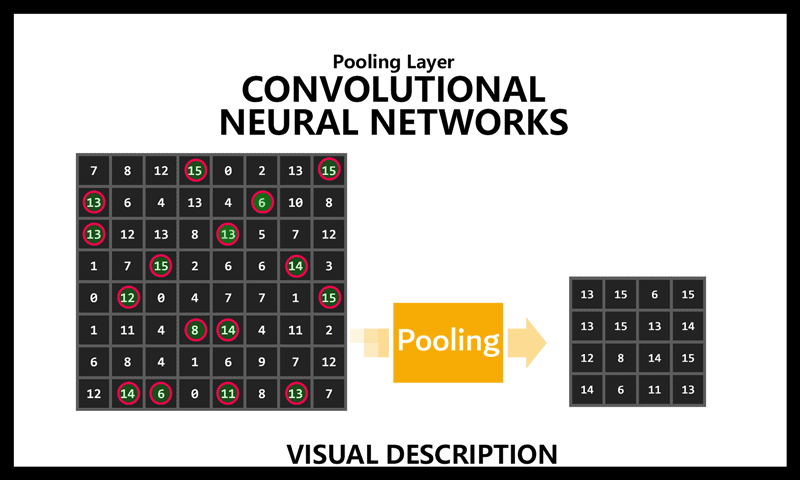
توضیح لایه Pooling در شبکههای عصبی کانولوشنالی CNNs
لایه Pooling یکی از اجزای کلیدی در معماری شبکههای عصبی کانولوشنال است که با کاهش ابعاد تصویر، ویژگیهای مهم آن را حفظ می کند. این لایه نه تنها پیچیدگی محاسباتی را به شدت کاهش میدهد، بلکه باعث بهبود تعمیمپذیری (Generalization) مدل و مقاوم بودن آن در برابر تغییرات مکانی نیز میشود. در این مقاله به زبان ساده و با مثال تصویری توضیح میدهیم که pooling دقیقاً چه کاری انجام میدهد. لایه پولینگ (pooling) به شبکه های عصبی CNNs کمک میکند که به جای فشرده سازی ساده، بهترین ویژگیها را استخراج کنند. در ادامه با انواع pooling (Max Pooling و Average Pooling)، تفاوت آنها با down-sampling ساده، چالشهای شبکه بدون pooling، و نحوه پیادهسازی آنها در PyTorch آشنا میشویم. همچنین به لایه Adaptive Pooling و کاربردهای مهم آن در Transfer Learning میپردازیم. اگر میخواهید عمیقاً درک کنید که چرا شبکههایی مثل AlexNet و LeNet-5 موفق شدند، مطالعه این مقاله اولین قدم مهم شماست.

از آنجا که شبکه های کانولوشن در مباحث تحقیقاتی و پروژه ای بسیار کاربردی هستند، قصد دارم در چندین پست آماده کنم که در آن با شبکه های کانولوشنالی، از اولین شبکه ی ارائه شده تا شبکه های مدرن کانولوشنالی به صورت مرحله به مرحله آشنا شویم. در هر بخش چالشهای موجود و نحوه حل آن با ساختارهای جدید را بررسی خواهیم کرد. کدهای هر کدام از شبکه های عصبی که توضیح داده میشود، در GitHub هم قرار خواهم داد تا به صورت منظم به هر کدام از این شبکه ها نیاز داشتید دسترسی داشته باشید. امیدوارم بتونم مباحث رو به خوبی برای شما منتقل کنم.
مطالعه پست قبلی: لایه کانولوشن در شبکه های کانولوشنالی
شیوه کار لایه Pooling در شبکه های کانولوشنالی
بیایید ابتدا یک شناخت کلی به عملکرد لایه پولینگ داشته باشیم، بعدش میریم سراغ جزئیات. لایه پولینگ، اندازه تصویر رو کاهش میده، اما ویژگی های خیلی مهم تصویر رو حفظ میکنه. در لایه های پولینگ فقط مسئله کاهش بعد نیست، بلکه این لایه کمک میکند شبکه عصبی تعمیم پذیر باشه، الگوی های کلیدی رو برجسته می کند، و پیچیدگی محاسباتی رو به شدت کاهش میدهد.
