
5 روش برای جلوگیری از بیشبرازش شبکه عصبی
- دسته:اخبار علمی
- امیررضا جهانی
در پیاده سازی شبکه هایی عصبی، عمده ترین مشکلی که باهاش مواجه می شویم overfitting یا همان بیش برازش مدل هست. در این پست میخواهیم در مورد بیشبرازش و روشهایی جلوگیری از آن در شبکه عصبی صحبت کنیم.
5 روشی که اجازه نمیدهد تا شبکه عصبی شما بیشبرازش شود
همه ما در زمینه علم داده، به دنبال یک روش مدلسازی هستیم که بتواند به طور دقیق پیش بینی و کار کند. با این حال، مدلسازی شبکههای عصبی پتانسیل بالایی برای دقیق شدن دارد، اما مشکلات مختلفی نیز وجود دارد که توسعهدهندگان برای نتایج بهینه از مدلسازی، با آنها مواجه میشوند. بیشبرازش (overfitting) نیز مشکلی است که میتواند به دلیل مدل یا دادههایی که با آن کار میکنیم، در شبکههای عصبی ایجاد شود. در این مقاله قصد داریم به بیشبرازش و روشهای مورد استفاده برای جلوگیری از آن در شبکه عصبی بپردازیم. مهمترین نکاتی که در مقاله مورد بحث قرار میگیرد در فهرست زیر ذکر شده است.
فهرست مطالب
- بیشبرازش
- روشهای جلوگیری از بیشبرازش در شبکه عصبی
- روش 1: افزایش داده ها
- روش 2: ساده سازی شبکه عصبی
- روش 3: رگولهسازی وزن
- روش 4: Drop Out
- روش 5: توقف زودهنگام
حال بیایید با درک بیشبرازش شروع کنیم.
بیشبرازش (Overfitting)
در بسیاری از نمونههای مدلسازی، میتوانیم متوجه شویم که مدل سطح بالاتری از دقت را نشان میدهد، اما هنگامی که صحبت در مورد پیشبینی میشود، مشاهده میکنیم که مدل خروجیهای اشتباهی را ارائه میکند. اینها موقعیتهایی هستند که میتوان گفت مدل overfit شده است. در حین مدلسازی دادهها، ما عمدتاً بر تخمین توزیع و احتمال دادهها تمرکز میکنیم.
این تخمین به ما در ایجاد مدلی کمک میکند که بتواند با استفاده از مقادیر مشابه، عمل پیشبینی را انجام دهد. Under Training، یک مدل میتواند با مقدار نویز زیادی در دادههای آموزشی مواجه شود و این میتواند دلیلی بر نادرست بودن مدل باشد، چراکه سعی بر این داشته تا آن نویز را نیز مدل کند.
بیشبرازش زمانی اتفاق میافتد که مدل سعی میکند تمام جزئیات و نویز دادهها را یاد بگیرد و این یادگیری تا جایی پیش میرود که مدل شروع به پیشبینی اشتباه میکند. یا میتوان گفت یادگیری، بر عملکرد مدل و بر روی دادههای جدید تأثیر میگذارد.
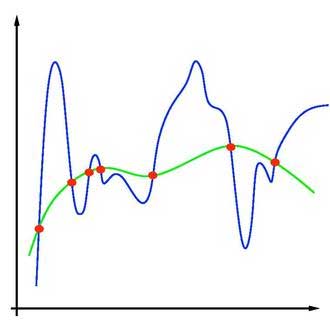
تصویر بالا نمایشی از موضوع بیشبرازش است که در آن نقاط قرمز، نقاط داده و خط سبز نشان دهنده رابطه بین دادهها و خط آبی نشان دهنده یادگیری مدلی است که بیشبرازش شده است.
به طور کلی، این مشکل را در مدلهای غیرخطی پیدا میکنیم و از آنجا که اکثر شبکههای عصبی غیرخطی هستند مشکل بیشبرازش را خواهند داشت. در اینجا غیرخطی بودن مدلها به این معنی است که آنها انعطاف پذیر هستند و میتوانند بر اساس دادهها گسترش پیدا کنند که باعث میشود گاهی اوقات مدل بیشبرازش شود. در این مقاله مراحلی که باید برای جلوگیری از بیشبرازش شبکه عصبی انجام دهیم رامورد بررسی قرار خواهیم داد.
گام هایی برای جلوگیری از بیشبرازش شبکه عصبی
در این بخش، به برخی از مراحل ساده اما اصلی که یک روش مدلسازی اولیه، برای جلوگیری از بیشبرازش شبکه عصبی نیاز دارد نگاهی میاندازیم. از قسمت دادهها شروع میکنیم و به سمت آموزش پیش میرویم.
