
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 1 دیدگاه
knn در بحث شناسایی الگو و یادگیری ماشین جزء الگوریتمهای غیرپارامتری است و از آن میتوان هم در مباحث طبقهبندی و هم رگرسیون استفاده کرد. در این فصل الگوریتم نزدیکترین همسایه knn و روشهای بهبود یافته شده آن (wknn) را آموزش میدهیم. در ابتدا knn را برای مسائل طبقهبندی آموزش میدهیم و سپس توضیح میدهیم که چطور از این الگوریتمها میتوان در مسائل رگرسیون استفاده کرد.
کلاسبندهای مبتنی بر نزدیکترین همسایهها(knn-wknn) یکی از کلاسبندهای معروف غیرپارامتری هستند و با یک رویکرد بسیار ساده و کارا از نمونههای همسایه برای دسته بندی داده جدید استفاده میکنند. این کلاسبندها پروسه آموزش ندارد و تنها دادههای آموزش را ذخیره کرده و از آنها برای دسته بندی همسایه ها استفاده می کند. به خاطر پیادهسازی ساده و همچنین عملکرد بالای این کلاسبند در اکثر پروژهها و مقالات استفاده میشود.
کلاسبندی نمونه ی جدید توسط نزدیکترین همسایه knn در سه مرحله انجام می شود. در ابتدا فاصله نمونه ی تست با تمام نمونههای آموزش محاسبه می شود، سپس طبق فاصله بدست آمده، k تا نزدیکترین همسایه از نمونه آموزش به نمونه تست پیدا شده و در مرحله سوم رای گیری انجام شده و لبیل نمونه تست با رای گیری مشخص می شود.
[caption id="attachment_13911" align="aligncenter" width="513"]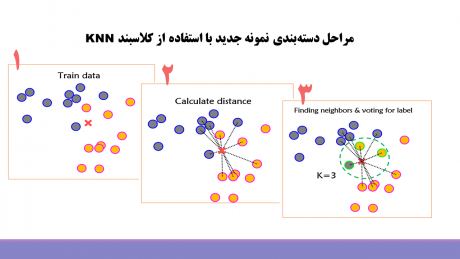 الگوریتم knn[/caption]
الگوریتم knn[/caption]
الگوریتم knn با اینکه عملکرد خیلی خوبی در اکثر کارها دارد، ولی یک سری ایرادات هم دارد و مهمترین ایراد آن حساس بودن به تعداد k هست. در این کلاسبند k توسط کاربر مشخص می شود و این کلاسبند برای k های مختلف تصمیمات مختلفی میتواند بگیرد و در نتیجه انتخاب k بهینه میتواند عملکرد مدل را بهبود دهد. همانطور که در شکل زیر مشاهده می کنید زمانی که عدد k کم باشد، کلاسبند ممکن است تحت تاثیر نمونه های نویزی و نمونههایی که درست لیبل گذاری نشده اند قرار بگیرد و تصمیم اشتباهی بگیرد، و یا اگر تعداد k زیاد انتخاب شود، تحث تاثیر نمونه های پرت، outliers، قرار بگیرد و تصمیم اشتباهی بگیرد.
در الگوریتم knn، تمام نمونه های همسایه در رای گیری سهم یکسانی دارد، این در حالی است که همسایه های نزدیک شباهت بسیار زیادی در مقایسه با همسایه های دور دارند! که الگوریتم knn این مسئله را در نظر نمی گیرد.
[caption id="attachment_13913" align="aligncenter" width="513"]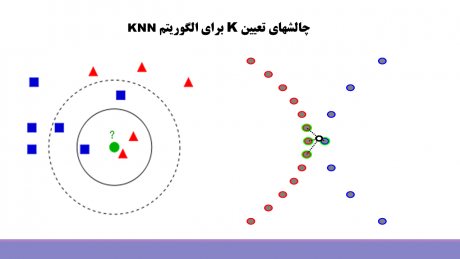 تعیین k بهینه برای knn[/caption]
تعیین k بهینه برای knn[/caption]
برای این منظور مقالات مختلفی ارائه شده اند تا بتوانند عملکرد knn را بهبود بدهند. در این الگورتیمهای ارئه شده به همسایههای نزدیک بسته به فاصله ای که به نمونه تست دارند، یک وزن مشخص می کنند که میزان رای آن را مشخص می کند. و به جای اینکه رای گیری ساده انجام بدهند، رای گیری وزندار انجام می دهند و همسایههای نزدیک سهم متفاوتی در رای گیری دارند. به الگوریتمهای ارائه شده به اصطلاح knn وزندار(weighted knn ) می گویند. در این روش ها همانند شکل زیر از روی فاصله همسایه ها یک وزنی برای هر همسایه مشخص می کنند. به همسایه های نزدیک وزن بیشتری تعلق می گیرد و به همسایه های دور وزن کمتری تعلق می گیرد و در نهایت رای گیری به صورت وزندار انجام می شود.
