
چطور با داده نامتعادل در آموزش مدلهای یادگیری ماشین مقابله کنیم؟
وقتی یک دادهای دارید که تعداد نمونههای گروهها خیلی متفاوت هستند، یا به اصطلاح یک داده نامتعادل دارید، دقت کلاسبندی به تنهایی به هیچ عنوان نمیتواند پارامتر مناسبی برای ارزیابی باشد. در این حالت بهترین کار اینه که سایر پارامترهای ارزیابی هست. بهترین معیار برای ارزیابی ماتریس کانفیوژن هست تا مشخص کنه که دادههای هر کلاس به چه صورت دستهبندی شدهاند. در چنین شرایطی بهتر است دقت طبقهبندی هر گروه به طور جدا محاسبه شود تا متوجه شویم که دادههای همه کلاسها تا حد خوب دستهبندی شدهاند.
احتمالا تا حالا براتون پیش اومده که یه پروژهای انجام داده باشین و دقت مدل 90 درصد بدست بیاد و بعد کلی خوشحال شدین که به به چه پروژه ای شد! بعد که یه مقدار بیشتر بررسی کردید متوجه شدین که 90 درصد دادهها مربوط به یک کلاس هست! این یک مثال از داده نامتعادل هست.
در این بخش میخواهیم چندین تـکنیک ساده برای مقابله با داده نامتعادل در آموزش الگوریتمهای یادگیری ماشین را توضیح دهیم.
داده نامتعادل(imbalance data) چیست؟
داده نامتعادل به طور ساده برمیگرده به مسائل طبقه بندی که در آنها داده های گروهها به طور یکسان نباشد. برای مثال در یک مسئله دو کلاسه، 100 تا نمونه داشته باشید که 80 تا از این نمونه های مربوط به کلاس یک و 20 تا مربوط به کلاس دو باشد. در چنین حالتی شما یک پایگاه داده نامتعادل دارید که در آن تعداد نمونههای کلاس یک 4 برابر کلاس دو هست! به عبارتی نسبت داده های کلاس یک به دو 80:20 یا 4:1 هست. در مسائل چند کلاسه هم همین روال هست. در ادامه برای سادگی توضیحات مسئله را دو کلاسه در نظر میگیرم.
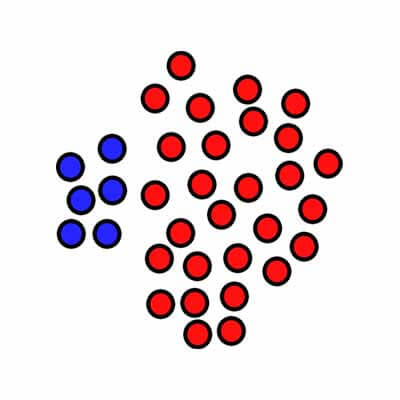
داشتن داده نامتعادل یک چیز رایج هست و در اکثر پروژهها تعداد دادههای گروه دقیقا یکسان نیست و معمولا در گروهها یک اختلافی وجود دارد. اگر این اختلاف خیلی کم باشد مشکل ساز نیست و اهمیتی ندارد. ولی اگر این اختلاف خیلی زیاد باشد مسئله ساز میشود!
پارادوکس دقت طبقه بندی
وقتی شما یک داده ی نامتعادل داشته باشید و مدل همه دادهها را به کلاسی که بیشترین نمونه دارد دستهبندی کند دقت خیلی خوبی بدست میآید ولی توجه کنیم که اینجا دقت توزیع دادهها در کلاسها را نشان میدهد تا اینکه مدل را ارزیابی کند!
وقتی با داده نامتعادل یک مدل یادگیری ماشین را آموزش میدهیم چه اتفاقی در مدل رخ میدهد؟
همانطور که حدس زدهاید، دلیل اینکه ما در یک داده نامتعادل(90 درصد از دادهها مربوط به کلاس یک باشد) به دقت 90 درصد رسیدهایم این است که مدل در پروسه آموزش به داده نگاه کرده و یک تصمیم هوشمندانه گرفته است و تمام دادههای ارائه شده را به کلاس یک دستهبندی کرده تا به دقت بالایی دست یابد! این مدل در عمل در اکثر مواقع نمونهها را به کلاس یک دستهبندی خواهد کرد!
