
توضیح لایه کانولوشن در شبکه های عصبی کانولوشنالی CNNs
شبکه های عصبی کانولوشنالی (convolutional neural networks) یکی از مهمترین ابزار بینایی ماشین، پردازش تصویر، حتی پردازش سیگنال هستند. بعد از ظهور شبکه های عصبی CNNs، انقلاب بزرگی در حوزه بینایی ماشین و بعد در سایر حوزه ها اتفاق افتاد. امروزه کاربردهای شبکه های عصبی کانولوشنالی را در همه جا میشه دید، از بحث بینایی ماشین در زندگی روزمره مثل کنترل ترافیک، تشخیص پلاک خورو، ماشینهای خودران، و در بحثهای مهمتر مثل پزشکی که از CNNها به صورت فزاینده ای جهت تحلیل تصاویر و سیگنالهای پزشکی استفاده میشود. شبکه های عصبی CNN به طور کلی از سه لایه کانولوشن (convolution)، لایه پولینگ (pooling) و لایه های fully-connected تشکیل شده اند. لایه های کانولوشن بخش اصلی CNNs هست. در این بخش قصد داریم با لایه کانولشن و نحوه طراحی آن در محیط پایتورچ-PyTorch آشنا شویم.

از آنجا که شبکه های کانولوشن در مباحث تحقیقاتی و پروژه ای بسیار کاربردی هستند، قصد دارم در چندین پست آماده کنم که در آن با شبکه های کانولوشنالی، از اولین شبکه ی ارائه شده تا شبکه های مدرن کانولوشنالی به صورت مرحله به مرحله آشنا شویم. در هر بخش چالشهای موجود و نحوه حل آن با ساختارهای جدید را بررسی خواهیم کرد. کدهای هر کدام از شبکه های عصبی که توضیح داده میشود، در GitHub هم قرار خواهم داد تا به صورت منظم به هر کدام از این شبکه ها نیاز داشتید دسترسی داشته باشید. امیدوارم بتونم مباحث رو به خوبی برای شما منتقل کنم.
لازم به ذکر هست که مباحثی که در پستها آورده میشوند، بخش کوتاهی از دوره جامع و تخصصی یادگیری عمیق هست. در فصل 3 دوره یادگیری عمیق شبکه های عصبی کانولوشنالی را آموزش داده ایم. اگر هدفتون یادگیری عمیق و تخصصی این مباحث هست، پیشنهاد میکنم حتما دوره را نگاه کنید. در دوره ریاضیات و اثبات روابط پس انتشار خطا، مفاهیم، ساختارها و عملیات با تمام جزئیات آموزش داده شده است و همچنین برای درک بهتر شبکه های عمیق، ابتدا خودمان کاملا دستی شبکه ها را (بعد از اثبات روابط ریاضیاتی شبکه های عصبی) پیاده سازی میکنیم. بعدش ابزار پایتورچ را معرفی کرده و پروژه های مختلف در زمینه پردازش تصویر، پردازش سیگنال و پردازش متن انجام میدهیم تا هم با کابرد هر شبکه و هم با چالشهای استفاده از آن در عمل آشنا شویم.
در این پستها تا جایی که امکانش هست مفاهیم و ساختارها توضیح داده خواهند شد، برای درک ریاضیات و مفاهیم با جزئیات بیشتر و آشنایی با پروژه های عملی مختلف بهتر است دوره یادگیری عمیق را نگاه کنید.
برای اینکه بتوانیم درک درستی از ساختارهای شبکه های کانولوشنی داشته باشیم، بهتر است ابتدا با مفاهیم پایه آشنا شویم. برای همین در ادامه به صورت مختصر این مفاهیم پایه را توضیح خواهم داد.
فرایند دیجیتال کردن تصویر
یک تصویر دیجیتال همانند زیر ساخته میشود. در این فرایند دو تا عمل نمونه برداری و کوانتیزه سازی انجام میشود.

