شناسایی الگو(فصل هشتم): خوشه بندی (clustering)
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 0 دیدگاه
در فصل خوشهبندی روشهای معروف خوشهبندی از قبیل (k-means، fuzzy c-means(fcm و Gaussian means (G-means) را طبق مقالات معتبر آموزش داده و مرحله به مرحله پیاده سازی کرده ایم. سپس برای اینکه با عملکرد الگوریتمها به صورت مفهومی آشنا شویم، چندین مثال ساده انجام داده ایم تا روند یادگیری این الگوریتمها را به صورت شکلی هم کنار کدنویسی نشان دهیم. بعد از اینکه الگوریتمها پیاده سازی شدند و درک بهتری از عملکرد این الگوریتمها پیدا کردیم چندین پروژه عملی انجام داده ایم تا با کاربرد این روشها در عمل آشنا شویم.
دوره تخصصی و جامع شناسایی الگو و یادگیری ماشین
فصل هشتم: خوشه بندی (clustering)
این فصل آخرین فصل دوره پترن و یادگیری ماشین هست که در آن روشهای خوشه بندی آموزش داده شده است. خوشه بندی جزء دسته یادگیری بدون ناظر از حوزه ای از یادگیری ماشین است که در آن خروجی(لیبل) داده وجود ندارد، و مدل خوشه بند خودش پترن نهفته داده را پیدا کرده و داده ها را براساس شباهتشان در خوشه های مختلف قرار میدهد.
مراحل خوشه بندی داده در شناسایی الگو به شکل زیر است:
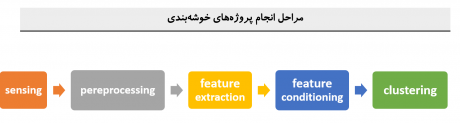
همانند روشهای یادگیری باناظر لازم است که از یک سری پردازشها از قبیل پیش پردازش، استخراج ویژگی و انتخاب ویژگی باد روی داده ورودی انجام شود. در مرحله آخر الگوریتم خوشه بند، داده ها را براساس شباهتشان(که بردار ویژگی آنها مشخص میکند) در خوشه های مختلف قرار میدهد.
ما در این فصل روشهای معروف خوشه بندی از قبیل (k-means، fuzzy c-means(fcm و Gaussian means (G-means) را طبق مقالات معتبر آموزش داده و مرحله به مرحله پیاده سازی کرده ایم. سپس برای اینکه با عملکرد الگوریتمها به صورت مفهومی آشنا شویم، چندین مثال ساده انجام داده ایم تا روند یادگیری این الگوریتمها را به صورت شکلی هم کنار کدنویسی نشان دهیم. بعد از اینکه الگوریتمها پیاده سازی شدند و درک بهتری از عملکرد این الگوریتمها پیدا کردیم چندین پروژه عملی انجام داده ایم تا با کاربرد این روشها در عمل آشنا شویم.
پروژه هایی که برای این فصل انتخاب کرده ایم به صورت زیر است:
- ناحیه بندی تصویر و استخراج تومور از تصاویر MRI مغزی(پروژه پردازش تصویر)
- ناحیه بندی تصویر براساس شدت روشنایی و رنگ پیکسلها (پروژه پردازش تصویر)
- خوشه بندی Spike های تولید شده توسط نورونهای مغزی- spike sorting (پروژه پردازش سیگنال- علوم اعصاب)
فهرست مطالب
جلسه اول: مقدمه ای بر خوشه بندی
در این جلسه کوتاه در مورد خوشه بندی صحبت کرده ایم و تفاوت آن با روشهای نظارت شده را توضیح داده ایم و در نهایت هم مراحل خوشه بندی و هدف الگوریتمهای خوشه بندی را توضیح داده ایم تا برای پیاده سازی روشهای خوشه بندی آماده شویم و با دید بهتری وارد جلسات بعدی شویم.
جلسه دوم: تئوری و پیاده سازی الگوریتم k-means
الگوریتم k-means یکی از معروفترین روشهای خوشه بندی است که با یک رویکردی بسیار ساده داده ها را خوشه بندی میکند. این روش یک روش تکراری هست و هدفش این است که در طول تکرارهای مختلف مراکز خوشه ها را پیدا کند و سپس داده ها را طبق مراکز خوشه بندی کند. در این روش تعداد خوشه ها توسط کاربر مشخص میشود، سپس این روش با یک سری رویکردهایی مراکز اولیه را مشخص کرده و بعد سعی به بهینه کردن مراکز میکند.