چطور با داده های نامتعادل در پروسه آموزش مدلهای یادگیری ماشین مقابله کنیم؟
حال که متوجه شدیم داده نامتعادل چی هست و چه اتفاقی برای مدلهای یادگیری ماشین میافتد. بیایید ببینیم چجوری میشه با این مشکل مقابله کرد.
داده بیشتری جمع آوری کنید
آیا میتونید داده بیشتری جمعآوری کنید؟ سوالی هست که ممکنه خیلیها رو عصبانی کنه! خب واقعیت اینه که در خیلی از موارد نمیشه دادهی بیشتری ثبت کرد. تو ایران که اصلا حرفشو نزنید! همینی هم که داریم باید خداروشکر کنیم!
ولی خب بهتره یک تاملی بکنید و ببینید راهی برای جمعآوری داده بیشتری وجود داره یا نه. اگر بتونید داده بیشتری برای گروهی که نمونهی کمتری داره ثبت کنید مشکل داده نامتعادل حل می شود!
از معیارهای دیگری برای ارزیابی مناسب مدل استفاده کنید
وقتی با یک داده نامتعادل روبرو هستیم دقت طبقهبندی معیار مناسبی برای ارزیابی نیست! بلکه گمراه کننده هم هست!

این تصویر گویای خیلی از سوتیهای ما در پروژهها است. در دورهها یه مثال همیشه برای دوستان میزنم ولی گاهی پیش میاد که دوباره برخی دچار همین اشتباه میشوند. یادمه یبار یه بنده خدایی یک پروژه ی انجام داده بود، که تعداد دادههای دو کلاس خیلی نامتعادل بودند. کلاس یک حدودا 20 نمونه و کلاس دو بیشتر از 300 نمونه داشت. از قضا مدلی که استفاده کرده بود هر داده ای بهش میدادن میگفت کلاس دو. یعنی در بین 320نمونه 300 تا نمونه رو به درستی و 20 نمونه رو به اشتباه دستهبندی میکرد. خلاصه دقت کارش شده بود حدودا 95 درصد! دقت بدست اومده خیلی خوب به نظر میومد بود و نشان میداد که روش خیلی خوبی ارائه دادهاند. ولی واقعیت این بود که مدل این دوستمون عملا هیچ کاری نمیکرد و اصلا یاد نگرفته بود که بشه تو عمل استفاده کرد! کاری نداریم به ادامه ماجرا! شما حواستون باشه به این نکته! شاید دفاع پایاننامه رو بخیر بگذرونید که بعید میدونم که داورا متوجه این سوتی نشوند ولی به هیچ عنوان در یک مجله معتبر داورا همچین چیزی رو قبول کنند!
وقتی یک داده ای دارید که تعداد نمونههای کلاس خیلی متفاوت هستند، یا به اصطلاح یک داده نامتعادل دارید، دقت کلاسبندی به تنهایی به هیچ عنوان نمیتواند معیار مناسبی برای ارزیابی باشد. در این حالت بهترین کار اینه که از سایر پارامترهای ارزیابی استفاده کنید. بهترین معیار برای ارزیابی محاسبه ماتریس کانفیوژن هست . ماتریس کانفیوژن اطلاعات کاملی از نتایج طبقهبندی ارائه میدهد و با مشاهده آن میتوان متوجه شد که نمونههای هر کلاس به چه صورت دستهبندی شده اند! بهتر است دقت کلاسبندی هر گروه به طور جدا محاسبه شود. تا متوجه شویم که داده های همه کلاس تا حد خوب دستهبندی شدهاند. پارامترهای مثل rcall ,F1 score , kappa و ROC curve برای ارزیابی مناسب هستند و میتوان با کمک این پارمترها مدل را شرایط داده نامتعادل به درستی ارزیابی کرد.
