسه آموزش یاد میگیرد که هر مدل به چه صورت کار می کند و طبق توان مدل به هر کدام یک وزنی را مشخص می کند تا در پروسه تصمیم گیری استفاده کند.
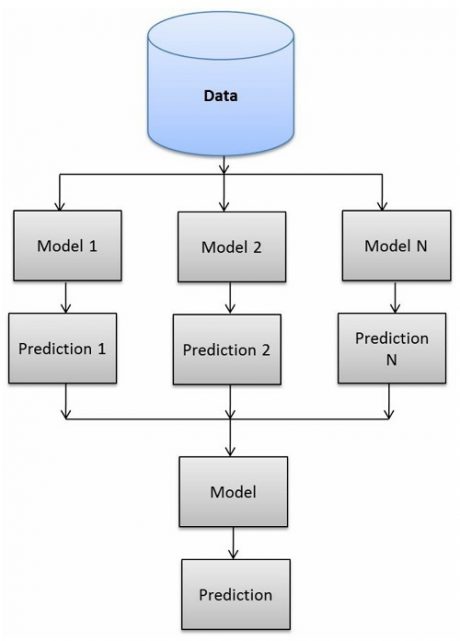
ما در این جلسه در ابتدا روال کار توضیح میدهیم سپس به صورت مرحله مرحله پیاده سازی کرده و در نهایت چندین پروژه عملی انجام میدهیم تا با آزمایشاتی که در این پروژه ها انجام میدهیم متوجه بشویم که به چه صورت باید از این تکنیک در عمل استفاده کنیم و عملکرد سیستم طراحی شده را بالا ببریم.
پروژه های انجام شده:
- تشخیص سرطان سینه با روش stacking (پروژه کلاسبندی – مسئله دو کلاسه)
- کلاسبندی نوع گل زنبق(iris) با روش stacking (پروژه کلاسبندی – مسئله 3 کلاسه)
- پیش بینی میزان آلودگی هوا با روش stacking (پروژه رگرسیون)
جلسه چهارم: ترکیب مدلهای یادگیری ماشین به روش Bagging در مسائل کلاسبندی و رگرسیون
ما در عمل مسائلی داریم که بسیار پیچیده هستند و برای اینکه بتوانیم این مسائل را حل کنیم لازم است که از مدلهای پیچیده استفاده کنیم. ولی مشکلی که هست این است که همانند تصویر زیر در بعضی مواقع مدلی که استفاده می کنیم، در پروسه آموزش خیلی خوب عمل می کند ولی در عمل میبینیم که اصلا خوب کار نمی کند و دقت کار بسیار پایین است.

مشکل این مسائل این است که مدل پیچیده ای که استفاده کرده ایم، over-fit شده است، یا به اصلاح مدل ما high variance شده است و همین باعث شده که نتیجه کار بسیار بد باشد، برای حل این مشکل از تکنیک معروف Bagging استفاده می کنند. تکینک Bagging برای حداقل کردن واریانس ارائه شده است و میتوانیم با کمک این تکنیک دیگر نگرانی over-fit شدن مدل را نداشته باشیم. همانطور که در شکل زیر نشان داده شده است این تکنیک از دو مرحله تشکیل شده است که مرحله اول این تکنیک چندین مدل پایه هر کدام با یک داده ای که توسط روش Bootstrap از روی داده اصلی ساخته می شوند آموزش داده میشوند و در مرحله بعدی(aggregating) نظر مدلها همانند تکنیک voting باهم ترکیب می شوند و خروجی داده جدید تخمین زده می شود.
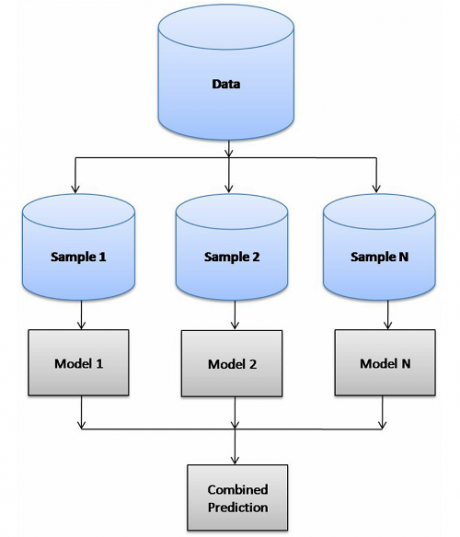
ما در این جلسه در ابتدا روال کار توضیح میدهیم سپس به صورت مرحله مرحله پیاده سازی کرده و در نهایت چندین پروژه عملی انجام میدهیم تا با آزمایشاتی که در این پروژه ها انجام میدهیم متوجه بشویم که به چه صورت باید از این تکنیک در عمل استفاده کنیم و عملکرد سیستم طراحی شده را بالا ببریم.