در این جلسه در ابتدا تئوری و رویکرد روش K-means را کامل توضیح داده ایم، سپس به صورت مرحله به مرحله این روش را پیاده سازی کرده ایم، سپس چندین مثال ساده انجام داده ایم تا به صورت عملی با عملکرد این روش آشنا شویم. سپس بعد از اینکه با رویکرد این روش آشنا شدیم و پیاده سازی کردیم، چندین پروژه عملی در حوزه پردازش تصویر و پردازش سیگنال انجام دادیم تا با کاربرد عملی این روش در عمل آشنا شویم.
الگوریتم k-means با اینکه یک روش بسیار کارایی هست و ولی یک ایراد اساسی دارد، و آن هم این است که این روش ممکن است در زمان پیدا کردن مراکز بهینه، در مینمم محلی گیر بکند و در نتیجه آن نتواند مراکز خوشه ها را به درستی پیدا کند و در نتیجه داده ها را به اشتباه خوشه بندی کند. یکی از دلایلی که باعث این اتفاق میشود این است که این روش به شدت به مقدار اولیه مراکز وابسته است، اگر مراکز اولیه خوشه ها به درستی انتخاب نشود، به احتمال بسیار زیاد این روش در مینیمم محلی گیر خواهد کرد، و اگر درست اتنخاب شود، همین باعث میشود که الگوریتم در مینمم محلی گیری نکند.
در شکل زیر نشان داده شده است که زمانی مراکز اولیه درست انتخاب نشود الگوریتم k-means در مینمم محلی گیر کرده و داده را به اشتباه خوشه بندی خواهد کرد.
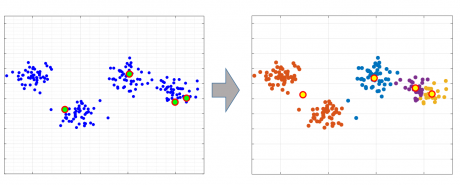
یکی از رویکردهای ساده ای که برای تعیین مراکز اولیه استفاده می کنند، انتخاب تصادفی مراکز اولیه از بین داده ها میباشد، و همین باعث می شود که در بعضی موارد مراکز اولیه خوب انتخاب نشوند و باعث شوند الگوریتم k-means در مینمم محلی گیر کند.
بهترین حالت این است که مزاکز اولیه طوری انتخاب شوند که به مراکز بهینه نزدیک باشند. ولی احتمال اینکه مراکز به صورت بهینه انتخاب شوند در زمانی که مراکز اولیه تصادفی انتخاب میشوند بسیار کم است.
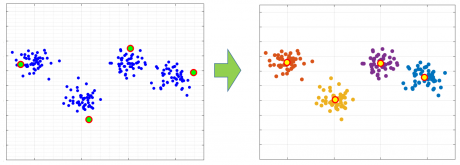
ما برای حل این مشکل یک رویکرد ابتکاری ارائه داده ایم که در آن مراکز طوری انتخاب می شوند که بیشترین فاصله را از هم داشته باشند، و همین باعث می شود که از هر خوشه یک نمونه به عنوان مرکز اولیه انتخاب شود و در نتیجه فاصله کمتری با مرکز نهایی آن خوشه داشته باشد، و باعث می شود که k-means مسیر هموارتری را برای پیدا کردن مراکز بهینه طی کند و در مینمم محلی گیر نکند. یا به عبارت دیگر احتمال اینکه k-means در مینمم محلی گیر کند بسیار کم می شود.
شکل زیر نتیجه انتخاب مراکز اولیه توسط رویکرد ابتکاری را نشان میدهد:
پروژه های انجام شده توسط k-means:
- ناحیه بندی تصویر و استخراج تومور از تصاویر MRI مغزی توسط k-means
- ناحیه بندی تصویر براساس شدت روشنایی و رنگ پیکسلها توسط k-means
- Spike sorting توسط k-means
جلسه سوم: تئوری و پیاده سازی الگوریتم (fuzzy c-means(fcm
یکی از ایرادهایی که الگوریتم k-means دارد این است که در مینمم محلی گیر میکند، هرچند ما سعی کردیم این مشکل را حل کنیم ولی باز ممکن است این اتفاق گاها پیش بیاید و الگوریتم k-means در مینمم محلی گیر کند. دلیل اصلی این اتفاق انتخاب مراکز اولیه خوشه ها هست که در جلسه قبل این مسئله را حل کردیم، دلیل دوم این است که این روش تنها براساس میانگین داده ها کار میکند و موقع خوشه بندی سایر اطلاعات را در نظر نمیگیرد.