همانطور که در این ویدیو میبینیم این شخص میاد تصویر رو به نوارهای افقی و عمودی برش میزنه و چهار نسخه کوچکتر از اصلیش میسازه. درسته که کیفیتش (رزولوشن مکانی) کمتر میشه، ولی هنوز به اندازه کافی جزئیات داره که بشه تشخیصش داد. این فرایند دقیقاً شبیه همون چیزیه که تو pooling شبکههای عصبی کانولوشنی (CNN) اتفاق میافته.
مزایای لایه پولینگ
لایه Pooling اندازه تصویر رو کوچکتر میکنه ولی ویژگیهای مهمش رو نگه میداره. این کار فقط فشردهسازی نیست، بیشتر مثل عصاره گیری کردنه. با تمرکز روی عناصر برجسته، pooling به شبکه عصبی کمک میکنه:
- الگوهای کلیدی رو برجسته کنه
- پیچیدگی محاسباتی رو کم کنه
- تعمیم پذیری (generalization) رو بهتر کنه
چالش شبکه های کانولوشنالی بدون لایه Pooling
فرض کنید تصویری با اندازه 224×224×3 داریم. برای استخراج ویژگیهای قوی نیاز به چندین لایه کانولوشن داریم. همانطور که قبلا صحبت کردیم، شبکههای CNN سعی میکنند مسیر بینایی انسان را مدلسازی کنند که پردازش در آن به صورت سلسله مراتبی است (از ویژگیهای سطح پایین مثل لبه و نقطه تا ویژگیهای سطح بالا). در تصویر زیر این رویکرد به خوبی نمایش داده شده است (تصویر مربوط به دوره شبکه های کانولوشن همکارم خانم کاشفی هست. در این دوره شبکه های عصبی با تنسورفلو طراحی شده اند).
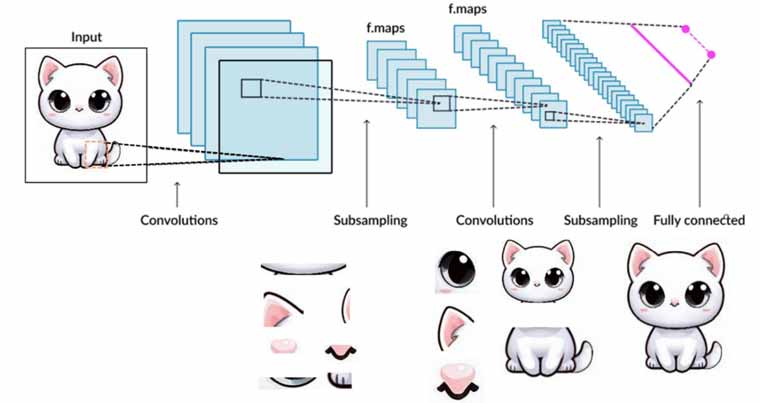
Image by H.Kashefi (CNN)
در پستهای بعدی بیشتر در مورد این مبحث صحبت خواهیم کرد و نشان خواهیم داد که هر چقدر تعداد لایه های کانولشن بیشتر شود، یا به عبارتی شبکه عصبی کانولوشنالی عمیق تر شود، توان و کارایی مدل افزایش خواهد یافت، اما چالشهای جدیدی اضافه خواهند کرد…
با افزایش عمق شبکه (تعداد لایهها) و عرض آن (تعداد کرنلها)، دو مشکل عمده ایجاد میشود:
- پیچیدگی محاسباتی بسیار بالا : آموزش شبکه تقریباً غیرممکن میشود.
