
یادگیری بازنمایی یا Representation Learning چیست؟
- دسته:اخبار علمی
- هما کاشفی
یادگیری بازنمایی یا Representation Learningروشی برای آموزش یک مدل یادگیری ماشین است تا بتواند مفیدترین بازنمایی دادهی ورودی را یاد بگیرد. این بازنماییها که اغلب به عنوان ویژگی (feature) شناخته میشوند، حالتهای داخلی مدل هستند که میتوانند دادههای ورودی را به خوبی خلاصه کنند و از این طریق به الگوریتم کمک میکنند تا الگوهای کلی دادهها را بهتر درک کند.
در حال حاضر Representation Learning از مهندسی ویژگی سنتی و دستی تغییر پیدا کرده است و بیشتر تمرکز بر این است که به مدل اعتماد شود تا بتواند به طور خودکار از دادههای ورودی فراوان و پیچیده، چکیدههای معنادار و ساده تولید کند. این رویکرد برای دادههای پیچیده مانند تصاویر یا متن، موثر است. جایی که تشخیص ویژگیهای مرتبط به صورت دستی بسیار دشوار است. مدل با شناسایی و رمزگذاری الگوها میتواند دادهها را ساده کند و در عین حال تضمین میکند که اطلاعات ضروری از دست نرفتهاند و نگهداری میشوند. به طور خلاصه، Representation Learning راهی برای ماشینها ارائه میدهد تا به طور مستقل، اطلاعات ذخیره شده در دیتاستهای بزرگ را درک و فشردهسازی کنند.
از مهندسی ویژگی دستی تا مهندسی ویژگی خودکار
در روزهای اولیهی ظهور یادگیری ماشین، مهندسی ویژگی شبیه به مجسمهسازی با دست بود. مهندسان میبایست به صورت دستی، ویژگیها را از دادههای خام شناسایی میکردند. این فرآیندی بود که به شدت وابسته به تخصص و شهود مهندسان بود. مثلاً فرض کنید میخواستیم قیمت خودرو را پیش بینی کنیم. فراتر از ویژگیهای آشکار مانند سال ساخت، مدل یا مسافت پیموده شده، باید حدس زد: آیا رنگ خودرو اهمیت دارد؟ یا ماه فروش آن؟ این فرآیند خسته کننده و اغلب محدود کننده بود.
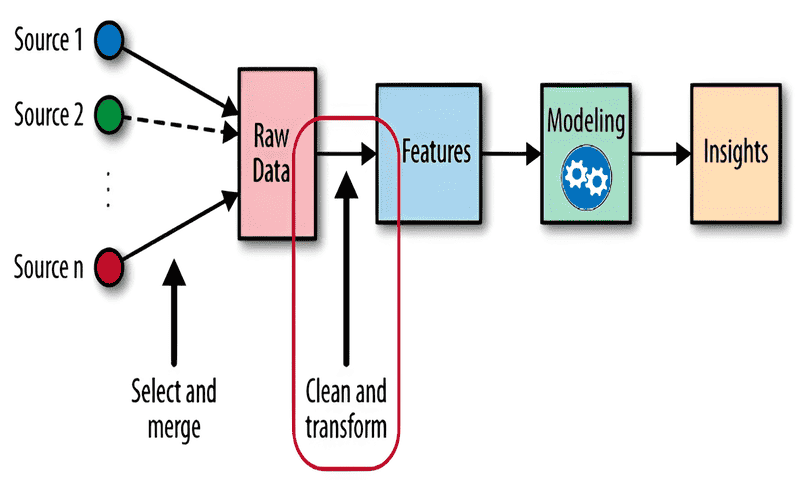
سپس Representation Learning ظهور پیدا کرد که رویکردی انقلابی بود که به مدل این امکان را میداد تا مفیدترین و بهترین ویژگیها را یاد بگیرد. بدون اینکه نیاز باشد مثلاً بدانیم «ماشین چیست؟» یا «آیا قیمت مهم است؟»، یادگیری بهترین ویژگیها امکان پذیر میشود. بنابراین در حالیکه مهندسی ویژگی، پایه و اساس انتخاب مفیدترین ویژگیها را ایجاد کرد. Representation Learning جستجوی ما را در دادهها، ساده و عمیق کرد و عصر جدیدی از کارایی و سازگاری را نشان میدهد.