پایگاه داده را کم یا زیاد کنید! (resampling dataset)
می توانید پایگاه داده را برای آموزش مدل تغییر دهید تا پایگاه داده متعادلی ایجاد شود و مشکل فیت شدن مدل روی یک کلاس برطرف شود! به این تغییر resampling یا همان نمونهبرداری گفته میشود و دو روش برای نمونهبرداری وجود دارد:
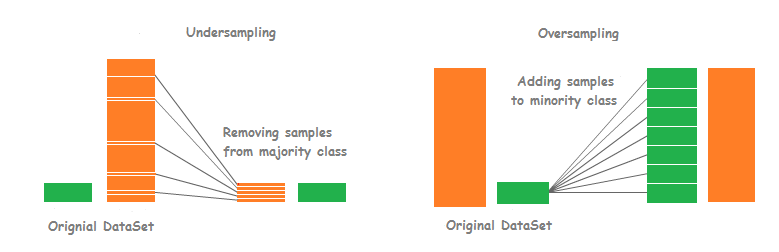
- دادههای گروهی که کمتر هست را کپی کنید و کنار هم قرار دهید! به عبارتی over-sampling انجام دهید و تعداد نمونههای گروهی که کمتر هست را بیشتر بکنید!
- تعدادی از دادههای گروهی که بیشتر هست را حذف کنید. به عبارتی under-sampling انجام دهید و تعداد نمونههای گروهی که بیشتر هست را کم کنید و برابر با تعداد نمونههای گروه کمتر می کنید!
هر دو رویکرد بسیار ساده و سریع هستند و برای شروع گزینه خیلی خوبی هست! پیشنهاد من اینه که هر دو روش رو امتحان کنید و ببنید چه اتفاقی میافته.
چند نکته ساده سرانگشتی:
- اگر دادهی خیلی زیادی (مثلا تعداد نمونهها بیشتر از 500 یا 1000 هست) دارید گزینه under-sampling رو در نظر بگیرید.
- وقتی داده کمی دارید گزینه over-sampling را امتحان کنید.
- نسبتهای مختلف دادهها رو بررسی کنید ( قرار نیست حتما 1:1 باشه، نسبتهای دیگه مثل 2:1 رو امتحان کنید)
برای under-sampling بهینه میتوانید خوشهبندی انجام دهید و نمونههای گروهی که زیاد هست را با روشهای خوشهبندی مثل kmeans خوشهبندی کنید و سپس از مراکز خوشهها به عنوان نمونه جدید استفاده کنید. با این روش به طور بهنیه میتوانید تعداد نمونه ها را کم بکنید و در عین حال توزیع داده در فضای ویژگی را حفظ کنید!
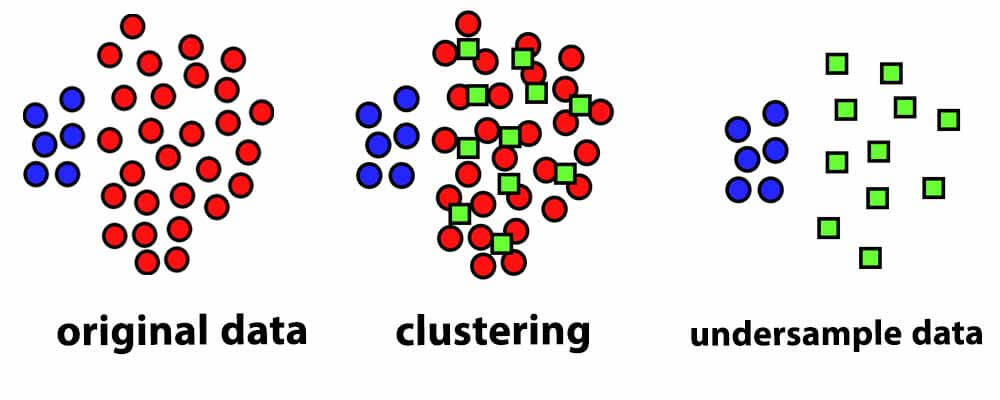
داده مصنوعی (synthetic) بسازید
یک راه ساده این است که از روی نمونههای گروه کوچکتر، یک سری نمونههای جدید بسازید که شبیه به آنها باشند! روشهای سیستماتیکی خوبی مثل SMOTE (Synthetic Minority Over-sampling Technique) برای تولید داده مصنوعی وجود دارد که میتونید از اونها استفاده کنید.
