
شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 0 دیدگاه
ماشین بردار پشتیبان(SVM) یکی از بهینه ترین الگوریتمها در مباحث طبقهبندی الگوها است و به خاطر ویژگی های برجستهای که مسئله ی بهینهسازی این الگوریتم دارد، باعث شده است که بهینهترین مرز ممکن بین دادههای دو کلاس را پیدا کند و همچنین به خاطر اینکه SVM در دادههای با ابعاد بالا (تعداد ویژگی های بسیار بالا) خیلی خوب کار میکند، باعث شده بین محققان یک الگوریتم بسیار محبوبی باشد و در اکثر پروژههای تخصصی از آن استفاده کند. در بخش اول این فصل شبکهی عصبی پرسپترون تک لایه و چندلایه را آموزش داده و در مسائل طبقهبندی و رگرسیون استفاده میکنیم. سپس به طور تخصصی تئوری و ریاضیات الگوریتم ماشین بردار پشتیبان را هم در مسائل طبقهبندی و هم در مسائل رگرسیون آموزش داده و سپس به صورت مرحله به مرحله پیاده سازی کرده و در پروژههای مختلف استفاده میکنیم.
محتوی آموزشی تئوری و پیاده سازی ماشین بردار پشتیبان(SVM)
پکیج آموزشی تئوری و پیاده سازی ماشین بردار پشتیبان(SVM)، شامل دو بخش عمده است. در بخش اول این پکیج، مرور کلی بر مباحث شبکه های عصبی مصنوعی و همچنین شبکه ی عصبی پرسپترون چندلایه انجام شده است و در بخش دوم،مباحث مربوط به ماشین بردار پشتیبان بصورت تئوری و عملی بیان شده است.
در فصل دو و بخش اول فصل چهارم از پکیج شناسایی الگو و یادگیری ماشین، کلاسبند بیزین و کلاسبند نزدیکترین همسایه(KNN) آموزش داده شده است. رویکرد دسته بندی این روش ها متفاوت با ماشین بردار پشتبان(SVM) هست، در مقابل، شبکه عصبی پرسپترون رویکردی نزدیک به ماشین بردار پشتیبان دارد و البته رویکرد آن نسبتا ساده تر است. از اینرو، در ابتدا مسائل کلاسبندی و رگرسیون با شبکه عصبی پرسپترون تک لایه و چندلایه انجام شده است. هدف اصلی این کار، آشنایی دانشجویان با عملکرد این بخشها و مسائل مختلف کلاسبندی و رگرسیون و همچنین مشکلات موجود در رویکرد یادگیری شبکه های عصبی است. در نهایت به معرفی و پیاده سازی SVM پرداخته ، و مقایسه ی آن با شبکه های عصبی بیان شده است.
مرور شبکه های عصبی در این پکیج، برای دوستانی که تاکنون پکیج شبکه های عصبی را تهیه نکرده اند، در فهم بیشتر ماشین بردار پشتیبان مفید خواهد بود. در صورت تمایل میتوانید پکیج کامل شبکه های عصبی را از این لینک تهیه فرمایید.
بخش اول: مروری بر شبکه های عصبی مصنوعی( باتمرکز بر روی شبکه ی عصبی MLP)
سرفصلها:
1- نورون و پرسپترون تک لایه 2- قانون یادگیری میانگین مربعات خطا 3- تفاوت رگرسیون با کلاسبندی و نحوه استفاده از شبکه عصبی در مسائل رگرسیون 4- شبکه عصبی پرسپترون چندلایه(MLP) 5،6- انجام پروژه های عملی کلاسبندی با استفاده از شبکه های عصبی 1. شخیص سرطان سینه با استفاده از شبکههای عصبی 2. کلاسبندی داده گل زنبق(IRIS) چندکلاسه با استفاده از از شبکههای عصبی 7،8- انجام پروژه های عملی رگرسیون با استفاده از شبکه های عصبی 1. تخمین میزان غلظت بنزن موجود در هوا با کمک شبکههای عصبی 2. تخمین زاویه مفصل مچ پا از روی سیگنال sEMG با کمک شبکههای عصبیبخش دوم: ماشین بردار پشتیبان (Support Vector Machine – SVM)
ماشین بردار پشتیبان(SVM) یکی از بهینه ترین الگوریتمها در مباحث کلاسبندی الگوها است و به خاطر ویژگی های برجستهای که مسئله ی بهینهسازی این الگوریتم دارد، باعث شده است که بهینهترین مرز ممکن بین دادههای دو کلاس را پیدا کند و همچنین به خاطر اینکه SVM در دادههای با ابعاد بالا (تعداد ویژگی های بسیار بالا) خیلی خوب کار میکند، باعث شده بین محققان یک الگوریتم بسیار محبوبی باشد و در اکثر پروژههای تخصصی از آن استفاده کند.