نمونه برداری تصویر: در این فرایند یک فضای مکانی نامحدود به اطلاعات مکانی محدود قابل ذخیره در کامیپوتر تبدیل میشود. درست همانند نمونه برداری یک سیگنال که در آن سیگنال آنالوگ به یک سیگنال گسسته دیجیتال تبدیل میشود. تصویر نمونه برداری شده از شبکه ای از پیکسلها تشکیل شده است که هر کدام از پیکسها یک مقدار (شدت روشنایی) یا چندین مقدار (رنگ rgb) را دارند. از کنار هم قرار گرفتن پیکسلها با مقادیر مختلف، اشکال در تصویر دیجیتال ساخته میشود.
در فرایند کوانتیزه سازی هم شدت روشنایی/رنگ در رنج پیوسته وسیع، به یک رنج محدود تبدیل میشود.
تصویر دیجیتال
همانطور که گفته شد یک تصویر دیجیتال از تعدادی پیکسل تشکیل شده است که تعداد آن ابعاد تصویر و مقادیر داخل آنها هم اشکال تشکیل دهنده یا به عبارتی محتوای داخل تصویر را مشخص میکند.

اطلاعات مکانی در درک تصویر بسیار مهم هست.
باید به این نکته خیلی مهم توجه کنیم که در تصویر دیجیتال، پیکسلها همراه با سایر پیکسلهای مجاور اشکال خاص را تشکیل میدهند. به عبارتی از کنار هم قرار گرفتن پیکسل اشکال مختلف ساخته میشود. پس اطلاعات مکانی (همسایگی هر پیکسل) در تحلیل تصویر بسیار مهم و حیاتی هست و هر روشی که میخواهد با پردازش این پیکسلها محتوای تصویر را رمزگشایی کند، لازم هست که حتما پیکسلهای مجاور هر پیکسل را نیز در نظر بگیرید.
انواع تصویر دیجیتال
به طور کلی میتوان تصاویر را به سه دسته باینری، سطح خاکستری و رنگی دسته بندی کرد.

تصویر باینری/سیاه سفید: یک آرایه دو بعدی هست که مقادیر پیکسلها یا صفر (سیاه) و یا 1 (سفید) هست.
تصویر سطح خاکستری: یک آرایه دو بعدی هست که مقادیر پیکسلها بین صفر (سیاه) تا 1 (سفید) هست. در مجموع 256 شدت روشنایی وجود دارد که این مقدار هرچقدر به یک نزدیک باشد روشنتر و هر چقدر به صفر نزدیک باشند تیره تر خواهند بود.
تصویر رنگی: از سه آرایه دو بعدی تشکیل شده است (یا همان آرایه سه بعدی) که هر کدام از این آرایه های دوبعدی مربوط به یکی از سه رنگ قرمز، سبز و آبی هست. مقادیر هم هر کدام بین صفر و یک هست که میزان آن رنگ را برای پیکسل مورد نظر مشخص میکند. به عبارتی هر پیکسل شامل سه مقدار هست که مقادیر آنها رنگ پیکسل را مشخص میکنند.
صورت مسئله: درک محتوای تصویر

فرض کنید ما تصاویر دیجیتال به شکل بالا از اعداد به صورت دست نویس شده داریم. اندازه هر تصویر 28 در 28 هست. یعنی 28 ستون و 28 سطر از پیکسلها داریم که در مجموع 784 پیکسل هر تصویر را تشکیل میدهد. حال ما میخواهیم یک سیستمی طراحی کنیم بتواند با پردازش مقادیر این تصویر درک کند که داخل تصویر چه عددی هست. در مجموع هم 10 عدد از 0-9 وجود دارد. یعنی یک مسئله 10 کلاسه داریم و مدل ما باید بتواند با پردازش تصویر متوجه شود که داخل تصویر چه عددی نوشته شده است.
رویکرد اول: استفاده از لایه های fully connected (همان لایه های شبکه عصبی پرسپترون چند لایه)