روش 1: افزایش داده ها (Data Augmentation) برای جلوگیری از overfitting شبکه عصبی
دستیابی به دادههای بیشتر راهی برای بهبود دقت مدلها است. درک این نکته ساده است که دادههای بیشتر، جزئیات بیشتری در مورد وظیفهای که مدل باید انجام دهد را ارائه می دهد. در اینجا افزایش دادهها میتواند به عنوان راهی برای بزرگ کردن مجموعه دادههای ما در نظر گرفته شود.
برای مثالی ساده در حین کار با مجموعه کوچک دادهی تصویر، میتوانیم تعداد تصاویر را با اضافه کردن نسخههای چرخانده شده و تغییر مقیاسشده تصاویر، در دادهها افزایش دهیم. این باعث افزایش اندازه دادهها میشود و با استفاده از چنین تکنیکهایی میتوانیم دقت مدل را افزایش دهیم و در عین حال آن را از شرایط بیشبرازش نجات دهیم.
این مرحله یک مرحله کلی بوده که میتواند برای هر نوع مدل سازی استفاده شود، خواه شبکه عصبی باشد یا مدل های ایستا مانند random forest و ماشین بردار پشتیبان. روشهای مختلفی برای تقویت دادهها با دادههای طبقهبندی مانند SMOTE وجود دارد، و با بیشنمونهبرداری میتوانیم ایدهای از افزایش دادهها با دادههای تصویری پیدا کنیم.
روش 2: سادهسازی شبکه عصبی برای جلوگیری از overfitting شبکه عصبی
ممکن است این یک گام اشتباه برای حل مشکل ما به نظر برسد، اما این یکی از گامهای اساسی و آسان برای جلوگیری از بیشبرازش است. این مرحله میتواند شامل 2 روش باشد، یکی حذف لایههای پیچیده و دوم کاهش نورونهای لایهها. در مدلسازی کلی، میتوان دریافت که استفاده از مدلهای پیچیده با دادههای آسان میتواند مشکل بیشبرازش را افزایش دهد در حالی که مدلهای ساده میتوانند عملکرد بسیار بهتری داشته باشند.
قبل از کاهش پیچیدگی شبکه، باید ورودی و خروجی لایه ها را محاسبه کنیم. همیشه پیشنهاد میشود به جای اعمال پیچیدگی در شبکه، از شبکههای ساده استفاده کنید. اگر شبکه دچار بیشبرازش شده است، باید سعی کنیم آن را ساده کنیم.
روش 3: رگوله سازی وزن برای جلوگیری از overfitting شبکه عصبی
رگولهسازی وزن مرحلهای است که با کاهش پیچیدگی مدلها به جلوگیری از بیشبرازش کمک میکند. راههای مختلفی برای رگولهسازی مانند L1 و L2 وجود دارد. این روشها عمدتاً با جریمه کردن (penalizing) وزنهای هر تابعی کار میکنند و این وزنهای کوچکتر منجر به مدلهای سادهتر میشوند. همانطور که در بالا توضیح داده شد، مدل های سادهتر به جلوگیری از بیشبرازش کمک میکند.
همانطور که از نام آن پیداست، این مرحله عبارت منظمسازی را به همراه تابع هزینه (Loss Function) اضافه میکند بطوری که ماتریس وزنها میتواند کوچکتر شود. عمل جمع، یک تابع هزینه (Cost Function) میسازد و میتواند به صورت زیر تعریف شود.
تابع هزینه = هزینه + ترم رگولهسازی
با نگاه کردن به اصطلاح رگولهسازی میتوانیم بین روشهای رگولهسازی تفاوت قائل شویم.
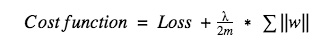
در اینجا می توان گفت که این رگولهسازی سعی می کند قدر مطلق وزن ها را به حداقل برساند.
با استفاده از رگولهسازی L2، عبارت رگولهسازی زیر را اضافه می کنیم.
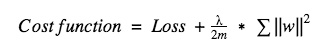
در اینجا میتوانیم ببینیم که این رگولهسازی تلاش میکند تا قدر مجذور وزنها را به حداقل برساند.
هر دوی این روشها روشهای محبوبی هستند و تفاوت اصلی بین آنها این است که روش L1 قوی، ساده و قابل تفسیر است در حالی که رگولهسازی L2 قادر به یادگیری دادههای پیچیده است و چندان قوی نیست. بنابراین انتخاب هر یک از روش ها به پیچیدگی دادهها بستگی دارد.