ابزار آماده برای SVM در اکثر محیطهای برنامه نویسی از قبیل متلب و پایتون وجود دارد و میتوان از آنها در پروژهها استفاده کرد. استفاده از ابزار آماده در پروژه ها ممکن است دو ایراد داشته باشد، ایراد اول این است که وقتی ما از یک ابزار آمادهای استفاده میکنیم احتمال اینکه دید تخصصی به این ابزار نداشته باشیم بسیار زیاد است و همین امر باعث میشود که به بهنیهترین شکل ممکن نتوانیم از این الگوریتم در پروژهها استفاده کنیم و نتوانیم نتایج بهینهای را بدست بیاوریم. ماشین بردار پشتیبان (SVM) یک ابزار بسیار قوی و کارامد است که اگر شناخت کافی به مسئله بهینهسازی این الگوریتم داشته باشیم، قطعا میتوانیم به بهینهترین شکل ممکن از این الگوریتم استفاده کنیم. پارامترهای آزاد این الگوریتم است که باید توسط کاربر مشخص شود، و این نیاز به شناخت دقیق از مسئله و داشتن دانش تخصصی در مورد SVM دارد.
ایراد دوم مسئله این است که وقتی از یک ابزار آماده استفاده میکنیم، باعث میشود که شناخت سطحی از الگوریتم داشته باشیم و همین باعث میشود که در هنگام تغییر زبان برنامه نویسی، نتوانیم از آن الگوریتم استفاده کنیم، و یا ممکن است در پیادهسازی مقالات جدید به مشکل بخوریم. در مقطع کارشناسی ارشد و دکتری همیشه سعی بر آن است که یک الگوریتم بهینهای در پایان نامه خود استفاده کنیم تا بتوانیم نتایج بهتری بدست آوریم و در نهایت یک مقاله خوب ارائه دهیم، برای اینکار دو روش وجود دارد، یا باید خودمان الگوریتمهای موجود را بهبود دهیم، و این نیازمند این است که به الگوریتم شناخت کافی داشته باشیم، مزایا و معایب الگوریتم را بشناسیم و سعی در بهبود عملکرد الگوریتم داشته باشیم و یا از مقالات ارائه شده در این زمینه کمک بگیریم، مقالاتی که توسط محققان دیگری برای بهبود الگوریتم نوشته شدهاند و پیادهسازی این مقالات نیاز به دانش تخصصی در مورد الگوریتم پایه دارد.
از اینرو در این بخش از پکیج پترن و یادگیری ماشیت، تمام مباحث تئوری مربوط به ماشین بردار پشتیبان( SVM) را مرحله به مرحله توضیح داده ایم به طوری که تمام مطالب مورد نیاز را پوشش داده شده است.. تمامی مباحث طبق مقالات مرجع ارائه شده توسط آقای Vapnik به صورت تخصصی و مرحله مرحله با مثال های عملی و بسیار ساده آموزش داده شدهاند تا دانشجو به صورت تخصصی و مفهومی با رویکرد ماشین بردار پشتیبان (SVM) آشنا شود. بعد از یادگیری تئوری مباحث، الگوریتم SVM به صورت مرحله به مرحله در متلب پیاده سازی شده است و سپس برای اینکه دانشجو ارتباط بهتری با رویکرد SVM برقرار کند، یک مثال عملی بسیار سادهای مطرح شده است، و مرز تصمیم گیری بدست آماده توسط SVM نمایش داده میشود. بعد از اینکه مباحث کامل آموزش داده شد، چندین پروژه ی عملی انجام میشود تا دانشجو با چالش واقعی انجام پروژه های تخصصی با الگوریتم SVM آشنا شود و بتواند از این دانش در پروژه های تخصصی خود استفاده کند.