- تعداد پارامترهای بسیار زیاد در لایهFully Connected : مثلاً در AlexNet خروجی لایه آخر کانولوشن به بردار با بیش از ۱۲ میلیون عنصر تبدیل میشود که باعث انفجار تعداد پارامترها و overfitting خواهد شد.
اگر اندازه تصویر همان اندازه ورودی باقی بماند و فرض کنیم همانند ساختار AlexNet ما 256 کرنل در آخرین لایه کانولوشن داشته باشیم. در نتیجه ما باید بیاییم تنسور سه بعدی (224×224×256) را به یک بردار تبدیل کنیم که میشود یک بردار به اندازه (1×12845056)!! هر کدام از نورونهای اولین لایه fully-connected باید 12845056+1 پارامتر داشته باشند!!!! عدد بسیار بزرگی هست. و میشه گفت تعداد پارامترها به معنای واقعی کلمه explode شده اند! و احتمال overfitting بسیااااار بالا خواهد بود!!!! البته اگه ram کافی برای این حجم از پارامتر داشته باشیم!!
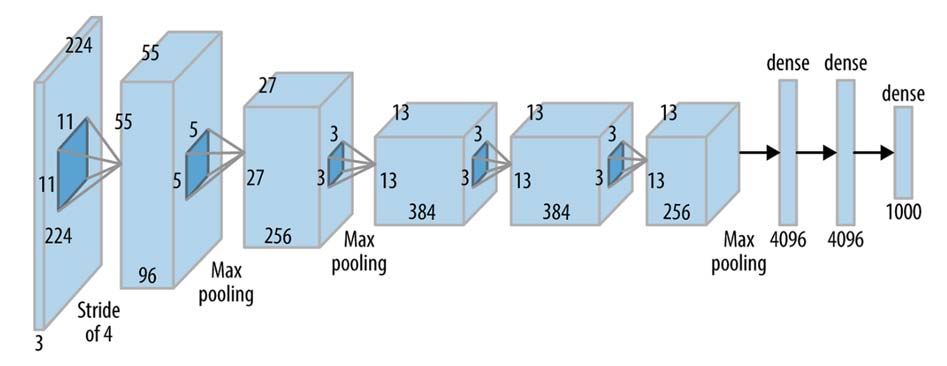
ساختار AlexNet که توسط Alex یکی از شاگردان جفری هینتون (یکی از سه پدرخوانده هوش مصنوعی) مطرح شده است که در پستهای بعدی در مورد این ساختار مفصل صحبت خواهیم کرد. جالب بدانید که بعد از ارائه این شبکه عصبی انقلابی بینایی ماشین اتفاق افتاد!
خب راه چاره چیه؟ down-sampling!
بریم سراغ down-sampling و به هر شکلی شده اندازه تصویر رو رفته رفته کم کنیم تا هم پیچیدگی محاسباتی کم شود و هم تعداد پارامترها به حد قابل قبول برسد!
ولی آیا به همین راحتی میشه down-sampling انجام داد؟؟ بگذارید اول با مفهوم down-sampling آشنا شویم، بعدش ایراد این رویکرد را توضیح میدهم.
مفهوم down-sampling در سیگنال
در down-sampling هدف ما کاهش تعداد نمونه های ثبت شده یک سیگنال یا تصویر هست و اینکار باید طوری انجام شود که اطلاعات زیادی از تصویر یا سیگنال اصلی را از دست ندهیم. اما در down-sampling ساده این امر احتمالش بسیار زیاد هست!
فرض کنید یک سیگنال (آبی رنگ) به شکل زیر داریم که طول آن 50 است. حال ما میخواهیم اندازه آنرا نصف کنیم. برای اینکار لازم هست که از 50 تا نمونه یکی در میان یک نمونه را برداریم و یک نمونه دیگر را بندازیم دور (یعنی اگر اطلاعاتی هم اگه داشته میندازیم دور!!). کاری که ما الان انجام دادیم down-sampling ساده هست. در شکل زیر فرایند نشان داده شده است. از بالا اولی سیگنال اصلی هست. دومی نقاط قرمزی که برای down-sampling در نظر گرفتیم. پایینی هم شکل نهایی سیگنال down-sample شده است که اندازه آن 25 شده است.
