شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA
- دسته:پکیجهای آموزشی, متلب, یادگیری ماشین
- 0 دیدگاه
در یک سیستم شناسایی الگو، کاهش بعد در مرحله چهارم بین طبقهبندی و استخراج ویژگی قرار میگیرید و هدفش کاهش تعداد ویژگی های استخراج شده میباشد تا کار تصمیم گیری را برای طبقهبند تسهیل کند. در این فصل تئوری روشهای کاهش بعد PCA و LDA آموزش داده شده و سپس به صورت مرحله به مرحله در متلب پیاده سازی می شوند و در نهایت چندین پروژه عملی با کمک این الگوریتمها انجام می شود تا نحوه انجام پروژه های تخصصی با کمک این ابزار آشنا شویم.
ما تا فصل ششم بیشتر در مرحله آخر یک سیستم شناسایی الگو صحبت کردیم و تمرکزمان روی روشهای طبقهبندی و رگرسیون بود و در این حوزه الگوریتمهای زیادی را معرفی کردیم. در این فصل تمرکز ما روی روشهای کاهش بعد (PCA-LDA) در حوزه feature conditioning است.
همانطور که در فصل اول صحبت کردیم یک سیستم شناسایی الگو از چندین مرحله اساسی تشکیل شده است و برای اینکه بتوانیم پروژههای تخصصی انجام دهیم لازم است که در تمامی مراحل ابزارهای بهینه ای داشته باشیم. ما در این فصل یک مرحله عقب تر آمده ایم و روشهای کاهش بعد (PCA-LDA) در حوزه feature conditioning را توضیح داده ایم. ما در اکثر پروژههای تخصصی برای اینکه بتوانیم تصمیم گیری بهینه ای انجام دهیم، نیاز داریم که از داده ورودی(سیگنال- تصویر و ...) پارامترهای تاثیرگذار زیادی را استخراج کنیم. از آنجا که به طور دقیق نمیتوان در مسائل پیچیده مشخص کرد که چه فاکتور یا فاکتورهای موثر هستند و ارتباط مستقیمی با تسک مورد نظر دارند، نیاز داریم که فاکتورهای زیادی را به عنوان ویژگی استخراج کنیم. در این حالت ابعاد داده بسیار بالا می رود و باعث می شود تعداد پارامترهای طبقه بند یا الگوریتم رگرسیونی که برای تصمیم گیری استفاده میکنیم افزایش یابد و این ممکن است باعث شود که الگوریتم ما عمویت نداشته باشد یا به عبارتی generalized نباشد، که چالش اصلی ما در پروژه ها طراحی یک مدل generalized است. زیرا که ما روی sample کار میکنیم و میخواهیم مدل طراحی شده روی جمعیت کار کند. و وقتی تعداد پارامترهای مدل افزایش می یابد، به احتمال زیاد مدل ما generalized نخواهد شد. از طرفی ممکن است در پروسه استخراج ویژگی، ویژگی هایی استخراج شود که اطلاعات مفیدی برای مسئله نداشته باشد و یا تکراری باشند و اطلاعات جدیدی به مسئله اضافه نکنند و حتی ممکن است مرتبط با نویز باشند و کار تحلیل ما را خراب کنند. برای حل این مشکلات از روشهای feature conditioning استفاده می کنیم. تعداد ویژگیها را کاهش میدهیم. سوالی که ممکن است مطرح شود این است که آیا زمانی که تعداد ویژگی ها کاهش می یابد، اطلاعات ما نیز کاهش می یابد؟ که اگر این اتفاق بیافتد این امر منجر می شود که دقت کار کاهش یابد! به بیان دیگر میتوان سوال را این اینطور مطرح کرد که چرا کاهش بعد امکان پذیر است؟
سه تا عامل اصلی وجود دارد که باعث می شود کاهش بعد امکان پذیر باشد:
- نویز ممکن است هنگام ثبت داده یک سری اطلاعاتی ناخواسته همراه با سیگنال اصلی ثبت شود که ربطی به مسئله نداشته باشد و موقع استخراج ویژگی، ویژگی هایی ثبت شوند که مربوط به نویز باشند. پس باید ما چنین ویژگیهایی را حذف کنیم.
- اطلاعات نامرتبط ممکن است اطلاعاتی هنگام ثبت داده ثبت شود که مرتبط با مسئله نباشد، مثل background تصویر که ممکن است در اکثر مسائل ربطی به مسئله اصلی نداشته باشد، و موقع استخراج ویژگی، ویژگی هایی ثبت شوند که مربوط به مسئله و تسک نداشته باشند. پس باید ما چنین ویژگیهایی را حذف کنیم.