اگر بخواهیم از لایه های fully connected در شبکه عصبی MLP استفاده کنیم، لازم است که تصویر را به یک بردار تبدیل کنیم و بعد به شبکه عصبی بدهیم. یعنی یک تصویر 28*28 را به یک بردار 784*1 تبدیل کنیم. که این کار باعث دو مشکل اساسی میشود.
اول اینکه الگوی مکانی اعداد داخل تصویر بهم میخورد و عملا یک تصویر با اطلاعات خوب را به یک بردار درهم و پیچیده تبدیل میکنیم که تشخیص اعداد از روی آن برای هر مدلی بسیار سخت خواهد بود.
از طرف دیگه از آنجا که در لایه های Fully connected هر نورون به همه ورودی ها وصل میشود، عملا تعداد پارامترهای بسیار زیادی خواهیم داشت که احتمال overfitting شبکه عصبی را بسیار بالا میبرد. حالا فرض کنید تصویر ورودی 500*500 باشه، در اونصورت دیگه تعداد پارامترها دیگه از کنترل خارج خواهد شد و عملا آموزش امکان پذیر نخواهد بود.
ایراد اول: تعداد پارامترهای بیش از اندازه
خود این دو مشکل اساسی ایجاد میکند. اول اینکه چون تعداد پارامترها زیاد هست، احتمال overfitting بسیار بالاست!! و در خیلی از موارد واقعا آموزش چنین شبکه ای امکان پذیر نیست. دوم اینکه اگر فرض کنیم شبکه عصبی یاد گرفته است و بخواهیم پارامترهای آنرا ذخیره کنیم و در برنامه های موبایلی استفاده کنیم RAM خیلی زیادی نیاز خواهیم داشت که درگذشته چنین امکان سخت افزاری وجود نداشت.
مشکل دوم: از بین رفتن اطلاعات مکانی
یک تصویر از شبکه ای از پیکسلها تشکیل شده است که مقادیر آنها محتوای اشیائ داخل تصویر را مشخص میکند. به عبارتی از کنار هم قرار گرفتن پیکسلها در مجاورت هم، اشکال خاص ساخته میشود. برای مثال الگوی پیکسلها برای عدد یک و دو کاملا متفاوت هست و همین تفاوت هست که به ما کمک میکند که بتوانیم عدد یک را از دو تفکیک کنیم. همین قائده برای الگوریتم یادگیری ماشین/شبکه های عصبی هم باید لحاظ شود. الگوریتمی که طراحی میکنیم باید در فرایند استخراج ویژگی یا تصمیم گیری، اطلاعات مکانی را لحاظ کند. در غیر اینصورت حل مسئله برای مدل بسیار بسیار چالش برانگیز خواهد بود.
پس رویکرد اول از هر لحاظ نگاه کنیم برای پردازش تصویر اصلا گزینه مطلوب نیست. خب باید چیکار کرد؟؟!! این دقیقا سوال هابل و ویزل بود که تصمیم گرفتند مغز رو بررسی کنند تا ببینند مغز تصاویر را چطور پردازش میکند. تا با الهام گرفتن از آن بتوانند به این سوال بنیادین جواب بدهند.
مسیر بینایی و اکتشاف هابل و ویزل
در دههٔ ۱۹۶۰، دو دانشمند جوان به نامهای David Hubel (کانادایی) و Torsten Wiesel (سوئدی) در دانشگاه Johns Hopkins، همکاری ای را آغاز کردند که بعدها یکی از مهمترین کشفیات علوم اعصاب و بینایی ماشین را رقم زد.
مطالب مرتبط : چگونه کشف اتفاقی Hubel و Wiesel پایهگذار بینایی ماشین و شبکههای عصبی کانولوشنی شد
هدف آنها این بود که بفهمند قشر بینایی مغز چطور تصاویر را پردازش میکند. سوال اینها این بود که یک نورون در قشر بینایی اولیه (V1) چطور به محرکهای تصویری واکنش نشان می دهد. با درک این میتونستند به سوال اصلی یعنی نحوه پردازش اطلاعات بصری (تصاویر) جواب بدهند.