[caption id="attachment_13914" align="aligncenter" width="511"]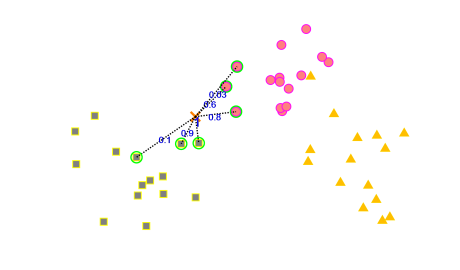 الگوریتم knn وزندار[/caption]
الگوریتم knn وزندار[/caption]
اینکه از روی فاصله چطوری به همسایه ها وزن داده شود، روشهای زیادی ارائه شده است که ما در این ویدیوی آموزشی سه تا مقاله معتبر انتخاب کرده ایم و نحوه وزندار کردن همسایه ها توسط این مقالات را توضیح داده و پیاده سازی کرده ایم. ما با دو هدف اینکار را انجام داده ایم، اول اینکه الگوریتم knn را بهبود بدهیم و دانشجویانی که پکیج رو تهیه می کنند، بتوانند از این الگوریتمهای بهبود یافته شده در پروژههای درسی و پایان نامه خود استفاده کنند، و هدف دوم ما این است که دوستان با نحوه پیاده سازی مقالات آشنا شوند و بتوانند همانند رویکرد آموزشی مدرس، مقالات تخصصی را پیاده سازی کنند.
ما در بخش اول فصل 4 که مربوط به پیاده سازی الگوریتمهای مبتنی بر نزدیک ترین همسایه هست، مباحث زیر را به ترتیب آموزش داده ایم:
- تئوری تصمیم گیری کلاسبندهای متبنی بر نزدیکترین همسایه(knn)
- پیادهسازی مرحله به مرحله کلاسبند knn
- معرفی تولباکس آماده متلب( برای آن دسته از دوستانی که میخواهند فقط با ابزار کار کنند)
- انجام یک مثال عملی بسیار ساده جهت آشنایی با عملکرد الگوریتم knn
- تئوری تصمیم گیری کلاسبند knn وزندار( wknn معرفی شده توسط دو مقاله اول که در جلسه دوم آموزش داده شده است)
- پیادهسازی مرحله به مرحله الگوریتم wknn ( پیاده سازی مقالات 1-2)
- انجام یک مثال عملی بسیار ساده جهت آشنایی با عملکرد الگوریتم wknn
- تئوری تصمیم گیری کلاسبند knn وزندار( wknn معرفی شده توسط سوم که در جلسه سوم آموزش داده شده است)
- پیادهسازی مرحله به مرحله الگوریتم wknn ( پیاده سازی بخش اول مقاله 3)
- انجام یک مثال عملی بسیار ساده جهت آشنایی با عملکرد الگوریتم wknn
- تئوری تصمیم گیری کلاسبند knn وزنداردوگانه (dwknn معرفی شده توسط سوم که در جلسه سوم آموزش داده شده است)
- پیادهسازی مرحله به مرحله الگوریتم dwknn( پیاده سازی بخش دوم مقاله 3)
- انجام یک مثال عملی بسیار ساده جهت آشنایی با عملکرد الگوریتم wknn
برای اینکه دوستان بتوانند با عملکرد این کلاسبندها پروژه های عملی آشنا شوند 3 پروژه تخصصی برای مسائل کلاسبند انتخاب کرده ایم و در متلب مرحله به مرحله با کمک این الگوریتمها پیاده سازی کرده ایم و چندین آزمایش هم برای ارزیابی عملکرد این کلاسبندهای مطرح کرده ایم.
پروژه هایی که در این ویدیوهای انجام داده ایم به صورت زیر است:
- تشخیص سرطان سینه با استفاده از کلاسبندهای knn، wknn و dwknn
- تشخیص نوع گل زنبق(iris) با استفاده از کلاسبندهای knn، wknn و dwknn
- تشخیص بیماری پارکیسنون از روی راه رفتن افراد با استفاده از کلاسبندهای knn، wknn و dwknn
آزمایشاتی که انجام داده ایم به صورت زیر است:
1- تعیین تعداد k بهینه برای کلاسبند knn
همانطور که صحبت کردیم، الگوریتم knn به تعداد k حساس است و میتواند به ازای هر kی عملکردهای متفاوتی داشته باشد، ما در این آزمایش نحوه انتخاب k بهینه در یک پروژه عملی را توضیح داده ایم.
