شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 0 دیدگاه
در فصل هفتم دوره پترن و یادگیری ماشین، روشهای انتخاب ویژگی( feature Selection)از قبیل ttest، anova، نرخ تفکیک پذیری فیشر(FDR) ، اطلاعات متقابل(Mutual information) و روش جستجوی سلسله مراتبی روبه جلو (sequential forward feature selection ) را معرفی می کنیم و به صورت تخصصی آموزش میدهیم که رویکرد تک تک روشها به چه صورت است، سپس مرحله به مرحله روشها را پیاده سازی می کنیم و در نهایت با انجام پروژه ها و مثالهایی نشان میدهیم که چطور میتوان از این روشها در پروژه های عملی جهت انتخاب ویژگی استفاده کرد.
این فصل یکی از مهمترین فصل های دوره “شناسایی الگو یادگیری ماشین” است و میتواند نقش قابل توجهی در افزایش عملکرد مدل داشته باشد.
همانطور که در فصل شش اشاره کردیم، تمرکز ما در فصل ششم و هفتم روی روشهای feature conditioning است. در فصل ششم روشهای کاهش بعد PCA-LDA را توضیح دادیم که این روشها ویژگیها را نگاشت میدادند به فضای جدید و در فضای جدید کاهش بعد را انجام میدادند. به عبارت دیگر این روشها از ترکیب ویژگی های استخراج شده، یک سری ویژگی ها ایجاد میکردند و بعد در فضای جدید از بین ویژگی های ساخته شده یک تعداد مهمی را انتخاب می کردند. یکی از ایراداتی که میتوان به روشهای feature mapping گرفت این است که این روش ماهیت ویژگی ها تغییر میدهند و امکان تبادل بین فرد و ماشین از بین میرود. روشها انتخاب ویژگی در فضای اصلی کار میکنند و هدفشان این است که بدون اینکه نگاشتی روی ویژگی ها انجام دهند، از بین ویژگیهای موجود ترکیب بهینه ای را انتخاب کنند که هم عملکرد مدل افزایش پیدا کند و هم کاهش بعد انجام گیرد.
یک سیستم شناسایی الگو از چندین مرحله اساسی تشکیل شده است و برای اینکه بتوانیم پروژههای تخصصی انجام دهیم لازم است که در تمامی مراحل ابزارهای بهینه ای داشته باشیم. ما در اکثر پروژههای تخصصی برای اینکه بتوانیم تصمیم گیری بهینه ای انجام دهیم، نیاز داریم که از داده ورودی(سیگنال- تصویر و ...) پارامترهای تاثیرگذار زیادی را استخراج کنیم. از آنجا که به طور دقیق نمیتوان در مسائل پیچیده مشخص کرد که چه فاکتور یا فاکتورهای موثر هستند و ارتباط مستقیمی با تسک مورد نظر دارند، نیاز داریم که فاکتورهای زیادی را به عنوان ویژگی استخراج کنیم. در این حالت ابعاد داده بسیار بالا می رود و باعث می شود تعداد پارامترهای طبقه بند یا الگوریتم رگرسیونی که برای تصمیم گیری استفاده میکنیم افزایش یابد و این ممکن است باعث شود که الگوریتم ما عمویت نداشته باشد یا به عبارتی generalized نباشد، که چالش اصلی ما در پروژه ها طراحی یک مدل generalized است. زیرا که ما روی sample کار میکنیم و میخواهیم مدل طراحی شده روی جمعیت کار کند. و وقتی تعداد پارامترهای مدل افزایش می یابد، به احتمال زیاد مدل ما generalized نخواهد شد.
از طرفی ممکن است در پروسه استخراج ویژگی، ویژگی هایی استخراج شود که اطلاعات مفیدی برای مسئله نداشته باشد و یا تکراری باشند و اطلاعات جدیدی به مسئله اضافه نکنند و حتی ممکن است مرتبط با نویز باشند و کار تحلیل ما را خراب کنند. برای حل این مشکلات از روشهای feature conditioning استفاده می کنیم. تعداد ویژگیها را کاهش میدهیم.