در حین انجام پروژه آزمایشاتی طراحی و پیاده سازی شده است تا بتوانیم دانشجو را با تمام چالشهای موجود آشنا کنیم.توجه :کدهای نوشته شده برای تمامی پروژهها به همراه یک گزارش کامل در قالب فایل word و pdf که در آن توضیح خط به خط برنامه توضیح داده شده است، در کنار فایلهای آموزشی در اختیار دانشجو قرار میگیرد تا بتواند از این پروژه ها برای پروژه های درسی و پایان نامه خود استفاده کند.
سرفصلها:
1- مفاهیم اولیه مسائل بهینهسازی
1. مسئله بهینهسازی 2. بهینهسازی محدب 3. انواع مسائل بهینهسازی 4. فرق بین مسئله بهینه سازی مقید ( constraint optimization)و مسئله بهینه سازی نامقید (unconstrained optimization) 5. قضیه لاگرانژ و نحوه تبدیل مسئله بهینه سازی مقید به مسئله بهینه سازی نامقید 6. قضیه دوگان لاگرانژیمسئله بهینه سازی SVM یک مسئله مقید محدب است و نیاز است که دانشجو دید کافی در مورد این مفاهیم داشته باشد. در جلسه اول، مفاهیم پایه در مورد مسائل بهینهسازی آموزش داده میشود تا برای پیادهسازی ماشین بردار پشتیبان (svm) آمادگی لازم بدست آید.
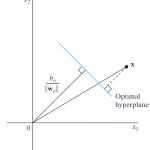
2- نحوه محاسبه فاصله یک نقطه از خط
ماشین بردار پشتیبان مرزی را پیدا میکند که در آن مرز تصمیم گیری بیشترین فاصله (Margin) با نزدیکترین نمونه های آن کلاس(بردارهای پشتیبان - Support Vectors) دارد. برای اینکه بتوانیم چنین مرزی پیدا کنیم لازم است که Margin را به فرم ریاضی در مسئله بهینه سازی بنویسیم تا بتوانیم پارامترهای بهینه مرز تصمیم گیری را پیدا کنیم. برای اینکار لازم است که دانشجو با نحوه محاسبه فاصله یک نقطه از خط آشنا باشد.
برای محاسبه فاصله یک نقطه از خط در بحث SVM رویکردهای مختلفی در مقالات ارائه شده است، در این جلسه سه روش معروف جهت محاسبه فاصله یک نقطه از خط را توضیح میدهیم تا بعد از یادگیری این جلسه، برای طراحی مسئله بهینهسازی SVM و پیادهسازی آن در مسائل کلاسبندی کاملا آماده شویم.
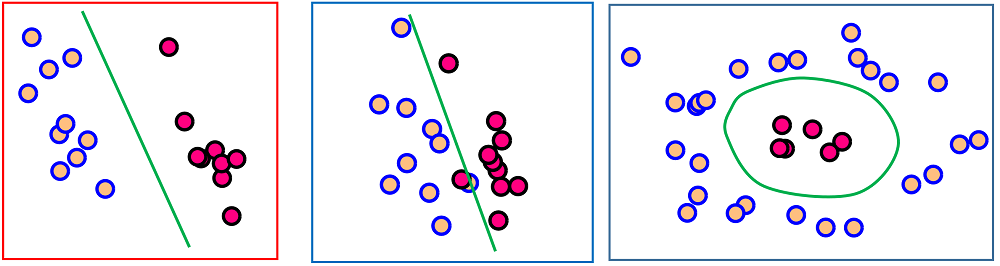
در مسائل کلاسبندی سه نوع مسئله کلاسبندی میتوان مطرح کرد که در زیر نمایش داده ایم:
ما در پیادهسازی SVM با سادهترین مسئله شروع میکنیم و رفته رفته مسئله را سخت تر و پیچیده تر میکنیم و در هر مسئله بررسی میکنیم که رویکرد آقای Vapnik در SVM به چه صورت هست. با این روش هم ارائه مطالب و هم درک مسائل سادهتر و راحت تر خواهد بود.