یادگیری خودنظارتی (Self-Supervised Learning): خودرمزنگارها (autoencoders)
یادگیری خودنظارتی زیرمجموعهای از یادگیری بدون ناظر است و روشی قدرتمند برای یادگیری بازنمایی داده است. از جمله محبوبترین رویکردها در این دسته، خودرمزنگار است. خودرمزنگار نوعی شبکه عصبی است که یاد میگیرد دادههای ورودی را به فرم با ابعاد پایینتر و در نتیجه فشردهتر رمزگذاری کند. سپس شبکه این فرم کدگذاری شده را برای بازسازی ورودی اصلی استفاده میکند. فرآیند رمزگذاری، ویژگیهای ضروری را در دادهها کشف و استخراج میکند. در حالیکه فرآیند رمزگشایی تضمین میکند که ویژگیهای استخراج شده، نمایندهی دادههای اصلی هستند.
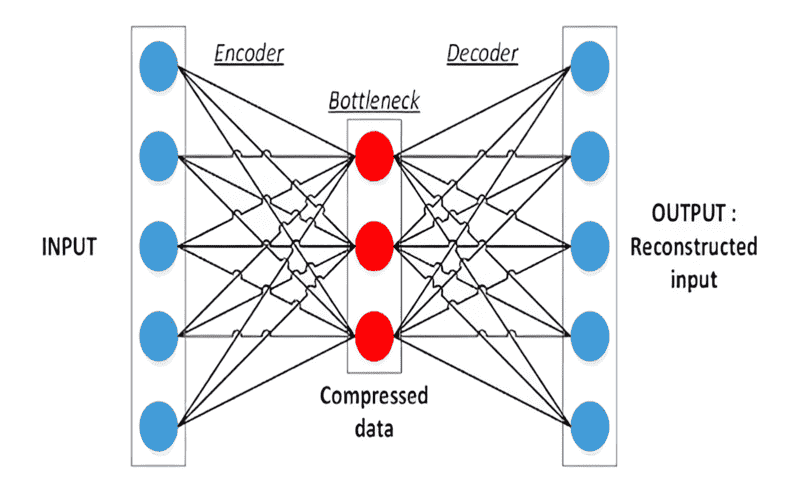
برای درک یادگیری خودنظارتی باید ایدهی فضای embedding را درک کنیم. این فضا، نشانگر ویژگیها یا مشخصههایی است که خودرمزنگار (یا هر مدل خودنظارتی دیگر) آنها را یاد گرفته است. اگر مدلی به خوبی آموزش دیده باشد، نمونههای داده مشابه در این فضا به یکدیگر نزدیک خواهند بود و خوشهها را تشکیل میدهند. برای مثال، یک مدل آموزش دیده روی دیتاست تصاویر ممکن است خوشههای مجزا برای دستههای مختلف تصاویر مانند پرندگان، لباس و یا غذا تشکیل دهد. فاصله و جهت بین این خوشهها اغلب اطلاعات ارزشمندی در مورد روابط بین دستههای مختلف ارائه میدهد.
این فضای Embedding را میتوان به روشهای مختلفی مورد استفاده قرار داد. برای مثال میتوان از آن برای کاوش داده، تشخیص ناهنجاری یا به عنوان مراحل پیش پردازش برای سایر تسکهای یادگیری ماشین مورد استفاده قرار داد. مفهوم ایجاد یک فضای embedding مفید و گویا در قلب یادگیری خودنظارتی نهفته است و به همین دلیل است که این رویکرد در پژوهشهای یادگیری ماشین مدرن بسیار رایج شده است.