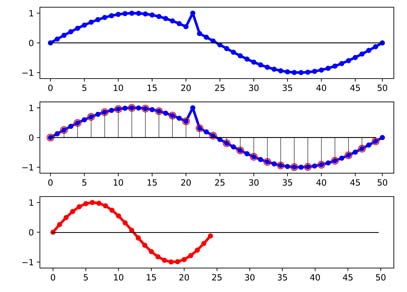
همانطور که دیدیم توانستیم سایز سیگنال را نصف کنیم، ولی تغییرات آنی رو نتونستیم در سیگنال جدید هم همچنان داشته باشیم. این ایراد down-sampling ساده هست.
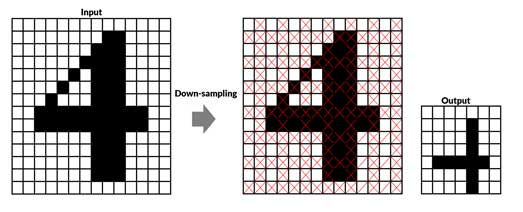
مفهوم down-sampling در تصویر
در تصویر هم همین روال هست، منتها اینجا به جای یک سیگنال یک بعدی، یک سیگنال دوبعدی یا به عبارتی تصویر داریم و برای down sampling هم لازم هست پیکسلها را یکی در میان کنار بگذاریم تا اندازه نصف شود.
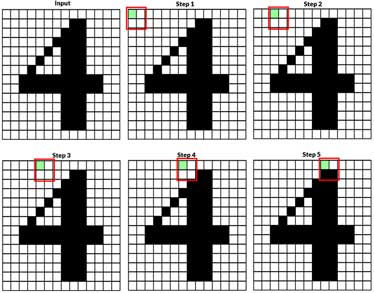
اگر فرض کنیم میخواهیم اندازه یک تصویر را نصف کنیم، برای این منظور یک پنجرهی 2×2 در نظر میگیریم و تمام پیکسلهای تصویر (بدون overlap، یعنی با stride=2) پیمایش میکنیم، و در هر پنجره مقدار یک پیکسل را انتخاب میکنیم. در شکل زیر چندین گام نشان داده شده است و در هر پنجره پیکسل انتخابی به رنگ سبز هست.
در تصویر زیر هدف کاهش ابعاد تصویر به ½ بوده هست. همانطور که دیده میشود، ابعاد تصویر نصف شده است و تا حدودی اطلاعات آبجکت در تصویر حفظ شده است.
ایراد down-sampling
از آنجا که در هر پنجره 2×2 فقط یک پیکسل استفاده میشود، اونم بدون در نظر گرفتن اهمیت پیکسل یا اهمیت سایر پیکسلها، و احتمال از دست دادن اطلاعات اصلی بسیار بالا میرود و این اصلا خوب نیست. حداقل اگر از بین 4 پیکسل اونی که مهمترین بود یا به عبارتی باارزشترین پیکسل بود انتخاب میشد باز احتمال از دست دادن اطلاعات کاهش پیدا میکرد. حال فرض کنید میخواستیم اندازه تصویر 4 برابر کم بشه، و از اونجا که در هر پنجره 4×4 فقط یک پیکسل انتخاب میشد، در این صورت احتمال حذف اطلاعات اصلی بسیار بالا میرفت.
راه حل در روشهای Pooling هستند. این روشها هم هدفشان کاهش بعد مکانی هست، اما به جای اینکه یک پیکسل بدون در نظر گرفتن اهمیتش انتخاب شود، سعی بر انتخاب مقدار مناسب به عنوان نماینده اون پنجره میکنند. از طرفی همانطور که در ابتدا گفت، حساسیت مدل به تغییرات جزئی مکانی کم میکنه، در نتیجه مدل خاصیت تعمیم پذیری بالایی هم خواهد داشت.