3- تئوری و پیاده سازی گام به گام hard-margin SVM در مسائل خطی تفکیک پذیر
در این جلسه با مباحث پایه و اساسی در مورد مسئله بهینه سازی SVM آشنا می شویم: 1. مسئله اصلی SVM 2. مسئله دوگان لاگرانژی SVM 3. Margin 4. قیدهای های تابع هزینه 5. بردارهای پشتیبان 6. مرز خطیداده خطی دو کلاسه تفکیک پذیر، داده ای که در آن بتوان داده های دو کلاس را با یک خط به صورت کامل جدا کرد و ساده ترین مسئله کلاسبندی است که در آن هدف پیدا کردن مرز خطی بهینه است. روشهای مختلف با رویکردی های متفاوتی مرز بهینه را پیدا کنند، همانند شکل زیر پرسپترون تک لایه و چند لایه و الگوریتم knn مرز بهینه ای را پیدا میکنند که خطای کلاسبندی را صفر کند.
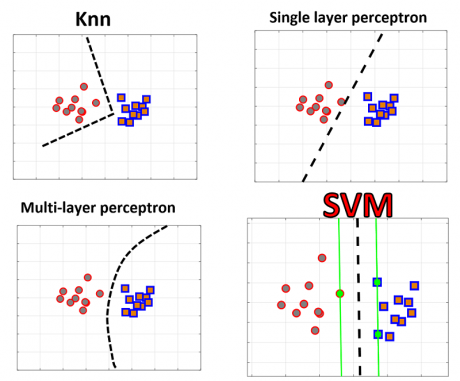
بین دادههای دو کلاس میتوان بی نهایت مرز میتوان پیدا کرد، اما بین تمام خطوط، خطی که از مرکز دادههای دو کلاس عبور میکند میتواند بهینهترین جواب ممکن باشد.
آقای Vapnik در ابتدا ایده اساسی SVM را در مسائل خطی تفکیک پذیر ارائه داده اند. در چنین مسائلی آقای Vapnik الگوریتمی ارائه میدهند که خطی انتخاب کند که بیشتری فاصله را از نزدیکترین نمونه های دو کلاس(بردارهای پشتیبان-support vectors) داشته باشد.
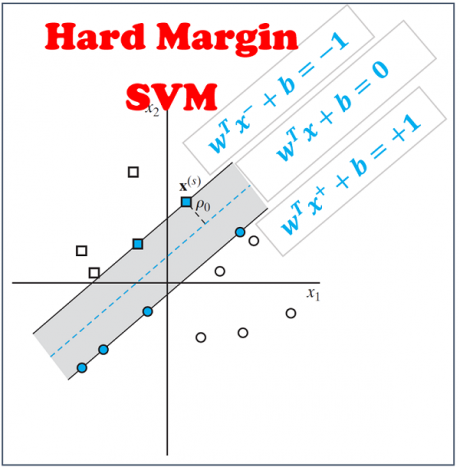
در این جلسه ایده اساسی و پایه SVM را در مسائل خطی تفکیکپذیر را آموزش میدهیم و بعد از آموزش مباحث تئوری ارائه شده توسط آقای Vapnik، ماشین بردار پشتیبان(SVM) را مرحله به مرحله در متلب پیادهسازی میکنیم و یک مثال عملی بسیار سادهای انجام میدهیم تا کاملا با علمکرد SVM آشنا شویم.
4- تئوری و پیاده سازی گام به گام soft-margin SVM در مسائل خطی تفکیک ناپذیر
همانطور که گفتیم، در جلسه سوم با ایده پایه و اساسی SVM مطرح میشود،این الگوریتم در میان الگوریتمهای موجود بهینهترین خط ممکن را پیدا میکند. با وجود اینکه، این الگوریتم رویکرد بسیار خوبی دارد، در دو حالت با مشکل مواجه میشود!
حالت اول: داده های آموزش داده کلاس کاملا تفکیک پذیر نباشند
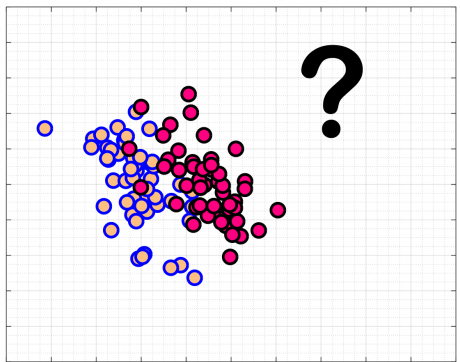 حالت دوم: نمونه های نویزی در داده های آموزشی وجود داشته باشد.