در روشهای feature mapping داده از یک فضایی به یک فضای جدید نگاشت پیدا میکند، به عبارت دیگر در این حوزه ویژگیها باهم ترکیب شده و ویژگیهای جدید را میسازند که تعداد این ویژگی ها نسبت به فضای اصلی کاهش می یابد. در حالی که در روشهای feature selection براساس یک سری معیارهایی تعدادی ویژگیها انتخاب می شوند که در این روشها نیز تعداد ویژگیها کاهش می یابد. ما در فصل هفتم دوره پترن و یادگیری ماشین، روشهای انتخاب ویژگی( feature Selection)از قبیل ttest، anova، نرخ تفکیک پذیری فیشر(FDR) ، اطلاعات متقابل(Mutual information) و روش جستجوی سلسله مراتبی روبه جلو (sequential forward feature selection ) را معرفی می کنیم و به صورت تخصصی آموزش میدهیم که رویکرد تک تک روشها به چه صورت است ، سپس مرحله به مرحله روشها را پیاده سازی می کنیم و در نهایت با انجام پروژه ها و مثالهایی نشان میدهیم که چطور میتوان از این روشها در پروژه های عملی جهت انتخاب ویژگی استفاده کرد.
سرفصل مطالب
1-مقدمه ای بر انتخاب ویژگی
ما برای انتخاب ویژگی دو رویکرد کلی داریم که در شکل زیر نمای کلی این روشها نشان داده شده است.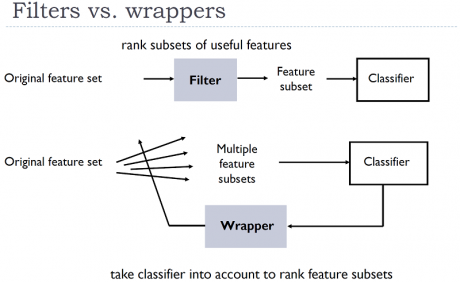 انتخاب ویژگی به صورت اسکالر:
انتخاب ویژگی به صورت اسکالر:
در روشهای اسکالر، میزان اهمیت و تفکیک پذیری ویژگی ها جدا جدا بررسی می شوند و طبق رویکرد الگوریتم مورد نظر به تک تک ویژگی ها یک امتیازی داده میشود که این امتیاز میزان تفکیک پذیری و اهمیت ویژگی را مشخص می کند.
در روشهای اسکالر(filter methods) مدل(طبقه بند) در جریان انتخاب ویژگی نیست که همین میتواند مزیت این روشها و هم عیب این روشها شود. مزیت این رویکرد این است که زمان اجرای الگوریتم بسیارپایین است و در مدت زمان بسیار کوتاه بدون اینکه مدل در جریان کار باشد، به ویژگی ها امتیاز داده میشود. و بعد از بین ویژگی ها یک تعداد بسته به نیاز انتخاب می شوند. عیب این رویکرد این است که چون مدل در جریان کار نیست، ممکن است ویژگی های مناسب برای مدل انتخاب نشود.
ایراد دوم روشهای اسکالر این است که ارتباط بین ویژگی ها در نظر گرفته نمیشود، و همین ممکن است باعث انتخاب ویژگیهایی شود که به تنهایی خوب عمل کنند ولی کنار هم عالی عمل نکنند. هدف اصلی ما این است که ویژگی های انتخاب شوند که کنارهم عملکرد طبقه بندی یا رگرسیون را بالا ببرند، ولی در این رویکرد ممکن است ویژگی های انتخاب شده ترکیب خوبی تشکیل ندهند. با این حال روشهای اسکالر روشهای بسیار مهمی،مخصوصا در تعیین اهمیت ویژگیها، هستند، زیرا که با هزینه زمانی بسیار پایین میتوانند مشخص کنند که یک ویژگی مناسب است یا نه. و برای همین منظور از روشهای اسکالر در پروژه ها خیلی استفاده می شود و ما هم در این دوره سعی کرده ایم روشهای معروف و کارایی رو آموزش دهیم تا بتوانید از آنها در انجام پروژه های خودتان بهره ببرید.
انتخاب ویژگی به صورت برداری:بر خلاف روشهای اسکالر، روشهای برداری(wrapper methods) مدل را در جریان انتخاب ویژگی قرار میدهند و همچنین ارتباط بین ویژگی ها را در نظر میگیرند. این روشها سعی برآن دارند که بهترین ترکیب از بین ویژگیهای موجود انتخاب کنند. روشهای wrapper به خاطر اینکه مدل را در جریان انتخاب ویژگی قرار میدهند، زمان بر هستند و ممکن است زمانی که تعداد ویژگی ها زیاد شود، هزینه زمانی بالایی داشته باشند.