این دو دانشمند میکروالکترود را وارد یک نورون در V1 کردند و شروع کردند به نمایش الگوهای نور و تاریکی.
سیگنالهای نورون به صورت صداهای فایرینگ (click-like spikes) روی اسپیکر ضبط میشد؛ هر بار که نورون فعال میشد، یک “تق تق” واضح شنیده میشد.
در یکی از جلسات، به صورت تصادفی هنگام قرار دادن یک اسلاید کاغذی در پروژکتور، یک لبهٔ باریک روشن روی صفحه افتاد. ناگهان نورون شروع کرد به فایر کردن!
در همان لحظه، آنها فهمیدند که نورونهای V1 به کل صفحه حساس نیستند، بلکه هر کدام از نورونها یک میدان دیدی (receptive field) دارند، یعنی فقط به لبهها، آن هم در جهت خاص و در موقعیت خاص پاسخ میدهند.
هابل و ویزل کشف کردند که اولا پردازش ها در مسیر بینایی به صورت سلسله مراتبی انجام می شود و از طرفی هر نورون (سلول عصبی) در مغز به محرک بصری خاصی حساس هست. یعنی هر سلول یک میدان دید خاصی (receptive field) دارد.
هابل و ویزل دقیقاً نشان دادند:
- هر نورون در V1 یک Receptive Field محدود دارد
- نورونها به لبهها و جهتهای خاص حساساند
- برخی نورونها “Simple Cells” هستند (حساس به مکان + جهت)
- برخی دیگر “Complex Cells” (حساس به جهت، مستقل از مکان)
- مغز ساختار سلسلهمراتبی دارد:
شیء→شکل→ لبه
فیلترهای گابور
فیلترهای گابور اولین الگوریتمهایی بودند که براساس یافته ی هابل و ویزل طراحی شد. که در الگوریتم معروفی به نام Hmax که مدل ساده شده مسیر بنیایی هست استفاده کردند. در الگوریتم Hmax در چهار مرحله یک تصویر را پردازش میکرد. در اولین لایه این مدل، از فیلترهای گابور استفاده شده بود.

ایراد فیلترهای گابور
ایراد اساسی فیلترهای گابور، جدا از پیچیدگی محاسباتی که دارند، ثابت بودن مقادیر آنها هست. یعنی مقادیر داخل هر فیلتر گابور ثابت هست و قابلیت یادگیری ندارند. همین باعث میشود که عملا نتوان یک سیستم خیلی خوب برای مسائل طراحی کرد. برای داشتن یک سیستم قوی، لازم هست که مدل براساس داده خاص، مقادیر منحصر به فرد به اون داشته باشد تا بتواند مسئله را به خوبی حل کند.
از طرفی چون قابلیت یادگیری ندارند، امکان افزایش طولی و عرضی شبکه عصبی وجود ندارد و نمیتوان یک سیستم عمیق طراحی کرد. واقعیت این است که فقط با یک لایه از فیلترها نمتیوان مسائل پیچیده بینایی ماشین را حل کرد، ثابت شده که برای افزایش توان سیستم لازم هست تعداد لایه ها بسیار زیاد باشد.
پس عملا برای مسائل واقعی روز دنیا که بسیار چالشی و پیچیده هستند با فیلترهای گابور کارمون به جای خوب نمیرسه و باید فکر دیگه ای بکنیم.
شبکه ی عصبی کانولوشنالی LeNet-05
آقای یان لیکان و همکارانشون با الهام گرفتن از اکتشاف هابل و ویزل برای مسیر بنیایی، شبکه عصبی کانولوشنالی LeNet-05 را مطرح کردند.