حالت دوم: نمونه های نویزی در داده های آموزشی وجود داشته باشد.
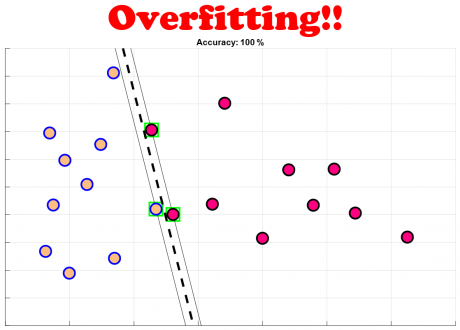
همانطور که در شکل بالا مشاهده می کنید، ایده اولیه آقای Vapnik نمیتواند مسئله ای که در آن داده های دو کلاس کاملا بصورت خطی تفکیک پذیر نیستند حل کند، و یا اگر داده ای که خطی است ولی نمونه ای نویزی در آن وجود دارد، باعث میشود که الگوریتم overfit شود و مرز مناسبی پیدا نکند!
در این جلسه مسئله ی دوم کلاس بندی را مطرح میکنیم، و میخواهیم شرایطی را بررسی که داده ها تا حدودی بصورت خطی تفکیک پذیر هستند، اما نه بصورت کاملا خطی. و در صورت استفاده از رویکرد قبلی، نتیجه ی کلاس بندی با مقدار اندکی خطا روبرو خواهد شد.مشکلی که ایده اولیه آقای Vapnik داشته است این بود که قیدهای مسئله بسیار شدید بودند، و زمانی که دادهها کاملا تفکیک پذیر نباشند الگوریتم fail میشود و نمیتواند مسئله بهینهسازی را حل کند. ایده آقای Vapnik برای حل این مسئله این بود که شدت قیدهای مسئله بهینهسازی =را کم کنند و یا به عبارت دیگر به مدل خود اجازه بدهند مقداری خطا داشته باشد.
در این جلسه توضیح میدهیم که آقای Vapnik برای حل چنین مشکلاتی چه رویکردی را ارائه داده اند. آقای Vapnik برای حل چنین مسائلی، متغیر مجازی (Slack Variable) معرفی کرده اند.
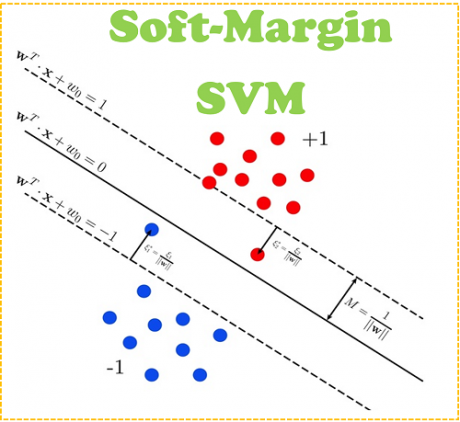
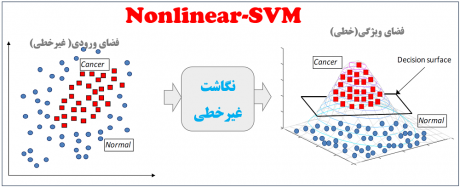
5- تئوری و پیاده سازی گام به گام nonlinear SVM در مسائل غیرخطی
در جلسات قبل یاد گرفتیم که چطور مرز خطی بهینه مناسبی برای حل مسائل خطی پیدا کنیم. ایدهای که آقای Vapnik ارائه کردند، در چنین مسائلی بسیار خوب عمل میکند. ولی سوال این است که اگر مرز تصمیمگیری بین دو کلاس غیرخطی باشد، چطور از رویکرد پایه SVM استفاده کنیم و مسئله را حل کنیم؟!
در این جلسه توضیح میدهیم که ایده آقای Vapnik برای حل چنین مسائلی چه بوده است و چطور مسائل غیرخطی را حل می کند.
ایده ای که آقای Vapnik برای حل چنین مسائلی استفاده کرده، این بوده است که در ابتدا باید داده را از فضای اصلی که یک فضای غیرخطی است، با کمک یک تبدیل غیرخطی، به یک فضای خطی نگاشت کنیم و سپس در چنین فضایی که ابعاد بالایی دارد، فوق صفحه بهینه را پیدا کنیم. در واقع با کمک ویژگی های موجود در فضای اصلی یک سری ویژگی هایی جدیدی می سازیم که با کمک این ویژگیهای ساخته شده فضایی میسازیم که داده های دو کلاس از هم به صورت خطی تفکیک پذیر شوند.
