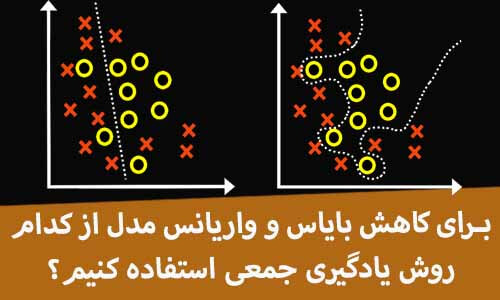
برای کاهش overfitting و underfitting کدام روش یادگیری جمعی استفاده کنیم؟
underfitting و overfitting مدل از چالشهای اساسی مهندسین در پروژه های یادگیری ماشین هست و همیشه سعی میکنیم به نوعی از overfit و یا underfit شدن مدل جلوگیری کنیم. در این بخش توضیح میدهیم که چطور میتوان با کمک تکنیکهای یادگیری جمعی بایاس و واریانس یک مدل را کاهش داد!
چالش آموزش الگوریتمهای یادگیری ماشین
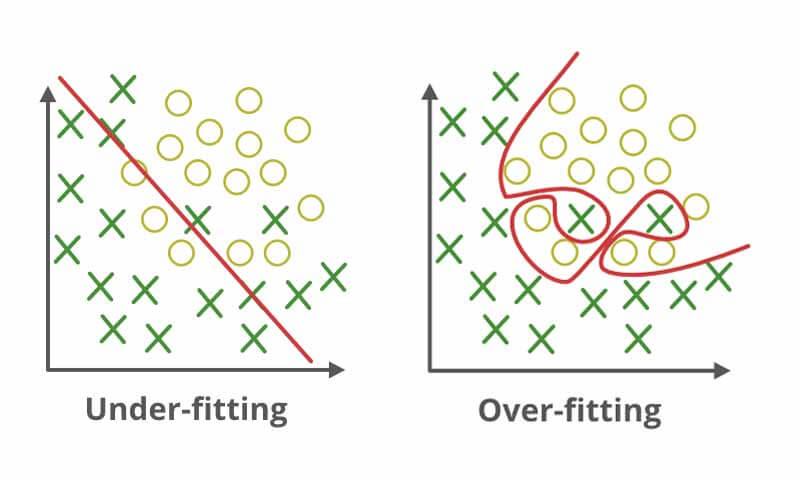
ما معمولا در پروژه های یادگیری ماشین وقتی از یک مدل برای حل مسئله استفاده میکنیم با دو تا چالش اساسی روبرو میشویم. ممکن است در پروسه آموزش مدل underfit یا overfit شود! که هیچ کدام خوب نیستند! وقتی یکی از اینها اتفاق بیافتد نتیجه اش این میشه که مدل مسئله رو به خوبی نمیتواند حل کند. بحث underfitting و overfitting مرتبط است به بایاس و واریانس مدل!
بایاس مدل
بایاس میزان خطای مدل را مشخص میکند. به عبارتی میزان اختلاف بین خروجی واقعی و خروجی تخمین زده شده توسط مدل را مشخص میکند. هرچقدر بایاس مدل زیاد باشه معنیش اینه که خطاش زیاد است و هرچقدر کمتر یعنی میزان خطا کمتر است. وقتی مدل underfit بشود، بایاس مدل افزایش می یابد. اصطلاح underfitting را زمانی به کار میبریم که مدل به خوبی نتواند یاد بگیرد. ممکن است مدلی که برای حل مسئله استفاده کردهایم، توان حل مسئله را نداشته باشد. مثلا مرز دادهها غیرخطی است ولی ما از یک مدل ساده که میتواند مرز خطی پیدا کند استفاده کنیم.