لایه pooling در شبکه های عصبی کانولوشنالی
نکته: ویدیو در یوتیوب بارگزاری شده است.
در شبکه های عصبی کانولوشنی بعد از اعمال لایه کانولوشن (مخصوصا ساختارهای ابتدایی مثل LeNet-05, AlexNet) یک لایه پولینگ جهت کاهش ابعاد مکانی تصاویر اعمال میکنند. این روال به شکل زیر هست.
Conv1→ BN→ReLU→Pooling→Conv2→BN→ReLU→Pooling→ ….
انواع لایه pooling در شبکه های عصبی کانولوشنالی
به طور کلی به دو شکل pooling انجام میشود:
- average pooling: در هر پنجره میانگین پیکسها را انتخاب میکند.
- max pooling: در هر پنجره مقدار max پیکسلها را انتخاب میکند.
لایه average pooling
لایه average/mean pooling توسط یان لینکان (یکی از سه پدرخوانده های هوش مصنوعی) در مقاله معروف LeNet-05 معرفی شد. این لایه ها بعد از هر لایه کانولوشن قرار داشتند که هدفشان کاهش پیچیدگی محاسباتی (با کاهش ابعاد مکانی) و همچنین مقاوم کردن مدل به تغییرات مکانی کوچک بوده است.
برای درک بهتر نحوه طراحی و پیاده سازی این لایه ها یک مثال عملی میزنم. فرض کنید یک تصویر داریم و مقادیر داخل آن به صورت زیر هست.
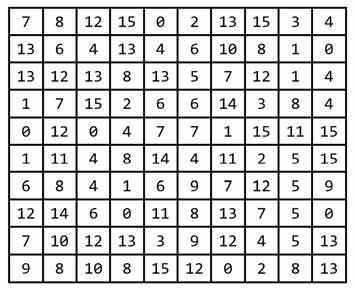
حال هدف ما این است که با کمک average pooling کاهش بعد روی آن انجام دهیم. روال به این شکل هست که بسته به میزانی که میخواهیم کاهش بعد دهیم، اندازه پنجره را در نظر میگیریم، برای مثال اگر هدف نصف کردن ابعاد مکانی باشد، اندازه پنجره را 2×2 در نظر میگیریم. حال دو حلقه به تعداد سطر و ستونهای تصویر مینویسیم، منتها با stride=2 که overlap بین پنجره ها نباشد. بعدش شروع میکنیم به پیمایش پیکسلهای تصویر. در هر تکرار یک پنجره از تصویر جدا شده، میانگین آنها حساب میشود و حاصل در آدرس متناظر (در تصویر کاهش بعد یافته) قرار میگیرد. روال به صورت شکلی برای چند مرحله نمایش داده شده است.
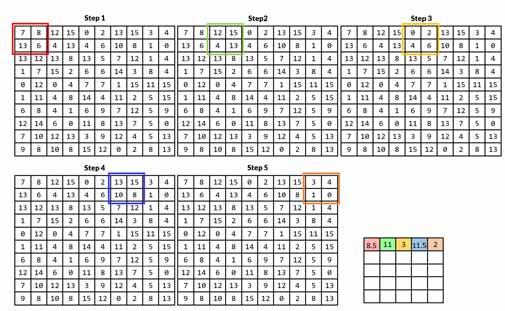
جزئیات بیشتر در ویدیو (بالا) نشان داده شده است.
نحوه طراحی لایه average pooling در پایتورچ
Python
from torch import nn avg_pool_layer= nn.AvgPool2d(kernel_size=(2,2),stride=2)
kernel_size: اندازه پنجره برای اعمال pooling
stride: گام پیمایش پیکسلها، اگر نمیخواهیم بین پنجره ها overlapی باشد، پس باید اندازه stride برابر با kernel_size باشد که در حالت default هم به این شکل در نظر گرفته شده است.