در ساختار ارائه شده آنها، تصویر همانند مسیر بینایی به صورت سلسله مراتبی پردازش میشود. در این ساختار لایه های کانولوشن مطرح شده اند که همانند simple and complex cells ها در مسیر بینایی عمل میکنند و برخلاف فیلترهای گابور ساده تر هستند و از همه مهمتر، قابلیت یادگیری دارند.
در این ساختار، استخراج ویژگی و طبقه بندی هر دو همزمان توسط شبکه عصبی انجام میشود. با کمک لایه های Convolution و pooling عمل استخراج ویژگی (البته ویژگی های local استخراج میشود) و با کمک لایه های fully connected عمل طبقه بندی انجام می شود (البته لایه های fc ویژگی های ساخته شده به صورت محلی را به صورت global باهم ترکیب کرده و ویژگی های غنی تری میسازند و در انتها هم از روی آنها دسته بندی را انجام میدهند، به وقتش در مورد این موضوع صحبت خواهم کرد).
در این پست میخواهیم با لایه های کانولوشن این ساختار آشنا شویم و برای همین مفاهیم مرتبط با فیلترینگ مکانی را توضیح میدهیم. بقیه ساختار در پستهای بعدی توضیح داده خواهد شد.
مفهوم کانولوشن در پردازش تصویر
کانولوشن اثر یک سیگنال در سیگنال دیگری را محاسبه میکند. کانولوشن بین دو سیگنال طبق رابطه زیر محاسبه میشود.

نحوه اعمال فیلتر مکانی روی یک تصویر
در فیلترینگ مکانی ابتدا یک کرنل به اندازه خاص (برای مثال 3*3) در نظر گرفته میشود، سپس روی تصویر اعمال می شود. به این ترتیب که یک همسایگی 3*3 هر پیکسل را جدا میکنیم، به صورت نظیر به نظیر با مقادیر کرنل ضرب کرده و حاصل جمع آنها را در آدرس متناظر در تصویر خروجی قرار میدهیم. نحوه اعمال فیلترینگ مکانی روی یکی از پیکسلها در تصویر نمایش داده شده است.

این عمل به ازای همه پیکسل های تصویر اصلی انجام میشود. و اینکه مقادیر کرنل چی باشند، تصویر خروجی متفاوتی ساخته خواهد شد. ما معمولا مقادیری را برای کرنل در نظر میگیریم که اطلاعات مدنظر از تصویر ورودی را استخراج کنیم. برای مثال در کرنل زیر، هدف استخراج لبه های تصویر اصلی در جهت خاص هست. اما در شبکه های عصبی قرار هست، مقادیر کرنلها توسط خود شبکه ی عصبی محاسبه شوند.
فرق بین کانولوشن و cross correlation
در عمل کانولوشن اول کرنل به اندازه 180 درجه چرخش داده میشود و سپس روی تصویر اعمال میشود، ولی در cross correlation چرخشی انجام نمیشود.
از لحاظ تکنیکی و پیاده سازی، در شبکه های عصبی برای سادگی محاسبات از عمل cross correlation استفاده میشود. اما از آنجا که مقادیر فیلتر/کرنل توسط شبکه محاسبه میشود، برای همین از لحاظ نظری و تئوری هم مشکلی پیش نمی آید، چرا که شبکه عصبی خودش هر مقداری برای استخراج ویژگی از ورودی لازم باشد را محاسبه میکند. برای مثال اگر در عمل فیلتر زیر لازم باشد، حالت rotate شده ی فیلتر زیر لازم باشد (یعنی دقیقا همان عمل کانولوشن زده شود)، شبکه مقادیر را برای حالت rotate شده محاسبه میکند و اصلا نیازی نیست که ما در ابتدا مقادیر کرنل ها را به اندازه 180 درجه شیفت دهیم و بی خودی پیچیدگی محاسباتی رو افزایش بدهیم.