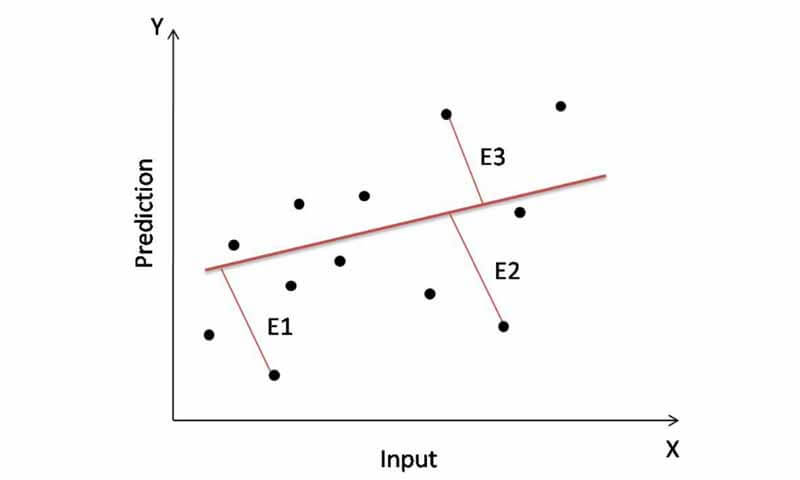
در مثال رگرسیون بالا، نشان داده شده است که بایاس مدل استفاده شده زیاد است. به این دلیل که رابطه بین ورودی و خروجی غیرخطی است، ولی مدلی که استفاده کرده ایم خطی است و توان حل یک مسئله غیرخطی را ندارد. در نتیجه خروجی تخمین زده شده توسط این مدل خروجی مناسبی نیست و با مقادیر واقعی اختلاف زیادی دارد. در چنین شرایطی میگوییم بایاس مدل زیاد است. مدلی که برای حل این مسئله استفاده شده است یک مدل ضعیف یا به عبارتی weak-learner است.
یادگیرنده ضعیف (weak learner)
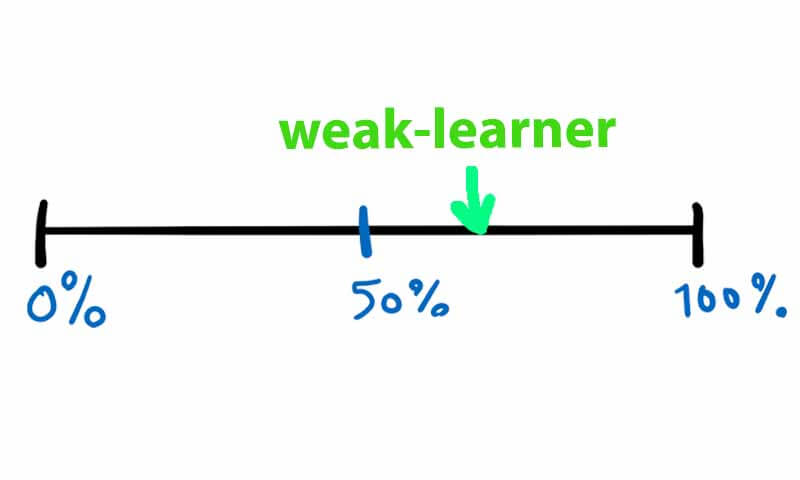
weak-learner به مدلی گفته میشود، که دقت آن یک مقدار بیشتر از سطح شانسی باشد. برای مثال در یک مسئله طبقهبندی دو کلاسه، اگر طبقه بند دقتی بین 55 تا 60 داشته باشد، یک weak-leaner محسوب میشود.
لزوما همه مدلهای خطی یک weak-leaner نیستند! مسئله مشخص میکند که یک مدل ضعیف باشد یا قوی. ممکنه یک مدل غیرخطی هم در مقابل بعضی مسائل یک weak-leaner حساب شود.
واریانس مدل
مطمئنا تاحالا برای خیلی از دوستان پیش اومده است که یک پروژه ای انجام داده باشند که در آن دقت در پروسه آموزش یک عدد خیلی خوبی شده باشد ولی وقتی داده جدید استفاده کردند یهو دقت به طرز عجیبی پایین اومده باشد!