 برای انجام این کار دو تا سوال اساسی پیش می آید:
1. آیا چنین تبدیل غیرخطی وجود دارد که بتوان با کمک آن داده را از فضای غیرخطی به فضای خطی نگاشت داد؟
2. آیا در فضای جدید که ابعاد داده (تعداد ویژگی ها) بسیار زیاد است، مدل میتواند خوب کار کند و مرز بهینه را پیدا کند؟
برای انجام این کار دو تا سوال اساسی پیش می آید:
1. آیا چنین تبدیل غیرخطی وجود دارد که بتوان با کمک آن داده را از فضای غیرخطی به فضای خطی نگاشت داد؟
2. آیا در فضای جدید که ابعاد داده (تعداد ویژگی ها) بسیار زیاد است، مدل میتواند خوب کار کند و مرز بهینه را پیدا کند؟
برای جواب به سوال اول در ابتدای جلسه توضیح میدهیم که چطور میتوان داده را از فضای غیرخطی به فضای خطی نگاشت داد. همچنین از دو کرنل غیرخطی به اسم RBF (توابع شعاعی پایه- کرنل گوسی) و چندجمله ای (Polynomial) برای نگاشت داده استفاده کرده ایم و نشان میدهیم که چطور میتوان داده را از فضای غیرخطی به فضای خطی نگاشت داد.
بعد از اینکه تئوری مباحث مربوط به راهکار آقای Vapnik در مسائل غیرخطی را آموزش داده ایم، دو مثال بسیار ساده در متلب انجام داده ایم، و توضیح داده ایم که چطور میتوان در یک مسئله غیرخطی مرز تصمیم گیری بهینه را بدست آورد.
6- جمع بندی مباحث مربوط به SVM در مسائل دو کلاسه و معرفی توابع آماده متلب برای SVM
در این جلسه مباحث آموزش دیده را به صورت مختصر مرور میکنیم و بعد برای اینکه در انجام پروژه ها دوباره کدنویسی نکنیم و کدنویسیهای منظم داشته باشیم تا هم انجام پروژه ها به صورت بهینه باشد و هم debugging کدهای نوشته شده ساده تر باشد، کدهای نوشته شده را به توابع تبدیل میکنیم، تا از این به بعد در انجام پروژه ها کلا به دو تابع سر و کار داشته باشیم، یک تابع برای آموزش SVM و یک تابع برای تست SVM.
در انتهای جلسه، توابع آماده متلب برای SVM را در ورژنهای قدیم و جدید را توضیح داده ایم تا با نحوه استفاده از این توابع آماده نیز در متلب آشنا شویم. البته ما تمامی الگوریتم ها را در متلب پیاده سازی کرده ایم و نیازی به این توابع نداریم، ولی برای اینکه هم با این توابع آشنا شویم و هم مقایسه ای با الگوریتمهای خودمان انجام شود این توابع را معرفی کرده ایم.
7- نحوه تعمیم SVM دو کلاسه برای مسائل چندکلاسه
همانطور که در توضیح داده ایم، الگوریتم SVM برای مسائل کلاسبندی دو کلاسه ارائه شده است، و برای اینکه بتوانیم از این الگوریتم بهینه در مسائل چندکلاسه استفاده کنیم نیاز است که با یک روشی این الگوریتم را برای مسائل چندکلاسه تعمیم دهیم. برای اینکار دو رویکرد وجود دارد: 1- تغییر تابع هزینه و تعمیم آن به مسائل چند کلاسه، 2- از تکنیکهایی که از SVM دو کلاسه در مسائل چند کلاسه استفاده میکنند، استفاده کنیم.
نتایج و تحقیقات نشان داده اند که رویکرد اول در مقایسه با رویکرد دوم در پروژه های عملی عملکرد مناسبی ندارد! لذا ما به این قضیه نمیپردازیم و در این جلسه تکنیک های تعمیم SVM دو کلاسه برای مسائل چندکلاسه را توضیح میدهیم. به طور کلی از دو تکنیک میتوان SVM دو کلاسه را به مسائل چند کلاسه تعمیم داد.