بازنماییهای پنهان در یادگیری نظارتی
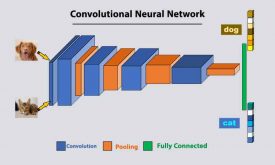
در حالیکه ما بر یادگیری خودنظارتی تمرکز کردهایم، مهم است که توجه داشته باشیم مفهوم representation learning به مدلهای نظارتی نیز توسعه یافته است. یک مثال کلاسیک آن شبکههای عصبی کانولوشنی (CNN) است که برای طبقه بندی تصاویر آموزش دیدهاند. هر چقدر که شبکه عمیقتر میشود، هر لایهی متوالی، بازنمایی انتزاعیتری از دادهی ورودی را یاد میگیرد.
در لایههای اول یک شبکه CNN، شبکه ممکن است ویژگیهای سادهای مانند لبهها و رنگها را نشان دهد. هر چقدر در شبکه عمیقتر شویم، این عناصر با اشکال و الگوهای پیچیدهتر ادغام میشوند. زمانی که به لایههای انتهایی میرسیم، بازنماییها آنقدر انتزاعی شدهاند که میتوانند دستههای پیچیده مانند نژادهای مختلف سگ و یا انواع مختلف وسایل نقلیه را متمایز کنند. اساساً هر چقدر مدل عمیقتر باشد، بازنمایی آن انتزاعیتر و اغلب مفیدتر است.
یادگیری انتقالی (Transfer Learning): روشی ایجاد شده بر پایهی رویکرد خودنظارتی
در قلب مدلهای خودنظارتی، توانایی غیرمعمول آنها برای کشف بازنماییهای معنادار از دادهی خام نهفته است. بدون اینکه که نیاز باشد به صورت صریح، برچسبهایی برای دادهها مشخص شود. این بازنماییها که توسط الگوها و اتصالات درون دادهها پالایش شدهاند یک توصیف گسترده و کلی از دادهها هستند و برای طیف وسیعی از کاربردها مفیدند. بازنماییهای چندمنظوره، امکان انتقال معنادار اطلاعات یک تسک را به تسکهای دیگر فراهم میکنند. بازنمایی چندمنظوره در اصل همان یادگیری انتقالی است. در اینجا، مدلی که برای یک تسک خاص آموزش داده شده است بر بازنماییهای آموزش دیدهی قبلی تکیه میکند که این بازنماییها ممکن است از یک رویکرد خودنظارتی و یا سایر رویکردهای نظارتی بوجود آمده باشد.
یادگیری انتقالی دو مزیت اصلی دارد: اول اینکه، حجم دادهها به طور قابل توجهی کاهش مییابد. برای اینکه مدلی با عملکرد قوی داشته باشید دیگر به یک دیتاست بزرگ برچسب گذاری شده وابسته نخواهید بود. دوم اینکه منجر به کاهش قابل توجه هزینههای محاسباتی میشود. مدل پایه از قبل، بخش عمدهای از کارهای سنگین را انجام داده است. مدل جدید و مخصوص شما به سادگی با مدل قبلی اصلاح و تخصصیتر میشود.