2- تعیین معیار فاصله مناسب برای کلاسبند knn
همانطور که صحبت کردیم اولین مرحله الگوریتم های مبتنی بر نزدیکترین همسایه در مرحله اول فاصله نمونه های آموزش را با نمونه های تست محاسبه می کنند تا بر اساس این فاصله همسایه های نزدیک نمونه تست را پیدا کنند و با کمک این همسایه ها نمونه ی جدید را دسته بندی کنند.برای در هر پایگاه داده، معیار فاصله متفاوتی نیاز است. اگر ما از معیار مناسبی برای محاسبه فاصله استفاده نکنیم در نتیجه همسایه های اشتباهی پیدا خواهیم کرد و در نتیجه تصمیم اشتباهی الگوریتم خواهد گرفت.
معیار فاصله های مختلفی برای محاسبه فاصله وجود دارد که ما در این ویدیوها این معیار ها را معرفی کرده و در متلب پیاده سازی کرده ایم و رویکرد هر فاصله را هم توضیح داده ایم. معیار هایی که در ویدیوها پیاده سازی کرده ایم به صورت زیر است:
- فاصله اقلیدسی(euclidean)
- فاصله بلوک شهری( city block)
- فاصله چبیشف(chebychev)
- فاصله مینکوفسکی (minkowski)
- فاصله کسینوسی (cosine)
- فاصله همبستگی (correlation)
هدف ما از این آزمایش این بود که توضیح دهیم چطوری میتوان برای یک پایکاه داده معیار فاصله مناسبی انتخاب کرد.
3- بررسی عملکرد knn های وزندار
4- بررسی تاثیر k روی عملکرد knn و knnهای وزندار
[caption id="attachment_13915" align="aligncenter" width="457"]همانطور که صبحت کردیم عملکرد الگوریتم knn به تعداد k وابسته است و مخصوصا زمانی که تعداد نمونه های آموزشی کم باشد، عملکرد knn به شدت به تعداد k حساس است. ما در این آزمایش k های مختلفی را در نظر گرفته ایم و عملکرد تمام الگوریتمها را به ازای kهای مختلف بررسی کرده ایم تا نشان دهیم کدام الگوریتم به تعداد k وابسته نیست و میتواند به ازای kهای مختلف عملکرد مناسبی دارد. در شکل زیر نتیجه یکی از آزمایشات را نشان داده ایم.
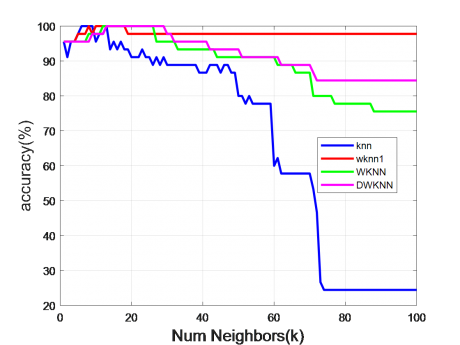 تاثیر تعداد همسایهها(k) در عمکرد knn و wknn[/caption]
تاثیر تعداد همسایهها(k) در عمکرد knn و wknn[/caption]
5- تاثیر نرمال کردن ویژگی ها بر روی عملکرد الگوریتمهای knn
ویژگی های مختلف رنج تغییرات متفاوتی دارند و از آنجا که الگوریتم knn فاصله نمونه ها را براساس این ویژگی های محاسبه می کند، زمانی که ویژگیها رنج تغییراتی متفاوتی داشته باشند، سهم یک سری ویژگی ها به خاطر رنج تغییراتی که دارند کم یا زیاد خواهد بود و در نتیجه ممکن است همین باعث شود همسایه های اشتباهی انتخاب شود. و در نتیجه الگوریتم تصمیم اشتباهی بگیرد. برای اینکه این اتفاق نیافتد ویژگی ها را نرمال می کنند تا همه در محاسبه فاصله سهم یکسانی داشته باشند و در نتیجه همسایه های درستی انتخاب شوند و در نتیجه آن الگوریتم به کمک این همسایه های تصمیم درستی بگیرد.
ما در این ویدیوهای آموزشی در یک بخش نحوه نرمال کردن ویژگی ها را توضیح داده ایم و اثر نرمالیزیشن را نشان داده ایم. همانطور که در شکل زیر می بینید قبل از نرمالیزیشن و بعد از نرمالیزشن همسایه های نمونه تست متفاوت هستند!