در چنین حالتهایی می گوییم مدل overfit شده است یا به عبارتی واریانس مدل خیلی افزایش یافته است! یعنی اختلاف بین دقت آموزش و تست خیلی زیاد بوده است.
واریانس کم یعنی اختلاف بین دقت آموزش و تست کم است و واریانس زیاد یعنی اختلاف بین دقت آموزش و تست زیاد است.
Overfitting
Overfitting در مدلهای غیرخطی از قبیل درخت تصمیم، شبکه های عصبی رخ میدهد. یک مسئله پیچیده داریم و از یک مدل غیرخطی برای حل آن استفاده می کنیم. ممکن است مدل فیت بشود روی داده و در نتیجه واریانسش افزایش یابد.
در شکل زیر مدل روی داده overfit شده و دقت خیلی خوبی برای داده آموزش دارد! ولی برای داده های جدید اصلا خوب عمل نخواهد کرد!
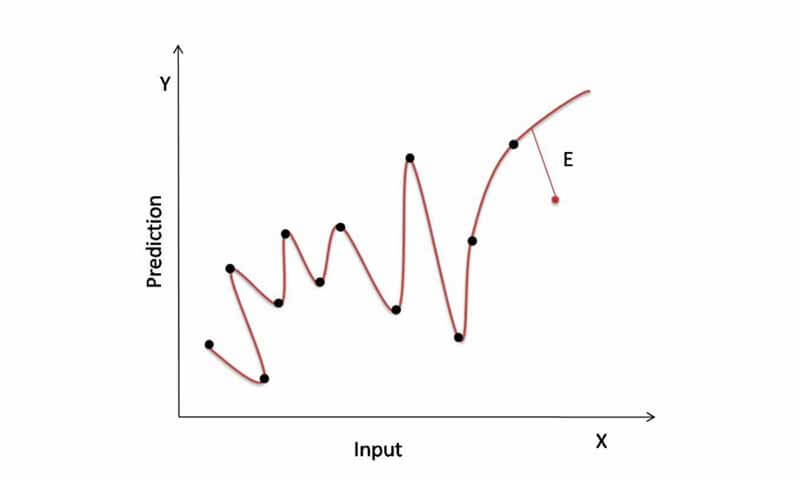
برای کاهش واریانس مدل از چه روش یادگیری جمعی استفاده کنیم؟
برای کاهش واریانس از روش bagging استفاده میکنند. در تکنیک bagging برای کاهش واریانس مدل، به جای یک مدل از چندین مدل همزمان(برای مثال به جای یک طبقه بند درختی، از چندین طبقه بند درختی استفاده می شود) استفاده میشود.