اما به خاطر اینکه این روشها از لحاظ رویکرد انتخاب ویژگی بسیار توانمند هستند، در عمل خیلی استفاده می شوند. البته ما در انتهای دوره سعی کرده ایم از مزیت هر دو رویکرد استفاده کنیم و یک روش ترکیبی از filter methods و wrapper methods بسازیم که هم از لحاظ زمانی خوب عمل کند و هم بهترین ترکیب از بین ویژگیهای موجود انتخاب کند.
در این جلسه ضرورت انتخاب ویژگی را توضیح داده و سپس مفاهیم پایه در انتخاب ویژگی را توضیح میدهیم تا جهت یادگیری روشهای انتخاب ویژگی در جلسات بعدی آماده شویم.
2- انتخاب ویژگی با روشهای اسکالر - Filter methods
همانطور که اشاره کردیم، روشهای اسکالر از لحاظ زمانی بسیار مقرون به صرفه هستند و در یک زمان بسیار کوتاه میتوانند مشخص کنند که چه ویژگی برای طبقه بندی یا رگرسیون مناسب هست یا نه. برای همین ما در این دوره چندین روش معروف و کارا برای انتخاب ویژگی آموزش داده ایم تا با کمک آنها بتوانید در پروژه های خود برای بررسی و انتخاب ویژگی های استخراج شده استفاده کنید.
· انتخاب ویژگی با تست آماری ttest
تست آماری Ttest، یکی از معروف ترین روشها در تحلیل میزان عملی بودن یک آزمایش و یا میزان اهیمت یک ویژگی هست. این روش بر اساس دو فرضیه آماری مشخص میکند که یک ویژگی چقدر برای تفکیک داده های دو کلاس مناسب است یا نه.
تست آماری Ttest، میزان اختلاف میانگین ویژگی در داده های دو کلاس را بررسی کرده و مشخص میکند که این اختلاف چقدر معنادار است. در این روش با از روی واریانس و میانگین یک ویژگی در داده های دو کلاس، یک tvalue محاسبه میشود که میزان تفکیک پذیری یک ویژگی را مشخص می کند. بعد از روی tvalue یک pvalue محاسبه میشود که یک احتمالی بین صفر تا یک هست. این عدد میزان اهمیت یک ویژگی را مشخص میکند و ویژگی ای برای تفکیک داده های دو کلاس مناسب است که مقدار pvalue نزدیک به صفر داشته باشد.
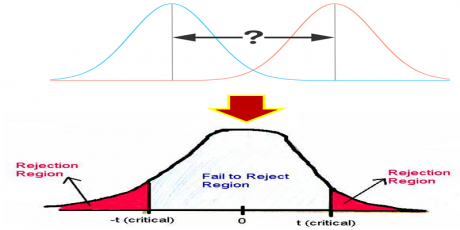
ما در این جلسه به صورت مفهومی رویکرد تست آماری ttest را توضیح میدهیم، سپس با مفهوم tvalue,pvalue و hvalue آشنا می شویم و سپس انواع روشهای تست آماری ttest را توضیح میدهیم و سپس چندین مثال ساده انجام میدهیم تا به صورت عملی متوجه شویم که روش unpaired ttest به چه صورت در مورد ویژگی های تصمیم گیری می کند و بعد چندین پروژه عملی انجام میدهیم تا متوجه شویم که چطور می توانیم از روش ttest برای انتخاب ویژگی های مهم در پروژه های تخصصی استفاده کنیم.
در این جلسه آزمایشات مختلفی انجام شده تا متوجه شویم که برای هر پروژه ای چطور میتوانیم تعداد ویژگی های بهینه را با کمک ttest انتخاب کنیم.
پروژه های انجام شده:
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک Ttest
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک Ttest
- انتخاب ویژگیهای مهم و کلیدی در داده iris با کمک Ttest
· انتخاب ویژگی با روش تجزیه و تحلیل واریانسها( anova)
روش آماری ttest، برای مسائل دو کلاسه استفاده می شود و نمی توانیم در مسائل چندکلاسه استفاده کنیم. آقای فیشر برای حل این مسئله روش anova، تجزیه و تحلیل واریانسها، را مطرح کردند. در این روش به جای اینکه tvalue هر ویژگی محاسبه شود، fvalue هر ویژگی از روی واریانس داده محاسبه شده و سپس به pvalue تبدیل می شود که میزان اهمیت یک ویژگی را مشخص می کند. این روش از دو مسیر واریانس داده را محاسبه میکند و سپس بررسی میکند که آیا این واریانسها باهم اختلاف دارند یا نه، اگر اختلاف داشته باشند، این به این معنی هست که میانگین ویژگی در کلاسها به صورت معناداری متفاوت است، ولی اگر نزدیک بهم باشد، نشان میدهد که میانگین ویژگی در کلاسهای مختلف به صورت معناداری متفاوت نیست و نمیتواند ویژگی مناسبی برای تفکیک داده های دو یا چند کلاس باشد.