پروژه های انجام شده:
- تشخیص سرطان سینه با روش Bagging (پروژه کلاسبندی – مسئله دو کلاسه)
- کلاسبندی نوع گل زنبق(iris) با روش Bagging (پروژه کلاسبندی – مسئله 3 کلاسه)
- پیش بینی میزان آلودگی هوا با روش Bagging (پروژه رگرسیون)
جلسه پنجم-بخش 1: ترکیب مدلهای یادگیری ماشین به روش آدابوست( Adaboost) در مسائل کلاسبندی
تکنیک adaboost یکی از مهمترین روشهای یادگیری جمعی است. این تکنیک به خاطر قابلیتهایی که دارد مورد استقبال زیادی قرار گرفته است. همانطور که از اسم این مدل پیداست، در این تکنیک مدلهای پایه به صورت سازگار تقویت می شوند و مسائل پیچیده را حل می کنند. ما در حل مسائل پیچیده دو راه داریم، یا باید از مدلهای ساده و یا از مدلهای پیچیده استفاده کنیم. مدلهای ساده به خاطر سادگی ساختارشان خاصیت generalization خیلی خوبی دارند، و در کارهای real time هم به راحتی قابل پیاده سازی هستند، منتها به خاطر همین ساختارشان نمی توانند یک مسئله پیچیده را حل کنند و به اصلاح بایاس زیادی دارند. از طرفی اگر بخواهیم از مدلهای پیچیده استفاده کنیم، احتمال اینکه overfit شود زیاد هست و یا به خاطر ساختار پیچیده ای که دارند در عمل نتوانیم به راحتی پیاده سازی کنیم. ما همیشه دوست داریم که مدل پایه ای که استفاده میکنیم ساده باشد و از طرفی میخواهیم مدلمان بایاس کمی داشته باشد و به عبارت دیگر دقت بالایی داشته باشد. تکنیک آدابوست برای حل چنین مسائلی ارائه شده است. در این تکنیک از یک مدل ضعیف به عنوان یک مدل پایه استفاده می کنند و سپس به صورت ترتیبی و سازگار این مدلها را باهم ترکیب می کنند و یک سیستم بسیار قوی ایجاد می کنند که توانایی حال مسائل پیچیده را دارد.
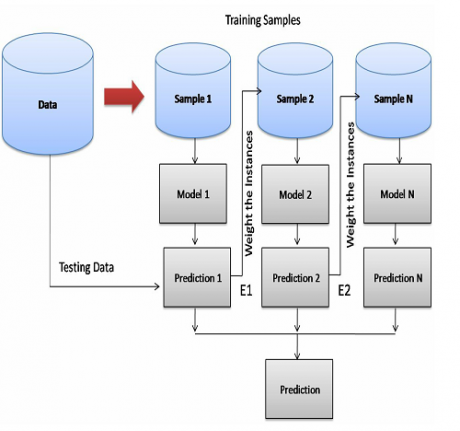
این تکنیک بسیار جالب و کاربردی هست و برای همین ما روی این تکنیک تمرکز زیاد کرده ایم و در چندین جلسه آموزش داده ایم. در این جلسه در ابتدا تئوری تکنیک آدابوست را در مسائل کلاسبندی را توضیح داده ایم و سپس به صورت مرحله به مرحله پیاده سازی کرده ایم. برای اینکه با رویکرد این تکنیک بهتر آشنا شویم چندین مثال بسیار ساده ای هم انجام داده ایم تا به صورت شکلی روند کار را نشان دهیم. ما از مدلهای مختلفی از قبییل شبکه عصبی پرسپترون تک لایه، ماشین بردار پشتیبان(svm)، مدل LDA، الگوریتم نزدیکترین همسایه(knn)، مدل LDA، Decision Tree و بیزین به عنوان مدل پایه استفاده کرده ایم و توضیح داده ایم که در چه شرایطی میتوانیم از مدلهای مختلف به عنوان مدل ضعیف (weak learner) این تکنیک استفاده کنیم. بعد از اینکه تمامی مباحث را آموزش دادیم، کدهای نوشته شده را به توابع تبدیل کرده و چندین پروژه عملی با کمک تکنیک آدابوست انجام دادیم تا با روند استفاده از تکنیک آدابوست در عمل آشنا شویم.
پروژه های انجام شده:
- تشخیص سرطان سینه با روش Adaboost (پروژه کلاسبندی – مسئله دو کلاسه)
- کلاسبندی نوع گل زنبق(iris) با روش Adaboost (پروژه کلاسبندی – مسئله 3 کلاسه)
جلسه پنجم-بخش 2: ترکیب شبکه عصبی ELM و ELM وزندار و تکنیک آدابوست
شبکه عصبی ELM یکی از شبکه های عصبی معروف است که به خاطر ساختار ساده ای که دارند زمان آموزش بسیار پایینی دارند و همچنین به خاطر همین ساختار ساده، خاصیت generalization خوبی دارند. ما در این جلسه آموزش میدهیم که چطور میتوان از شبکه عصبی ELM و ELM وزندار به عنوان weak learner تکنیک آدابوست استفاده کرد. ترکیب آدابوست و شبکه عصبی ELM یک مدل بسیار خوبی ارائه میدهد که عملکرد سیستم خیلی بالا می رود که میتوانیم در پروژه های عملی استفاده کنیم. مباحث آموزشی این جلسه طبق یک مقاله تخصصی آموزش داده شده است، تا با روال پیاده سازی مرحله به مرحله مقالات تخصصی آشنا شویم.