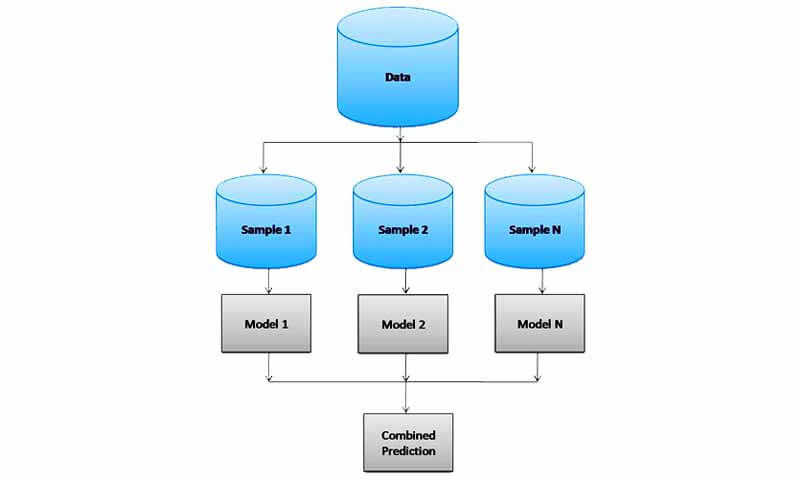
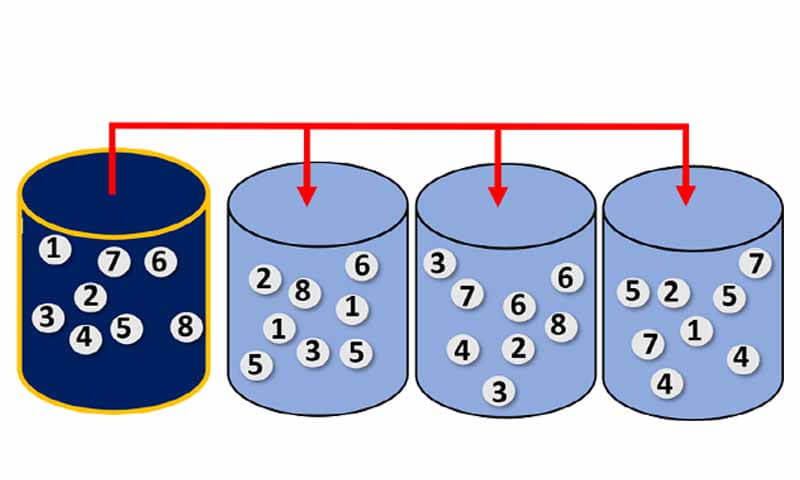
در این روش با تکنیک bootstrap داده را به چندین زیر مجموعه تقسیم میکنند و سپس هر کدام از مدلها را با یکی از زیرمجموعه ها آموزش می دهند. در تکنیک bootstrap در داده زیر مجموعه ممکن است یک داده چندین بار تکرار شود.
بعد از آموزش مدلها aggregating انجام می شود یا به عبارتی مدلها باهم ترکیب می شوند تا خروجی داده جدید را تخمین بزنند. همه مدلها در این تکنیک جنس یکسانی دارند ولی از از آنجا که هر کدام با داده متفاوتی آموزش دیده اند در نتیجه برای داده جدید تصمیم متفاوتی میتوانند بگیرند.
بعد از اینکه هر مدل خروجی داده جدید را تخمین زد، رای گیری اتفاق می افتد . برای مثال در مسائل طبقه بندی داده جدید به کلاسی تعلق دارد که بیشترین رای را نسبت به آن کلاس داشته باشد.
این رویکرد زمانی میتواند خوب عمل کند که مدل پایه پتانسیل overfitting داشته باشد!
برای کاهش بایاس مدل از چه روش یادگیری جمعی استفاده کنیم؟
روشهای boosting برای تقویت weak-learner ها استفاده میشوند. به همین خاطر میتوان از boosting برای کاهش بایاس استفاده کرد.
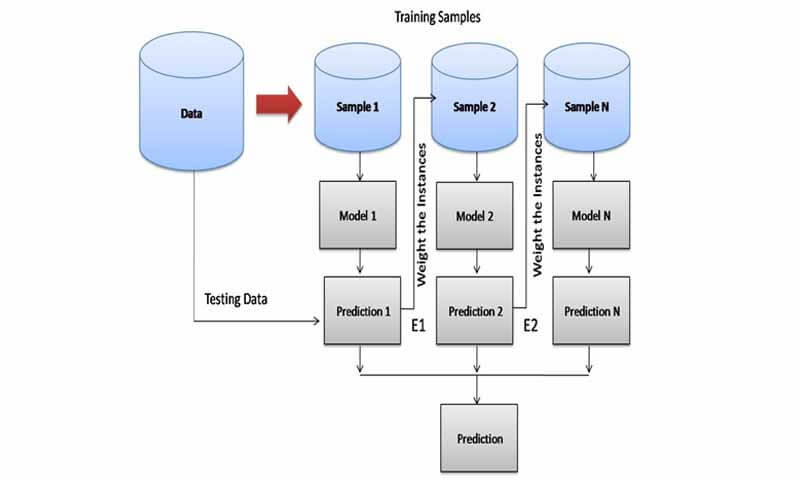
در این روش نیز جنس همه مدلها باید یکی باشد. ولی برخلاف bagging ، در این روش مدل پایه باید یک weak-learner باشد. در غیر انصورت نتیجه عکس خواهید دید! به جای تقویت تعضیف رخ میدهد! عجیبه ولی همینی که هست!