لایه maxpooling در شبکه های کانولوشنالی (CNNs)
در max pooling، به جای محاسبه میانگین پیکسلها، مقدارماکزیمم انتخاب میشود. این نوع لایه بعدها ارائه شده است و در مطالعات مختلف نشان داده است که در مقایسه با average pooling عملکرد بهتری دارد و برای همین هست که در بسیاری از مطالعات جدید مثل AlexNet که یکی از معروفترین شبکه های کانولوشنی هست، از این نوع استفاده شده است. البته در ساختار AlexNet به جای maxpooling با اندازه 2×2 و stride=2 که پنجره ها overlap ندارند، از پنجره 3×3 با stride=2 با داشتن overlap بین پنجره ها استفاده شده است.
در شکل زیر چند مرحله از max-pooling با اندازه پنجره 2×2 و stride=2 (بدون overlap) نشان داده شده است.
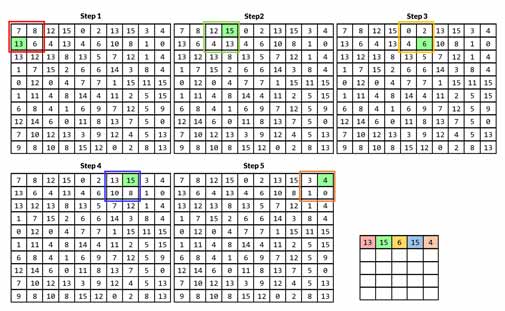
جزئیات بیشتر در ویدیو (بالا) نشان داده شده است.
نحوه طراحی لایه maxpooling در پایتورچ
Python
from torch import nn max_pool_layer1= nn.MaxPool2d(kernel_size=(2,2),stride=2) max_pool_layer2= nn.MaxPool2d(kernel_size=(3,3),stride=2)
در حالت اول کرنل ها 2×2 با stride=2 بدون overlap خواهند بود. اما در دومی کرنلها 3×3 با stride=2 یک پیکسل overlap باهم خواهند داشت.
کد پایتون جهت طراحی و اعمال لایه پولینگ روی یک تصویر
نتیجه اعمال سه نوع pooling روی تصویر lena را در زیر مشاهده میکنید.
Python
from torch import nn avg_pool_layer= nn.AvgPool2d(kernel_size=(2,2),stride=2) max_pool_layer1= nn.MaxPool2d(kernel_size=(2,2),stride=2) max_pool_layer2= nn.MaxPool2d(kernel_size=(3,3),stride=2) img_pooled_avg= avg_pool_layer(img_t) img_pooled_max1= max_pool_layer1(img_t) img_pooled_max2= max_pool_layer2(img_t)

توجه داشته باشید که در لایه های پولینگ، عملیات روی هر کانال تصویر به صورت مستقل و جدا اندازه میشود و تنها ابعاد تصویر از لحاظ مکانی کاهش مییابد.
از آنجا که تصویر lena یک تصویر سطح خاکستری (فقط یک کانال دارد)، لذا فقط روی تک کانال انجام میشود و ابعاد از لحاظ مکانی کاهش میابد.