پروژه های انجام شده:- تشخیص سرطان سینه با روش ELM- Adaboost وWELM- Adaboost (پروژه کلاسبندی – مسئله دو کلاسه)
- کلاسبندی نوع گل زنبق(iris) با روش ELM- Adaboost وWELM- Adaboost (پروژه کلاسبندی – مسئله 3 کلاسه)
جلسه پنجم: بخش 3: پیاده سازی آدابوست در مسائل رگرسیون (AdaboostRT)
تعمیم تکنیک آدابوست برای مسائل رگرسیون به سادگی سایر تکنیکها نیست. ما در این جلسه طبق یک مقاله تخصصی یکی از روشهای مهم تعمیم آدابوست به مسائل رگرسیون، Adaboost.RT را آموزش می دهیم. در ابتدای جلسه تئوری این تکنیک را توضیح داده و سپس به صورت مرحله به مرحله در متلب پیاده سازی میکنیم و سپس برای اینکه بهتر با روند این تکنیک آشنا شویم، یک مثال بسیار ساده ای انجام می دهیم و به صورت شکلی روند کار را نشان می دهیم. سپس یک پروژه عملی با کمک این تکنیک انجام می دهیم تا متوجه بشویم که در چه شرایطی میتوانیم به صورت بهینه از این تکنیک در پروژه های عملی استفاده کنیم.
همانند روال همیشگیمون، در فصلهای قبلی در انتهای این جلسه توابع متلب مربوط به یادگیری جمعی را معرفی می کنیم و یک دو مثال ساده انجام میدهیم تا روند استفاده از توابع متلب هم آشنا شوید. هرچند ما به توابع متلب دیگر نیازی نداریم، چون ما تمامی این روشها و حتی بیشتر را خودمان در طول جلسات پیاده سازی کرده ایم.
نکته: مباحث این فصل بسیار مهم و کاربردی هستند که هر دانشجوی مهندسی بهتر است یاد بگیرد پس پیشنهاد میکنیم حتما این مباحث رو یاد بگیرید، مخصوصا دوستانی که میخواهند مقاله بنویسند و یا پایان نامه انجام بدهند، با کمک این ابزار قطعا عملکرد مدلتون بسیار بهتر خواهد شد!
مدت زمان دوره: 18 ساعت مدرس دوره: محمد نوری زاده چرلو فارغ التحصیل دانشگاه علم و صنعت تهران محتوای پکیج:
- ویدیوهای آموزشی
- کدهای پیاده سازی شده برای پروژه ها، تمرینات و مقالات
- منابع معتبری که برای تهیه ویدیو استفاده شده اند(کتب و مقالات مرجع)
- جزوه دست نویس مدرس
فصل 1-4 : از بیزین تا SVM
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)

3 دیدگاه برای شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
هما کاشفی (مالک تایید شده) –
سلام آقای نوری زاده
ویدیوی پردازش سیگنال تصور حرکتی شما را قبل تر تهیه کرده بودم و عالی بود و بسیار به من کمک کرد.
مباحث از پایه و دقیقاً از صفر تا صد آموزش داده شده بودند و فهمش خیلی ساده بود.
تنها ایرادش مدت زمان طولانی بعضی از ویدیوها بود.
تریلر این ویدیو هم دیدم بسیار بسیار عالی بود.
به سایر دوستان این ویدیوها (پترن و پردازش سیگنال تصور حرکتی) رو پیشنهاد میکنم
مطمئن باشند هزینه ای که بابت ویدیوها پرداخت می کنند در مقابل مهارتی که با دیدن ویدیوها کسب می کنند خیلی ناچیزه!
موفق و پایدار باشید.
mohammad_1369 –
سلام
ممنونم خانم کاشفی
خوشحالم که دوره براتون مفید بوده است.
موفق باشید
shaghayegh.qasemi (مالک تایید شده) –
سلام من محصول یادگیری جمعی شما رو تهیه کردم اما وقتی دانلود میکنم ارور میدهد؟ یعنی الکی پول دادم؟؟؟/
mohammad_1369 –
سلام
بعضی اوقات مشکل دانلود پیش میاد که برمی گرده به هاستینگ سراسری
ولی نگران نباشید تا یک ساعت دیگه این اختلال برطرف میشه
یک ایمیل در این خصوص براتون ارسال شد. لطفا بررسی کنید
موفق باشید
amirsajjad96 (مالک تایید شده) –
مثل همیشه عالی…
واقعاً مفید بودن، جز معدود آموزشای فارسی بودش که تونست این مفاهیم ماشین لرنینگ رو برام جا بندازه…
خداقوت