[caption id="attachment_13919" align="aligncenter" width="460"]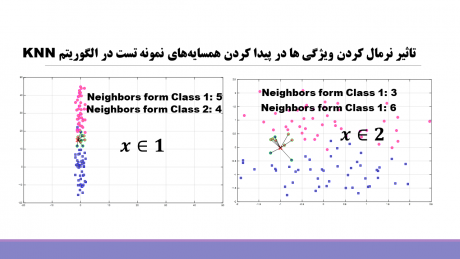 تاثیر نرمالیزیشن بر عملکرد knn[/caption]
تاثیر نرمالیزیشن بر عملکرد knn[/caption]
ما در آزمایشاتی که انجام داده ایم سعی کردیم به سوال اینکه آیا نرمالیزیشن همیشه تاثیر مثبتی دارد یا نه؟ به صورت عملی در پروژه های عملی جواب بدهیم.
انجام مسائل رگرسیون با الگوریتم knn
ما ذهنیتی که از الگوریتم knn داریم این است که این الگوریتم برای کارهای کلاسبندی استفاده می شود، این در حالی است که این الگوریتم یک کاربرد دیگه ای هم دارد، اون هم بحث رگرسیون(regression) هست. این الگوریتم با اینکه عملکرد خیلی خوبی در بحث های کلاسبندی دارد، در بحثهای رگرسیون هم هملکرد بسیار خوبی دارد.
ما در یک جلسه جدا به همراه یک پروژه علمی نحوه تبدیل knn کلاسبند به knn رگرسیون را آموزش داده ایم و نشان داده ایم که چطور میتوان knn و wknn را به سادگی تبدیل کرد برای بحث های رگرسیون.
مباحثی که در جلسه آخر آموزش داده ایم به صورت زیر است:
- فرق بین کلاسبندی و رگرسیون با یک مثال ساده
- تئوری تصمیم گیری knn در مسائل رگرسیون
- پیاده سازی knn برای مسائل رگرسیون
- تئوری تصمیم گیری wknnدر مسائل رگرسیون
- پیاده سازی wknnبرای مسائل رگرسیون
- انجام یک پروژه عملی رگرسیون (پیش بینی میزان آلودگی هوا با استفاده از الگوریتمهای knn و wknn)
- معایب knn
در شکل زیر خروجی تخمین زده شده با knn و خروجی واقعی نمایش داده شده است تا نشان دهیم که این الگوریتم تا چه اندازه عملکرد بهتری دارد.
[caption id="attachment_13916" align="aligncenter" width="483"]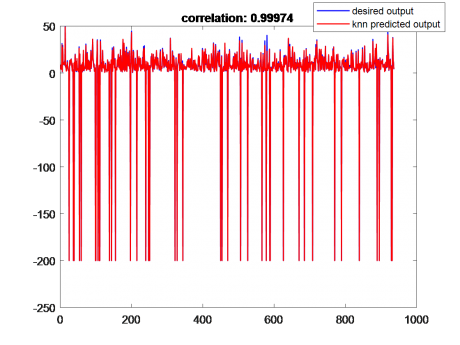 الگوریتم knn در مسائل رگرسیون[/caption]
الگوریتم knn در مسائل رگرسیون[/caption]
یک خبر خوب هم برای دوستان بدهیم و آن هم این است که برای هر پروژه ای که انجام شده یک گزارش کامل 20-30 صفحه ای در word نوشته و کنار کدها و ویدیوهای آموزشی قرار داده ایم تا دوستان بتوانند از این گزارشها در پروژه های درسی و پایان نامه خود استفاده کنند.
روال گزراش نویسی به صورت زیر است:
- چکیده
- مقدمه
- توضیح تئوری الگوریتمها
- توضیح خط به خط کدهای پیادهسازی شده برای الگوریتمها
- توضیح پایگاه داده
- جمع بندی و آزمایشات
ما در ویدیوهای تمام مباحث را صفر تاصد توضیح داده و پیاده سازی کرده ایم. علاوه بر این بخشها یک گزارش جدا هم برای هر پروژه نوشته ایم تا از آنها بتوانید در پروژههای درسی و پایان نامه خود استفاده کنید.
محتوای پکیج آموزشی:
- ویدیوی آموزشی تمامی جلسات
- کدهای متلب نوشته شده برای پروژه های انجام شده و جلسات آموزشی
- مقالات پیاده سازی شده و مراجع استفاده شده در آموزش
- گزارش پروژه های انجام شده در قالب Word و pdf
- جزوه دست نویس مدرس
تعداد جلسات: 8 مدت زمان آموزش:12ساعت مدرس: محمد نوری زاده چرلو
جهت دریافت پکیج آموزشی فصلهای 1-4 به صورت یکجا به لینک زیر مراجعه کنید.
پکیج جامع فصل های اول تا چهارم پترن و یادگیری ماشین( از بیزین تا SVM)
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

1 دیدگاه برای شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
narjes (مالک تایید شده) –
خیلی ممنونم از این آموزش خوبی که گذاشتین. برای من خیلی عالی و کاربردی بود.
مهتاب فرجی –
خواهش میکنیم
خوشحالیم که براتون مفید بوده