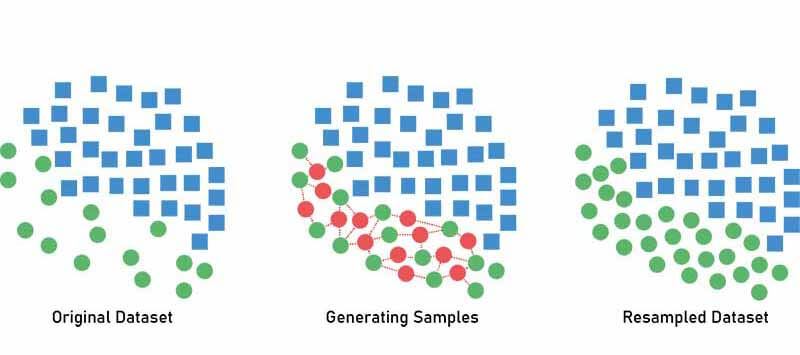
همانطور که از اسم روش SMOTE پیداست از این روش برای over-sampling استفاده می کنند. این روش به به جای اینکه نمونهها را کپی کند، از روی آنها نمونههایی در همسایگیشان تولید میکند.
همانند شکل بالا این الگوریتم با کمک اندازهگیری فاصله، دو یا چند نمونه مشابه را انتخاب کرده و از روی آنها نمونه جدید در همسایگی ایجاد میکند.
الگوریتهای مختلفی امتحان کنید
ما معمولا به یک الگوریتم علاقهی خاصی داریم و در اکثر مواقع از اون الگوریتم برای حل هر مسئلهای استفاده میکنیم. پیشنهاد میکنیم که برای هر مسئله فقط از الگوریتم مورد علاقتون استفاده نکنید. حداقل برای بررسی مختصر هم که شده از انواع مختلف الگوریتمها برای حل یک مسئله استفاده کنید.
گفته میشود که درخت تصیمم برای دادههای نامتعادل عملکرد بهتری دارد. چرا که در این الگورتیم میتوان شاخهها را طوری تنظیم کرد که موقع پیدا کردن مرز تصمیمگیری به نمونههای هر دو گروه به اندازه کافی توجه کند و تا حدودی مشکل داده نامتعادل را حل کند.
جریمه کردن مدلها
میتوان از همان الگورتیم برای حل مسئله استفاده کرد منتهی با دید متفاوتی مسئله را به مدل ارائه دهید. برای مثال میتونید یک تابع هزینه اضافه به مدل اضافه کنید و در زمان آموزش مدل، برای محاسبه دقت یا خطا از دادههای کلاس کمتر استفاده کنید.
برای مثال در شبکههای عصبی که براساس خطای طبقهبندی در طول زمان وزنهای خود را تنظیم میکنند تا به خطای طبقهبندی حداقل برسند یا به عبارتی به دقت طبقهبندی حداکثری برسند، به جای محاسبه خطا یا دقت طبقهبندی از کل داده، از دادههای کلاسی که تعداد نمونههای کمتری دارد استفاده کنید و خطای طبقهبندی دادههای کلاس کمتر به عنوان معیار ارزیابی باشد و شبکه در طول زمان سعی کند خطای طبقهبندی دادهای که نمونه کمتری دارد را حداقل کند.
وزندهی به نمونهها
میتوان در پروسه ی آموزش مدل به نمونهها یک وزنی داده شود. برای مثال به نمونههای داده کلاس حداقل وزن بیشتری داده شود تا مدل زمان اموزش توجه بیشتری به آنها بکند تا مرز تصمیم گیری را طوری بدست بیاورد که بتواند با دقت خوبی نمونههای کلاس حداقل را با دقت خوبی دسته بندی کند.

سعی کردیم در این بخش روشهایی رو بیارویم که بتونه برای شما دوستان در رفع مشکل داده نامتعادل مفید باشد. اگر روشهای دیگری رو میشناسید خوشحال میشویم با ما به اشتراک بگذارید…
دوره های مرتبط
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

پکیج کامل پیادهسازی گام به گام شبکههای عصبی

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

سلام بسیار ساده و عالی
بنده اخیرا مقاله ای در یگ ژورنال ISI اشپرینگر چاپ کردم برای همین مسئله داده های نامتوازن
Swarm-based Cost-sensitive Decision Tree Using Optimized Rules for
Imbalanced Data Classification
مرسی بابت معرفی مقاله
موفق باشید