در این جلسه به صورت کامل روش anova را توضیح داده و چندین پروژه تخصصی انجام داده ایم تا متوجه شویم که چطور میتوان از این روش در انتخاب ویژگی مناسب در مسائل چندکلاسه استفاده کرد.
پروژه های انجام شده:
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک ANOVA
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک ANOVA
- انتخاب ویژگیهای مهم و کلیدی در داده iris با کمک ANOVA
· انتخاب ویژگی با نرخ تفکیک پذیری فیشر(FDR)
روش fdr رویکرد یکسانی با ttest و anova دارد، و براساس دو پارامتر میانگین و واریانس یک ویژگی، میزان اهمیت آن برای دسته بندی داده های دو یا چند کلاس را مشخص میکند. منتهی در این روش دیگر درگیر محاسبه pvalue نیستیم و فقط از روی fvalue میزان تفکیک پذیری یک ویژگی را مشخص می کنیم. در این روش، ورایانس بین کلاسی و درون کلاسی طبقه رابطه ای که آقای فیشر مطرح کردند محاسبه می شود که مقدار بدست آمده fvalue نامیده میشود که میزان اهمیت ویژگی را مشخص می کند. همان طور که در شکل زیر نشان داده شده است، از دید آقای فیشر ویژگی ای مناسب است که واریانس درون کلاسی حدقل و واریانس بین کلاسی حداکثری داشته باشد. ما در این جلسه روش آقای فیشر را کامل توضیح داده و سپس مرحله به مرحله در متلب پیاده سازی کرده و چندین پروژه عملی انجام میدهیم تا متوجه شویم که چطور میتوان از این روش در انتخاب ویژگی مناسب در مسائل چندکلاسه استفاده کرد.
پروژه های انجام شده:
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک FDR
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک FDR
- انتخاب ویژگیهای مهم و کلیدی در داده iris با کمک FDR
· انتخاب ویژگی با اطلاعات متقابل (mutual information)
ویژگیها اطلاعات زیادی از خروجی به مدل میدهند و مدل براساس همین اطلاعات مقدارِ خروجی را در پروژه های طبقه بندی و رگرسیون تخمین میزند. روش اطلاعات متقابل رویکرد کاملا متفاوتی با روشهای قبلی دارد و به جای تحلیل میانگین و واریانس یک ویژگی، میزان ارتباط یک ویژگی با خروجی را بررسی قرار میدهد. و براساس میزان اطلاعات متقابلی که یک ویژگی در مورد خروجی قرار میدهد، به آن امتیاز میدهد. رویکرد این روش بسیار جالب و مهم است و به خوبی میتواند مشخص کند که یک ویژگی چقدر برای تخمین خروجی مناسب است.
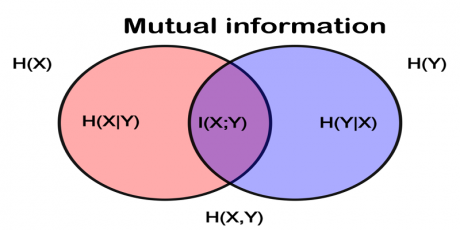
ما در این جلسه در ابتدا مفاهیم پایه از قبیل هیستوگرام تک متغیره و دو متغیره(شکل بالا)، تخیمن تابع توزیع تک متغیره، تخمین تابع توزیع دو متغیره، آنتروپی، آنتروپی شرطی را توضیح داده ایم، سپس تئوری روش اطلاعات متقابل را توضیح داده و بعد در متلب به صورت مرحله به مرحله پیاده سازی کرده ایم. خوبی روش mutual information این هست که هم میتوان در مسائل طبقه بندی و هم در مسائل رگرسیون برای انتخاب ویژگیهای بهینه استفاده کنیم.