- اطلاعات تکراری(وجود redundancy ) ممکن است ویژگیهایی استخراج شود که اطلاعات جدیدی به مسئله اضافه نکند، با اینکه ویژگی خوبی است ولی اطلاعاتی که به مسئله میدهد همان اطلاعاتی باشد که در ویژگی یا ویژگیهای دیگر موجود باشد. پس وجود چنین ویژگیهایی هیچ کمکی به ما در حل مسئله نخواهند کرد و تنها باعث افزایش پارامترهای مدل طبقه بند یا رگرسیون شود. پس بهتر چنین ویژگی هایی را حذف کنیم. یا به عبارت دیگر ویژگیهایی را نگه داریم که اطلاعات مستقل و جدیدی در مورد مسئله ارائه می دهند.
روشهای feature conditioning شامل دو گروه feature mapping و feature selection است که هر کدام با یک رویکردی تعداد ویژگیها را کاهش میدهند. در شکل زیر نمایی از این روشها نشان داده شده است.
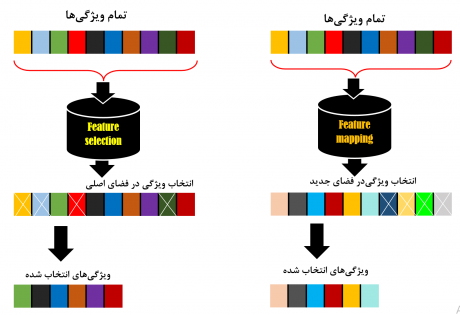
در روشهای feature mapping داده از یک فضایی به یک فضای جدید نگاشت پیدا میکند، به عبارت دیگر در این حوزه ویژگیها باهم ترکیب شده و ویژگیهای جدید را میسازند که تعداد این ویژگی ها نسبت به فضای اصلی کاهش می یابد. در حالی که در روشهای feature selection براساس یک سری معیارهایی تعدادی ویژگیها انتخاب می شوند که در این روشها نیز تعداد ویژگیها کاهش می یابد. ما در فصل ششم دوره پترن و یادگیری ماشین، روشهای feature mapping مثل PCA و LDA را معرفی می کنیم و به صورت تخصصی آموزش میدهیم که رویکرد تک تک روشها به چه صورت است و با انجام پروژه ها و مثالهایی که نشان میدهیم که این الگوریتم ها را در چه مسائلی و به چه صورت میتوانیم استفاده کنیم. علاوه بر این آموزش میدهیم که چطور میتوان از این الگوریتم ها در مسائل طبقه بندی استفاده کرد.
سرفصل مطالب
1- مقدمه ای بر Feature conditioning o تفاوت بین روشهای feature mapping و feature selection
همانطور که در ابتدا اشاره کردیم، ما دو دسته روش در حوزه Feature conditioning داریم. در جلسه اول فصل ششم تفاوت این دسته ها و همچنین مفاهیم اولیه مورد نیاز در این فصل ششم توضیح داده شده است. ویدیوی زیر بخشی از جلسه اول هست.
2- تئوری و پیاده سازی گام به گام الگوریتم کاهش بعد PCA( تجزیه مولفه های اساسی)
الگوریتم PCA یکی از معروف ترین روشهای کاهش بعد است که جزء دسته Linear feature mapping است. این روش براساس پراکندگی کار میکند و داده ها را در جهتی نگاشت می دهد که بیشترین واریانس باشد. روشهایی که براساس پراکندگی کار میکنند، فرضشان این است که ویژگیهایی که واریانس بیشتری دارند، حاوی اطلاعات مهمی از مسئله هستند. برای همین داده ها را در جهتی نگاشت میدهند که واریانس یا همان پراکندگی در آن جهت ماکزیمم شود.
این الگوریتم با دو هدف اساسی در پروژه ها استفاده می شود: کاهش بعد، کاهش افزونگی هدف اصلی این روش این است که با کمک ویژگیهای حوزه اصلی، ویژگی هایی را در فضای جدید ایجاد کند که کاملا مستقل از هم باشند. در این جلسه که خودش شامل 3 بخش هست، به طور تخصصی تئوری الگوریتم PCA از دو دیدگاه متفاوت آموزش داده می شود و سپس مرحله به مرحله در متلب پیاده سازی می شود. سپس مثل همیشه برای اینکه با عملکرد این الگوریتم به صورت مفهومی آشنا شویم چندین مثال ساده انجام میشود و در نهایت چندین پروژه ی تخصصی با کمک این الگوریتم انجام می شود تا متوجه شویم که چطور میتوانیم از این الگوریتم در پروژه های عملی و تخصصی استفاده کنیم. ویدیوی زیر بخشی از جلسه دوم است که در آن تئوری الگوریتم PCA از دیدگاه اول توضیح داده میشود.