الگوریتم fcm یجواریی همان k-means است منتها یک پارامتری به تابع هزینه k-means اضافه کرده است و همین باعث می شود مراکز خوشه ها به درستی انتخاب شوند و در مینمم محلی گیر نکند.
ایراد k-means این است که موقع محاسبه مراکز، هر نمونه را تنها میتواند به یک خوشه تعلق داشته باشد و در محاسبه مرکز آن خوشه سهیم باشد، ولی این در حالی هست که ممکن است یک سری نمونه هایی داشته باشیم که همزمان فاصله نزدیکی به چند خوشه داشته باشد و بهتر است به خوشه هایی که نزدیک هست سهمی بسته میزان فاصله ای که با مرکز آن خوشه دارد، داشته باشد. که این را k-means در نظر نمیگیرد.
الگوریتم fcm یک پارمتری به اسم تابع عضویت(membership function) به تابع هزینه k-means اضافه کرده است، و این باعث شده که موقع تنظیم مراکز در طول تکرارهای مختلف هر نمونه نقش متفاوتی در محاسبه تمامی مراکز داشته باشد. که میزان سهم نمونه را تابع عضویت(درجه عضویت]) آن نمونه به تک تک خوشه ها مشخص میکند.
الگوریتم fcm نیز همانند k-means یک روش تکراری هست و هدفش این است که در طول تکرارهای مختلف مراکز خوشه ها را پیدا کند و سپس داده ها را طبق مراکز خوشه بندی کند. البته در این روش علاوه بر مراکز، توابع عضویت نمونه ها هم در طول تکرارهای مختلف محاسبه میشود. سپس بعد از مشخص شدن مراکز خوشه و درجه عضویت نمونه ها، داده خوشه بندی می شود. در این روش نمونه ها به خوشه ای تعلق دارند که بیشترین درجه عضویت نسبت به آن خوشه داشته باشند.
در این جلسه در ابتدا تئوری و رویکرد روش fcm را کامل توضیح داده ایم، سپس به صورت مرحله به مرحله این روش را پیاده سازی کرده ایم، سپس چندین مثال ساده انجام داده ایم تا به صورت عملی با عملکرد این روش آشنا شویم. سپس بعد از اینکه با رویکرد این روش آشنا شدیم و پیاده سازی کردیم، چندین پروژه عملی در حوزه پردازش تصویر و پردازش سیگنال انجام دادیم تا با کاربرد عملی این روش در عمل آشنا شویم.
پروژه های انجام شده توسط fcm:
- ناحیه بندی تصویر و استخراج تومور از تصاویر MRI مغزی توسط fcm
- Spike sorting توسط fcm
جلسه چهارم: تئوری و پیاده سازی مقاله الگوریتم Gaussian means-Gmeans
یکی از ایرادهایی که الگوریتمهای k-means و fcm دارند این است که تعداد خوشه ها باید توسط کاربر مشخص شود!
مشکلی که اینجا وجود دارد این است که ممکن است تعداد ابعاد داده(تعداد ویژگیها) زیاد باشد و کاربر نتواند داده را در فضای دوبعدی یا سه بعدی رسم کند و تشخیص دهد که تعداد خوشه ها چقدر است. در نتیجه ممکن است به اشتباه تعداد خوشه ها را مشخص کند، و همین باعث میشود که الگوریتمهای k-means و fcm داده را به اشتباه خوشه بندی کنند. شکل زیر نتیجه انتخاب اشتباه تعداد خوشه ها را نشان میدهد!
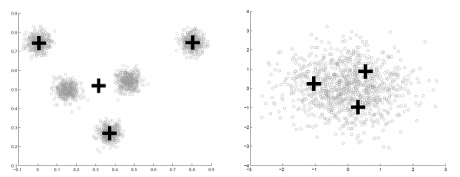
روشهای زیادی مطرح شده اند که سعی بر این دارند که تعداد خوشه ها را خودشان به صورت خودکار و بدون دخالت کاربر تعیین کنند.
الگوریتم G-means یکی از روشهای بسیار کارا هست و خودش با یک رویکرد بسیار جالب مشخص میکند که تعداد خوشه ها در یک داده چقدر است. برای همین ما در ادامه جلسات قبلی این روش را انتخاب کرده و آموزش داده ایم.