لایه adaptive average pooling
در لایه های قبلی، کاربر تنها میتوانست اندازه کرنل و گام پیمایش را کنترل کند. پس ما به صورت مستقیم کنترلی روی اندازه تصویر خروجی نداریم و این کاملا به تصویر ورودی بستگی دارد. برای مثال اگر ما اندازه کرنل را 2×2 با stride=2، در نظر بگیریم و تصویر ورودی به ابعاد 200×200×32 باشد، تصویر خروجی 100×100×32 خواهد بود و اگر 50×50×32 باشد، تصویر خروجی 25×25×32 خواهد بود. پس میبینیم که ما کنترل مستقیمی روی اندازه تصویر خروجی نداریم. ولی باید در نظر بگیریم که به دلایل مختلفی (مثل transfer learning) در برخی جاها ما نیاز داریم اندازه تصاویر خروجی همیشه ثابت باشد. چه تصویر ورودی 200×200 باشد و چه 50×50 باشد، میخواهیم تصویر خروجی به اندازه مثلا 15×15 باشد. خب برای اینکار لایه ای به نام adaptive pooling مطرح شده است. که این امکان را میدهد کاربر اندازه خروجی را به هر اندازه ای که میخواهد تبدیل کند.
در این نوع لایه، کاربر اندازه تصوویر خروجی را مشخص میکند، و این لایه میاد تصویر ورودی را به تعداد مساوی تقسیم میکند و برای هر ناحیه pooling را انجام میدهد. برای مثال اگر بخواهیم تصویر خروجی 2×2 باشد، در این صورت به 4 بخش همانند زیر تقسیم شده و pooling انجام میشود. در این مثال، adaptive average pooling انجام شده است.
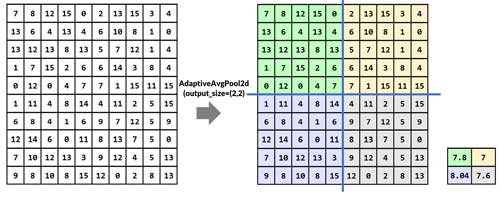
نحوه طراحی لایه adaptivepooling در پایتورچ
لازم به ذکر هست که هم adaptive max pooling، و هم adaptive average pooling در پایتورچ وجود دارد که استفاده از حالت average رایجتر است.
Python
from torch import nn Ad_max_pool_layer= nn.AdaptiveMaxPool2d(output_size=(2,2)) Ad_avg_pool_layer= nn.AdaptiveAvgPool2d(output_size=(2,2))
output_size اندازه مکانی (تعداد سطرها و ستونها) تصویر خروجی را مشخص میکند.
کاربردهای Adaptive pooling
لایه adaptive pooling کاربردهای زیادی دارد که در ادامه پستها با معرفی ساختارهای جدید باهاشون آشنا خواهیم شد، ولی اگه بخوام دو تا از کاربردهای مهمش رو معرفی کنم موارد زیر هستند:
- کمک به transfer learning
- کاهش پارامترهای شبکه عصبی
یکی از مهمترین کاربردهای adaptive pooling در مسئله transfer learning هست. شرکتهای مختلف، به خاطر داشتن امکانات خوب، مدلهای عمیقی را برای مسائل مختلف آموزش داده و در دسترس عموم قرار داده اند. این شبکه ها در حوزه خاص، به خاطر داده های وسیعی که بهشان داده اند، دانش خیلی خوبی در وزنهای سیناپسی خود دارند. حال شما میخواهید از آن شبکه در کار خودتون استفاده کنید. اما مشکل اینجاست که اندازه تصویر ورودی شما با اندازه تصویر آنها برابر نیست. برای مثال تصویر شما اندازه اش 100 در 100 هست ولی شرکتها روی داده 200 در 200 مدل را آموزش داده اند. خب در لایه های پولینگ و کانولوشن مشکلی پیش نخواهد آمد، ما در لایه های fully-connect به خاطر تغییر اندازه بردار ویژگی به مشکل خواهید خورد!
برای حل این مسئله شما قبل از برداری کردن داده، میتوانید از یک لایه adaptive pooling استفاده کنید تا بردار ویژگی همسایز شرکتها ساخته شود و بتوانید از لایه های fc از پیش آموزش دیده (pre-trained) در کار خودتون استفاده کنید.