روش 4: استفاده از روش Dropout برای جلوگیری از overfitting شبکه عصبی
این مرحله به ما کمک میکند تا با کاهش تعداد نورونهای شبکه تا زمانی که شبکه آموزش ببیند، از بیش برازش جلوگیری کنیم. همچنین میتوان گفت که این یک تکنیک رگولهسازی است اما برخلاف تابع هزینه، با نورونها کار میکند.
این روش ساده است و نورونها را در حین آموزش در هر تکرار(epoch) از شبکه حذف میکند. همچنین میتوانیم به این فرآیند بهگونه ای فکر کنیم که شبکه را در حین آموزش ساده و متفاوت میکند، زیرا درنهایت باعث کاهش پیچیدگی شبکه و تمایل به آمادهسازی یک شبکه جدید میشود. اثر خالص اعمال لایههای Dropout در شبکه، به کاهش میزان بیشبرازش شبکه همگرا میشود. تصویر زیر را میتوان به عنوان نمایشی از کار این مرحله در نظر گرفت.
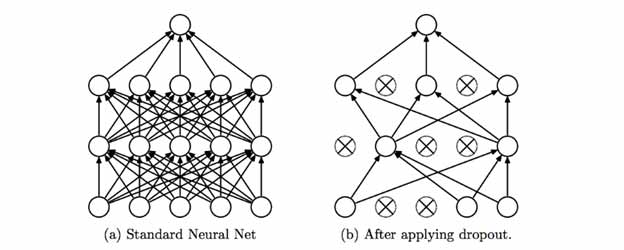
تصویر بالا مدلی با 2 لایه پنهان را نشان میدهد که پیچیدگی آن با حذف برخی از نورونها کاهش مییابد.
روش 5: توقف زودهنگام آموزش برای جلوگیری از overfitting شبکه عصبی
همانطور که از نام آن پیداست این مرحله روشی برای توقف آموزش شبکه در مراحل اولیه نسبت به مرحله نهایی است. ما میتوانیم آن را با تکنیک اعتبارسنجی متقابل مقایسه کنیم، زیرا برخی از بخشهای دادههای آموزشی به عنوان دادههای اعتبارسنجی استفاده میشوند؛ تا بتوان عملکرد مدل را در برابر این دادههای اعتبارسنجی اندازهگیری کرد. با افزایش عملکرد مدل به نقطه اوج، میتوان آموزش را متوقف کرد.
این مرحله در حالی که ما مدل را آموزش میدهیم نیز کار میکند. همانطور که مدل در آموزش یاد میگیرد، ما سعی میکنیم عملکرد آن را روی دادههای دیده نشده اندازهگیری کنیم و آموزش را تا نقطهای ادامه دهیم که مدل شروع به کاهش دقت در اعتبارسنجی یا دادههای دیده نشده کند. اگر عملکرد این مجموعه اعتبارسنجی کاهش یابد یا برای تکرارهای خاص ثابت بماند، آموزش متوقف می شود.
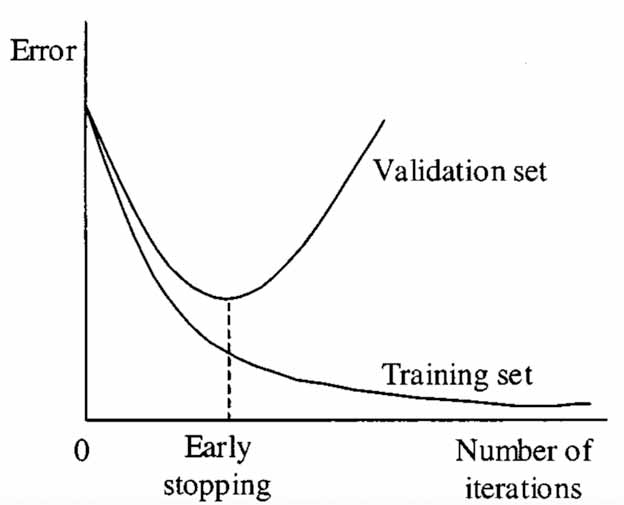
تصویر بالا نمایشی از نمودار یادگیری یک شبکه است که در آن توقف اولیه اعمال میشود. میتوانیم ببینیم که با شروع افزایش خطاها، نقطه توقف اولیه تصمیمگیری میشود و میتوانیم آموزش شبکه را در این نقطه متوقف کنیم.
دوره های مرتبط

پکیج کامل پیادهسازی گام به گام شبکههای عصبی
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دیدگاه ها