الگوریتم G-means یک روش تکراری هست و با یک سری مراکز شروع میکند و رفته رفته تا زمانی که نیاز باشد تعداد خوشه ها را زیاد میکند و در نهایت بعد از چندین تکرار تعداد مناسب خوشه ها را مشخص میکند.
ریکرد این روش در شکل زیر هم به صورت کلی نمایش داده شده است، این روش در هر تکرار نمونه های هر خوشه را بررسی میکند تا ببیند که آیا این نمونه ها از یک جمعیت هستند یا چند جمعیت. اگر از یک جمعیت باشند مرکز انتخاب شده برای آن نمونه ها مناسب است ولی اگر از یک جمعیت نباشند در این صورت به جای خود مرکز، فرزندان آن مرکز را در نظر میگیرد.
به عبارتی این روش در هر تکرار که داده ها را با یک تعداد مراکز که خوشه بندی میکند، بررسی میکند تا متوجه شود که آیا هر مرکز برای نمونه ها آن خوشه مناسب است یا نه. به عبارت دیگر تعداد مراکز مناسب است یا نه!
اگر مناسب باشد تعداد مراکز را زیاد نمیکند ولی اگر مناسب نباشد تعداد خوشه ها را زیاد میکند. وهمین روال را در هر تکرار ادامه میدهد تا متوجه شود که تعداد خوشه ها تعداد مناسبی برای خوشه بندی هست.
الگوریتم G-means برای اینکه متوجه شود نمونه های هر خوشه از یک جمعیت هستند یا نه، یا به عبارتی مرکز مورد نظر برای نمونه های آن خوشه مناسب است یا نه، داده را به فضای یک بعدی نگاشت میدهد و سپس با کمک تستهای آماری داده یک بعدی ساخته شده را بررسی میکند تا متوجه شود که داده مربوط به یک جمعیت هست یا نه! یا به عبارتی داده نگاشت یافته تک گوسی هست یا نه، اگر تک گوسی باشد به این معنی است که داده مربوط به یک جمعیت هست و یک مرکز مناسب است. ولی اگر تک گوسی نباشد به این معنی است که داده مربوط به یک جمعیت نیست و باید تعداد مراکز زیاد شود و برای افزایش تعداد مراکز، مرکز اولیه را با فرزندان آن مرکز که دو تا هستند جایگزین میکند.
از آنجا که ما تمامی روشهای ارائه شده در دوره را پیاده سازی میکنیم، و همچنین در طول دوره ها هم چندین مقاله تخصصی پیاده سازی کرده ایم، باعث شده که مهارت کافی برای پیاده سازی مقالات تخصصی داشته باشیم. این جلسه یک تمرینی برای ما هست تا یک مقاله تخصصی را مرحله به مرحله پیاده سازی کنیم.
در این جلسه علاوه بر اینکه یک روش جدید و کارا برای خوشه بندی یاد میگیریم، با نحوه پیاده سازی مرحله به مرحله مقاله هم آشنا می شویم. و متوجه میشویم که چقدر ساده میتوان یک مقاله را در عرض یکی دو ساعت پیاده سازی کرد.
برای پیاده سازی هر مقاله ای اول داشتن مهارت کدنویسی است، که ما این مهارت را در طول دوره بدست آورده ایم، دوم مهارت الگوریتم نویسی است که باید متوجه شویم چطور میشود یک مقاله را الگوریتم محور پیاده سازی کرد، باز به خاطر اینکه طول دوره کلا رویکرد آموزشی ما الگوریتم محور بوده و تمامی روشها را مرحله به مرحله پیاده سازی کرده ایم، این توانایی را هم داریم. و در نهایت لازم است که با یک سری تئوری های ریاضی و آماری آشنا باشیم که باز این دانش را در طول دوره بدست آورده ایم.
برای همین پیاده سازی مقاله برای دوستان onlinebme که در دروه های آقای محمد نوری زاده شرکت کرده اند، بسیار ساده خواهد بود.
پروژه های انجام شده توسط G-means:
- Spike sorting توسط G-means
محتوای پکیج:
- ویدیوهای آموزشی
- کدهای پیاده سازی شده برای پروژه ها، تمرینات و مقالات
- منابع معتبری که برای تهیه ویدیو استفاده شده اند(کتب و مقالات مرجع)
- جزوه دست نویس مدرس
فصل 1-4 : از بیزین تا SVM فصل 5: یادگیری جمعی(ensemble learning) فصل 6: تئوری و پیاده سازی روشهای کاهش بعد(PCA-LDA) فصل 7: تئوری و پیاده سازی روشهای انتخاب ویژگی
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)