کاربرد بعدیش این است که شما ساختاری میخواهید که تعداد کمی لایه fully-connected در شبکه عصبی باشد. یکی از دلایل واضحش اینه که بیشترین پارمترهای یک شبکه کانولوشنالی را همین لایه ها تشکیل داده اند. برای همین شما به جای این لایه ها میخواهید یک لایه adaptive average pooling بزنید. این لایه پارامتری ندارد! معنیش این نیست که لایه میتونه همانند لایه های fully-connected خوب عمل کند، ولی اگر یک trade-offی بین عملکرد و تعداد پارامترها بخواهیم لحاظ کنیم، این لایه گزینه ی خیلی خوبی هست. چرا که این لایه تقریبا همانند لایه های fully connected ویژگی های استخراج شده به صورت محلی توسط لایه های کانولوشن را میتواند به صورت globally ترکیب کند. در مورد این مسئله در پستهای بعدی بیشتر صحبت خواهیم کرد.
خب ما دو تا از لایه های شبکه های کانولوشنی را بررسی کردیم و بعد از بررسی لایه های fully-connected میتونیم اولین شبکه ی عصبی کانولوشنالی LeNet-05 را پیاده سازی میکنیم. در پست بعدی fully connected ها و نقش آنها در شبکه های کانولوشنی را بررسی کرده و سپس شبکه عصبی lenet را در پایتورچ پیاده سازی خواهیم کرد.
نقش لایه pooling در CNNs
لایه های پولینگ با حفظ اطلاعات ابعاد مکانی را کاهش میدهند و با کاهش پیچیدگی محاسباتی امکان توسعه شبکه های عصبی عمیق را فراهم میسازند. جالب است بدانید که لایه های پولینگ نه تنها به کاهش بعد و پیچیدگی محاسباتی سیستم کمک میکنند، بلکه کارایی مدل را هم افزایش میدهند. بدین ترتیب که این لایه ها مدل را به تغییرات مکانی کوچک مقاوم میکنند و در نتیجه به مدل کمک میکنند که آبجکت اگر در تصاویر مختلف، از لحاظ موقعیت مکانی تغییر کند، باز سیستم کار شناسایی را به درستی انجام دهد.
میشه گفت، لایه های پولینگ در شبکه های عصبی کانولوشنالی همانند Complex cells ها در مسیر بینایی عمل میکنند.
دوستان عزیزم، مباحث گفته شده بخشی کوتاه از دوره جامع و تخصصی یادگیری عمیق هست.
ما در دوره یادگیری عمیق، ابتدا شبکه های عصبی عمیق را کاملا به صورت دستی پیاده سازی میکنیم و بعدش میریم سراغ ابزارهای آماده در پایتورچ. و برای پیاده سازی دستی هم، اول ریاضیات و اثبات روابط، بعدش نمایش ماتریسی عملیات، را کامل یاد میگیریم. در آخر هم بعد از معرفی ابزار پایتورچ پروژه های عملی مختلف در زمینه های پردازش تصویر، پردازش سیگنال و پردازش متن انجام میدهیم تا با چالشهای واقعی انجام پروژه به صورت عملی آشنا شویم.
دوستانی که قصد یادگیری تخصصی و عمیق شبکه های عمیق هستند، پیشنهاد میکنم دوره جامع یادگیری عمیق مارا نگاه کنند. در این دوره که بیش از یک سال طول کشید تا مباحث آماده شود، سعی کردیم مباحث مهم و کاربردی را همه از لحاظ تئوری و هم از لحاظ عملی آموزش دهم و تا درک تخصصی از این ابزار بدست بیاریم و بتونیم از آنها در انجام پرژه ها به خوبی استفاده کنیم و از همه مهمتر بتونیم این شبکه ها را توسعه دهیم. چه از لحاظ ریاضیات و چه از لحاظ ساختار در کاربردهای مختلف.
دوره های مرتبط

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

اصول برنامه نویسی پایتون Python

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

[…] مطالعه پست قبلی: لایه pooling در شبکه های کانولوشنالی […]