3- تئوری و پیاده سازی گام به گام الگوریتم کاهش بعد LDA ( تجزیه مولفه های تفکیک پذیر خطی)
الگوریتم PCA با اینکه یک روش بسیار خوبی در اکثر مسائل هست، ولی از آنجا که به صورت غیرنظارتی کار می کند و همچنین رویکرد الگوریتم براساس پراکندگی است، ممکن است در بعضی مسائل با مشکل مواجه شود و خوب عمل نکند. ما این ایراد در جلسه دوم به صورت عملی نشان دادیم. ایراد این روش این است که تنها به پراکندگی داده نگاه می کند و ویژگی ای که پراکندگی کمتری دارد به منزله این است که اطلاعات مهمی ندارد و در ساخت ویژگیهای جدید سهم کمتری دارد. این در حالی است که ممکن است یک ویژگی ای که پراکندگی کمتری دارد، تفکیک پذیری بهتری داشته باشد و بتوان با کمک این ویژگی داده های دو کلاس یا چندکلاس را با دقت بالایی دسته بندی کرد. برخلاف الگوریتم PCA، الگوریتم LDA یک روشی است که با ناظر کار میکند و همچنین براساس تفکیک پذیری داده ها را به فضای جدید نگاشت میدهد. هدف این روش این است که برای نگاشت داده ها از فضای اصلی به فضای جدید، جهتی پیدا کند که بعد از نگاشت داده ها در آن جهت، داده ها در فضای جدید تفکیک پذیر باشند. به عبارت دیگر این روش میخواهد داده ها را طوری به فضای جدید نگاشت دهد که واریانس بین کلاسی داده ها در فضای جدید ماکزیمم و واریانس دورن کلاسی آنها حدقل شود. ما در این جلسه به صورت تخصصی در ابتدا رویکرد آقای فیشر در تجزیه مولفه های خطی تفکیک پذیر(LDA) را توضیح میدهیم و سپس مرحله به مرحله در متلب پیاده سازی می شود. سپس مثل همیشه برای اینکه با عملکرد این الگوریتم به صورت مفهومی آشنا شویم چندین مثال ساده انجام میشود و در نهایت چندین پروژه ی تخصصی با کمک این الگوریتم انجام می شود تا متوجه شویم که چطور میتوانیم از این الگوریتم در پروژه های عملی و تخصصی استفاده کنیم. ویدیوی زیر بخشی از جلسه سوم است که در آن تئوری الگوریتم LDA در مباحث دو کلاسه توضیح داده میشود.
ویدیوی زیر بخشی از جلسه چهارم است که در آن تئوری الگوریتم LDA در مباحث چندکلاسه توضیح داده میشود.4- تئوری و پیاده سازی گام به گام طبقه بند LDA
الگوریتم LDA علاوه بر اینکه در مباحث کاهش بعد استفاده می شود و نشان دادیم که چقدر عملکرد خوبی دارد، در مباحث طبقه بندی هم متیوان استفاده کرد. ما در این جلسه توضیح میدهیم که چطور میتوانیم از الگوریتم LDA در مباحث طبقه بندی استفاده کنیم. ویدیوی زیر بخشی از جلسه پنجم است که در آن توضیح می دهیم چطور میتوان از LDA به عنوان یک طبقه بند استفاده کرد.
5- تئوری و پیاده سازی گام به گام الگوریتم PCA جهت طبقه بندی داده ها
شاید برای خیلی از ماها طبقه بندی با LDA موضوع آشنایی باشد، ولی شاید خیلی ها نمیدانیم که از الگوریتم PCA میتواند به عنوان طبقه بند هم استفاده کرد. ما در این جلسه توضیح میدهیم که با چه ترفندی میتوانیم الگوریتم PCA را به عنوان طبقه بند استفاده کرد. ویدیوی زیر بخشی از جلسه ششم است که در آن توضیح می دهیم چطور میتوان از PCA به عنوان یک طبقه بند استفاده کرد.
محتوای پکیج:
- ویدیوهای آموزشی
- کدهای پیاده سازی شده برای پروژه ها، تمرینات و مقالات
- منابع معتبری که برای تهیه ویدیو استفاده شده اند(کتب و مقالات مرجع)
- جزوه دست نویس مدرس
فصل 1-4 : از بیزین تا SVM فصل 5: یادگیری جمعی(ensemble learning)
دوره های مرتبط

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)