1. تکنیک یکی در مقابل همه(one versus all / one versus rest) 2. تکنیک یکی در مقابل یکی (one versus one)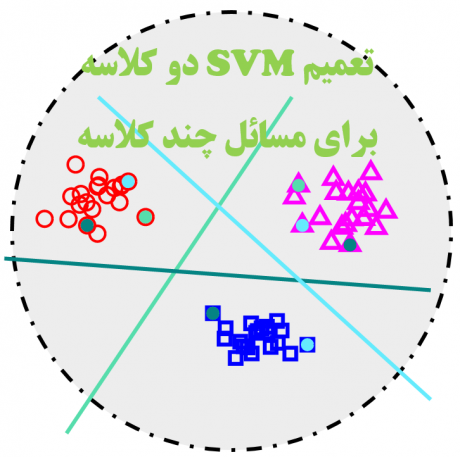
در هر دو تکنیک به جای اینکه از یک کلاسبند چندکلاسه استفاده کنند، از چندکلاسبند دو کلاسه برای حل مسئله چندکلاسه استفاده میکنند. منتها رویکرد استفاده از این کلاسبندهای دوکلاسه در دو تکینک متفاوت است. در تکنیک یکی در مقابل همه، به ازای هر کلاس یک SVM دو کلاسه استفاده میکنند که وظیفه آن جدا کردن داده های یک کلاس از بقیه کلاسها است. در تکنیک یکی در مقابل همه بعد از آموزش کلاسبندهای دو کلاسه، برای تخمین لیبل داده جدید، داده تست به ترتیب به تک تک کلاسبندها ارائه داده میشود، اگر کلاسبند اول نتوانست تشخیص دهد نمونه ورودی مربوط به کلاس 1 هست، به کلاسبند بعدی نمونه جدید ارائه میشود و به همین ترتیب ادامه می یابد.
همانطور که در شکل زیر پیدا است، این تکنیک دو مشکل اساسی دارد!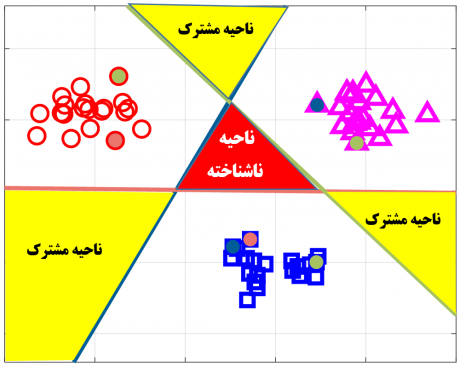 1. نواحی ناشناخته ای وجود دارد که کلاسبند ها نمیتوانند در مورد نمونه های قرار گرفته در این نواحی تصمیمی بگیرند!
2. نواحی ای وجود دارد که دو کلاسبند نظر یکسانی دارند و نیمتوان به قطعیت در مورد کلاس داده جدید تصمیم گرفت و در پروسه تست نتیجه کلاسبندی وابسته به ترتیب استفاده از کلاسبند ها وابسته است.
1. نواحی ناشناخته ای وجود دارد که کلاسبند ها نمیتوانند در مورد نمونه های قرار گرفته در این نواحی تصمیمی بگیرند!
2. نواحی ای وجود دارد که دو کلاسبند نظر یکسانی دارند و نیمتوان به قطعیت در مورد کلاس داده جدید تصمیم گرفت و در پروسه تست نتیجه کلاسبندی وابسته به ترتیب استفاده از کلاسبند ها وابسته است.
در تکنیک یکی در مقابل یکی از چندین کلاسبند دو کلاسه استفاده می شود که هر کلاسبند وظیفه اش این است که یک مسئله دو کلاسه را حل کند. بعد از اینکه این کلاسبندهای دو کلاسه آموزش داده شدند، داده تست به تمام کلاسبندهای دو کلاسه اعمال میشود و هر کدام یک تصمیمی میگیرند، در نهایت رای گیری صورت میگیرد و نمونه ی تست به کلاسی تعلق دارد که بیشترین رای را داشته باشد.