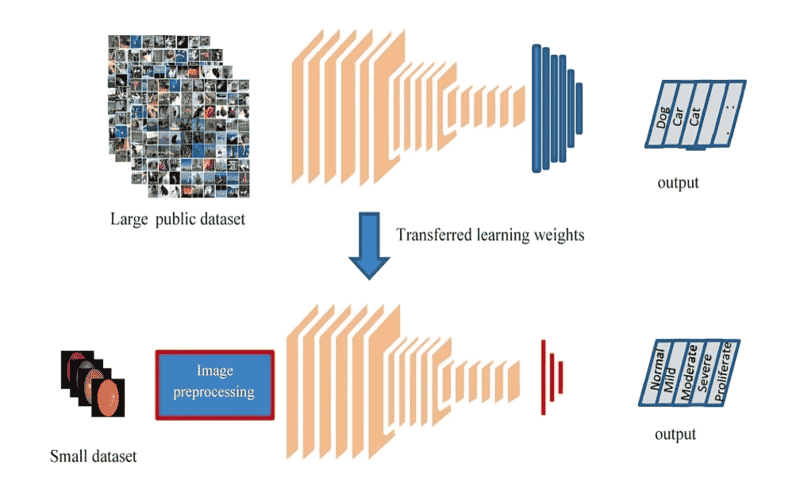
رویکردی که به وفور در یادگیری انتقالی استفاده میشود “Frozen backbone” است. در این رویکرد، بازنماییهایی که در طی یادگیری خودنظارتی شکل میگیرند، دست نخورده باقی میمانند و تنها سر مدل آموزش داده میشود. این روش کارآمد بوده و از نظر محاسباتی کم هزینهتر است. با این حال ممکن است این روش همیشه به راه حل مفیدی منجر نشود. بسته به تسکی که در دست داریم، برخی از بازنماییهای آموخته شده ممکن است با آن چیزی که موردنیاز است هماهنگ نباشد. در چنین مواردی بخشی از مدل را میتوانیم بازآموزی کنیم. این روند اطمینان حاصل میکند که مدل، تفاوتهای ظریف دادهها را تشخیص میدهد و امکانی فراهم میکند تا مدل بازنماییهایی که مرتبط و مفید نیستند را فراموش کند. با استفاده از دانش بنیادی مدلهای خودنظارتی، فرآیند را سادهسازی میکنیم، منابع را حفظ میکنیم و اطمینان حاصل میکنیم که مدلها تا جای ممکن تنظیم شده و آمادهی کار هستند.
چالشهای Representation Learning
این روش مانند هر روش دیگری که در یادگیری ماشین استفاده میشود، چالشها و محدودیتهای خاص خود را دارد.
بیش برازش (Overfitting)
Representation Learning به ویژه زمانی که شامل شبکههای عصبی عمیق باشد ممکن است نویز را در دادهها به عنوان ویژگی در نظر بگیرد. مدلها در تلاش برای شناسایی الگوهای پیچیده ممکن است تنها دادههای آموزشی را حفظ کنند. این مسئله باعث میشود وقتی مدل با دادههای جدید روبرو میشود قابلیت تعمیم نداشته باشد.
تفسیر بازنماییهای آموخته شده
یکی از مزایای مهم مهندسی ویژگی، شفافیت آن است. در رویکردهای قبلی، مهندسان از ویژگیهای مورد استفاده و اثر آنها در مدل نهایی، درک کلی داشتند. اما بازنماییهای آموخته شده در این روش یک جعبه سیاه در مدل هستند. این بازنماییها در عین قدرتمند بودن میتوانند پیچیده، انتزاعی و غیرقابل تفسیر باشند. این مسائل به خودی خود چالشهایی در برنامهها ایجاد میکند.
بار محاسباتی
علیرغم افزایش کارایی بازنماییها با استفاده از مفاهیمی چون یادگیری انتقالی، فرآیند اولیهی آموزش مدلها برای یادگیری این بازنماییها ممکن است محاسبات زیادی بطلبد. شبکههای عصبی عمیق به قدرت محاسباتی زیادی نیاز دارند و این میتواند محدودیتی برای سازمانهای کوچک و یا محققان باشد.
بایاس
مدل از داده یاد میگیرد؛ اگر دادهها با بایاس همراه باشند، بازنماییهای آموخته شده این بایاسها را به طور ناخواسته ضبط میکنند. این امر به ویژه برای مدلهای خودنظارتی مهم است که بر میزان زیادی دادهی بدون برچسب متکی است. این بایاسها ممکن است به پیامدهای اخلاقی منجر شوند به ویژه زمانی که مدلها در نواحی حساسی استفاده میشوند مانند تصویربرداری پزشکی یا دادگاه کیفری.
دوره های مرتبط

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

پردازش سیگنال مغزی با کتابخانه MNE پایتون
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)
دیدگاه ها