یعنی اگر یک مدلی دقتش 90 درصد باشه، و بخواهیم با boosting تقویتش کنیم، انتظار اینو نداشته باشید که دقت خوب میشه! ممکنه دقت برسه به 60! به قول آقای مدیری، دیدم که میگم…
خب یعنی نمیشه از یادگیری جمعی در چنین شرایطی برای افزایش دقت استفاده کرد! چرا نمیشه! از تکینک voting یا stacking برای چنین حالتهایی استفاده میکنیم! در پست بعدی این روشها را توضیح خواهیم داد.
حالا تکنیک boosting چطور مدلها را تقویت میکند! در این رویکرد از چندین مدل ضعیف همزمان استفاده می شود و یک مسئله پیچده حل میشود. در این تکنیک هر مدل یک بخش مسئله را حل میکند. و وقتی کنارهم قرار میگیرند کل مسئله حل میشود.
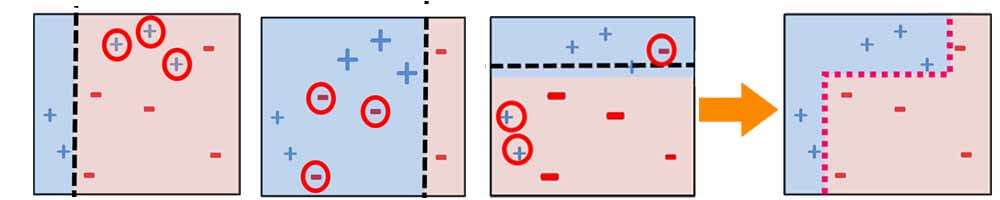
روال به این شکل است که در ابتدا یک مدل ضعیف آموزش دیده و تست می شود. مدل اول قطعا یک تعداد از نمونه ها را به اشتباه دسته بندی خواهد کرد! نمونه هایی که اشتباه دسته بندی شده اند، برجسته تر میشوند، به عبارتی وزن بیشتری میگیرند. تا مدل بعدی حواسش به اونا باشه و سعی کنه اونارو حل درست دسته بندی کنه!
در این رویکرد برخلاف bagging، مدلهای پایه به صورت ترتیبی آموزش میبینند. هر مدلی که آموزش میبیند هدفش این است که ایرادات مدلهای قبل از خودش رو برطرف کنه! و ایده بسیار خوبی هست و با این روال یک مسئله بسیار پیچیده را به چندین مدل بسیار ساده حل میکند! در مسئله رگرسیون هم همین روال هست.
اگه علاقه مند این مباحث هستید فصل یادگیری جمعی دوره جامع شناسایی الگو-یادگیری ماشین را نگاه کنید.به طور مفصل به این مباحث پرداخته ایم و علاوه بر پیادهسازی تمامی تکینکیها، چندین پروژه عملی رگرسیون و طبقهبندی انجام داده ایم.
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

[…] تفاوت این دو تکنیک boosting و bagging قبلا آشنا شده ایم و به طور مفصل این مسئله را بررسی […]
[…] در پروژه شما به چه چیزی ربط دارد؟ واریانس بالای مدل یا بایاس بالای مدل!؟؟ به عبارت دیگر مشکل شما overfitting مدل هست یا […]
مرسی تموزش خیای خوبی بود
ممنون از لطف شما