در این روش ناحیه ی ناشناخته ای وجود ندارد، نتیجه کلاسبندی به ترتیب فراخوانی کلاسبندها وابسته نیست، تنها ممکن است یک سری نواحی بسیار کوچکی ایجاد شود که نتوان به قطعیت در مورد نمونه جدید تصمیم گرفت! البته احتمال به وجود آمدن این مشکل در مسائل چندکلاسه با تعداد کلاس بالاتر بسیار کم است. چون تعداد کلاسبندهای دوکلاسه استفاده شده در این تکنیک زیاد است و هر چقدر تعداد کلاس افزایش یابد تعداد کلاسبند بیشتری استفاده خواهد شد و این باعث میشود که مشکل ذکر شده پیش نیاید.
تنها ایراد این تکنیک میتواند این باشد، که در مسائلی که تعداد کلاس زیاد است، تعداد کلاسبند به مراتبط بیشتری نسبت به تکنیک یکی در مقابل همه استفاده می شود و همین باعث می شود که زمان آموزش افزایش یابد.
جلسات 8 و 9: انجام پروژه های عملی کلاسبندی با استفاده از ماشین بردار پشتیبان(SVM)
1. تشخیص سرطان سینه با استفاده از ماشین بردار پشتیبان(SVM) 2. کلاسبندی داده گل زنبق(IRIS) چندکلاسه با استفاده از ماشین بردار پشتیبان(SVM)10. تعمیم SVM برای مسائل رگرسیون
در این جلسه توضیح میدهیم که چطور میتوان از الگوریتم SVM برای مسائل رگرسیون استفاده کرد، یا به عبارت دیگر در این جلسه تئوری و پیاده سازی الگوریتم Support Vector Regression را توضیح میدهیم.
الگوریتم SVM در مسائل کلاسبندی نشان داده است که یک الگوریتم بسیار بهینه ای است که عملکرد بسیار خوبی در پروژههای عملی دارد. هدف ما در این جلسه این است که بررسی کنیم که آیا روشی هست که بتوان با آن SVM را برای مسائل رگرسیون تعمیم داد و از آن در مسائل رگرسیون استفاده کرد؟! اگر بتوانیم چنین کاری بکنیم احتمال اینکه به یک الگوریتم بهینه ای برسیم که عملکرد مناسبی داشته باشد بسیار زیاد است..
همانطور که میدانیم خروجی رگرسیون یک مقدار پیوسته ای است و تعمیم SVM برای چنین مسائلی کار ساده و راحتی نیست! آقای Vapnik برای حل این مسئله نیز یک رویکرد بسیار جالبی ارائه داده اند و ما در این جلسه این رویکرد را توضیح میدهیم و چندین مثال ساده خطی و غیرخطی انجام میدیهم تا نشان دهیم که SVR چطور این مسائل را حل میکند.
جلسه 11 و 12: انجام پروژه های عملی رگرسیون با SVR
1. تخمین میزان غلظت بنزن موجود در هوا با کمک Support Vector Regression 2. تخمین زاویه مفصل مچ پا از روی سیگنال sEMG با کمک Support Vector Regression
2. تخمین زاویه مفصل مچ پا از روی سیگنال sEMG با کمک Support Vector Regression
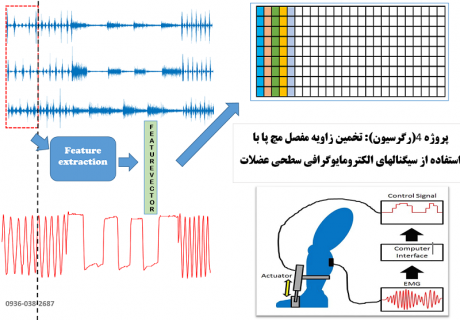
مرروی کوتاه بر پروژه های انجام شده با کمک svm:
محتوای پکیج آموزشی:
- ویدیوی آموزشی تمامی جلسات
- کدهای متلب نوشته شده برای پروژه های انجام شده و جلسات آموزشی
- مقالات پیاده سازی شده و مراجع استفاده شده در آموزش
- گزارش پروژه های انجام شده در قالب Word و pdf
- جزوه دست نویس مدرس
- مدت زمان آموزش:35 ساعت
جهت دریافت پکیج آموزشی فصلهای 1-4 به صورت یکجا به لینک زیر مراجعه کنید.
پکیج جامع فصل های اول تا چهارم پترن و یادگیری ماشین( از بیزین تا SVM)
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)
شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)