پروژه های انجام شده:
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک mutual information
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک mutual information
- انتخاب ویژگیهای مهم و کلیدی در داده iris با کمک mutual information
- انتخاب ویژگیهای مهم و کلیدی در داده سیگنال emg جهت تخمین زاویه مفصل مچ پا با کمک mutual information
3- انتخاب ویژگی با روشهای برداری(ترکیبی)- wrapper methods
همانطور که اشاره کردیم در بین روشهای انتخاب ویژگی، روشهای برداری بسیار خوب عمل می کنند. چرا که این روشها بهترین ترکیب ممکن از میان ویژگیهای موجود انتخاب میکنند که همین باعث افزایش قابل توجه عملکرد مدل می شود که این هدف اصلی ما در انتخاب ویژگی است.· بررسی معایب روشهای اسکالر و نحوه انتخاب ویژگی با کمک یک مدل
همانطور که گفتیم، یکی از ایرادهای روشهای اسکالر این است که مدل را در جریان انتخاب ویژگی قرار نمیدهند، ما در بخش اول مباحث مربوط به جلسه ششم، از یک دیدگاه بسیار ساده به مسئله نگاه میکنیم و توضیح میدهیم که چطور میتوانیم یک مدل را وارد پروسه انتخاب ویژگی میکنیم.· انتخاب ویژگی با روش جستجوی رو به جلو
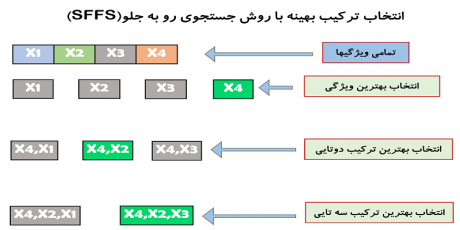
در بخش دوم یکی از مهمترین روشهای انتخاب ویژگی برداری به نام روش انتخاب ویژگی جستجوی رو به جلو، sequential forward feature selection-SFFS، آموزش داده و به صورت مرحله به مرحله در متلب پیاده سازی میکنیم، و در نهایت هم چندین پروژه عملی انجام میدهیم تا هم با قدرت این الگوریتم آشنا شویم و هم متوجه شویم که چطور میتوانیم از این روش در پروژه های تخصصی برای انتخاب ترکیب بهینه ویژگی ها استفاده کنیم.
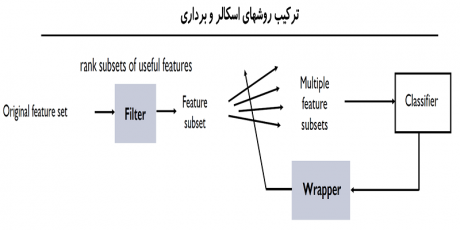
· ترکیب روشهای اسکالر با روشهای برداری
در بخش سوم به صورت عملی توضیح میدهیم که چطور میتوانیم روشهای اسکالر و برداری را باهم ترکیب کنیم تا یک روش سریع و البته بهینه جهت انتخاب بهترین ترکیب ویژگی ها ارائه دهیم.
پروژه های انجام شده:
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک SFFS
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک SFFS
- انتخاب ویژگیهای مهم و کلیدی در داده آلودگی هوا با کمک SFFS
- انتخاب ویژگیهای مهم و کلیدی در داده سرطان سینه با کمک Ttest+SFFS
- اانتخاب ویژگیهای مهم و کلیدی در داده سیگنال مغزی افراد مبتلا به صرع با کمک با کمک anova+SFFS
این فصل یکی از مهمترین فصلهای دوره " شناسایی الگو و یادگیری ماشین" است و خیلی میتواند در پروژه ها برای افزایش دقت مدل کمک کند. سعی کرده ایم در این فصل پروژه های متعددی انجام دهیم تا متوجه شویم که چطور میتوانیم از روشهای انتخاب ویژگی بهره بگیریم تا دقت مدل را افزایش دهیم.
محتوای پکیج:
- ویدیوهای آموزشی
- کدهای پیاده سازی شده برای پروژه ها، تمرینات و مقالات
- منابع معتبری که برای تهیه ویدیو استفاده شده اند(کتب و مقالات مرجع)
- جزوه دست نویس مدرس
فصل 1-4 : از بیزین تا SVM فصل 5: یادگیری جمعی(ensemble learning) فصل 6: تئوری و پیاده سازی روشهای کاهش بعد(PCA-LDA)
دوره های مرتبط

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)