پس فعلا تکلیف مفهوم کانولوشن مشخص شد. حالا بیاییم ببنیم چطور میتوان یک لایه کانولوشن در شبکه های عصبی کانولوشنالی طراحی کرد.
لایه کانولوشن در شبکه های عصبی کانولوشنالی (convolutional layers in CNNs)
در لایه کانولوشن هر نورون همانند یک کرنل عمل میکند. یک لایه کانولوشن برخلاف لایه های fc که نوورنها به تمام عناصر ورودی وصل میشوند، اینجا هر کرنل اندازه محدودی دارد و به صورت محلی به تصویر ورودی وصل میشود و همین باعث می شود که اولا تعداد پارامترهای بسیار کمتری داشته باشد و از طرفی تصویر ورودی رو به صورت مکانی پردازش میکند و اطلاعات آنها را در استخراج ویژگی استفاده میکند و همین باعث میشود که ویژگی های مفیدی استخراج کند.

اگر اندازه کرنل را 3*3 در نظر بگیریم، یک نورون در شبکه ی کانولوشن 9+1 پارامتر دارد (9 تا خود کرنل و 1 هم برای بایاس)، این درحالی هست که یک نورون در fc برای تصویر 28*28 تعداد 784+1 پارامتر دارد. حال اگر اندازه تصویر بزرگتر شود این اعداد بسیار زیادتر خواهد شد، این در حالی هست که تعداد پارامترهای یک نورون از لایه کانولوشن همان اندازه 10 خواهد بود. در زیر یک نورون در لایه کانولوشن، و همچنین نحوه اعمال ان روی تصویر ووردی نشان داده شده است.
روال به این شکل هست که همانند فیلترینگ مکانی، کرنل (نورون لایه convolution) روی تک تک پیکسلها (با در نظر گرفتن همسایگی شان) اعمال شده و نتیجه بدست آمده به علاوه بایاس می شود و در آدرس متناظر در تصویر خروجی قرار میگیرد. لازم به ذکر هست که یک نورون ساده در لایه کانولوشن یک کرنل که همان وزنهای سیناسی دارد و یک بایاس که مقادیر آنها در طول آموزش شبکه عصبی تنظیم خواهند شد.
مفاهیم پایه در لایه کانولوشن
در عمل کانولوشن یک سری کارهایی انجام میشود تا عمل فیلترینگ به درستی یا حداقل به شکل مطلوب ما انجام شود. برای همین در این بخش به صورت کوتاه این مفاهیم را توضیح میدهیم.
Padding در لایه کانولوشن
همانطور که گفتیم، در زمان عمل کانولوشن (فیلترینگ)، ما نیاز داریم که کرنل را روی تک تک پیکسلهای تصویر اصلی اعمال کنیم و برای اینکار لازم هست که به اندازه کرنل- با مرکزیت پیکسل مورد نظر- پیکسلهای همسایه در نظر بگیریم. برای همه پیکسلها همچین امکانی خواهیم داشت به غیر از پیکسلهای کناری.
اگر روی آنها عمل فیلترینگ انجام ندهیم، اول اینکه اثر اینها (مخصوصا اگر حاوی اطلاعات مهم باشند) به خوبی مورد استفاده قرار نخواهند گرفت، دوما سایز تصویر خروجی هم نسبت به تصویر اصلی کاهش پیدا خواهد کرد. چرا که تعدادی سطر و ستون کناری در تصویر اصلی استفاده نشده اند. برای مثال اگر یک تصویر 28 در 28 داشته باشیم و اندازه کرنل هم 3*3 باشد. در این صورت یک سطر از اول و یک سطر از آخر، و همچنین یک ستون از اول و آخر مورد استفاده نخواهند گرفت. چرا که پیکسهای این سطر و ستونها همسایه ندارند. برای همین تصویر خروجی به جای 28 در 28، 26*26 خواهد بود. حال شما کرنل را 9*9 در نظر بگیرید، در این صورت 8 سطر و 8 ستون در فیلترینگ استفاده نخواهد شد و اندازه تصویر خروجی 20*20 خواهد بود.


تکلیف چیه؟ چطور میتوانیم پیکسلهای کناری تصویررا هم در پردازش استفاده کنیم. جواب استفاده از padding هست. برای اینکار لازمه که تعدادی سطر و ستون (به اندازه نیاز، برای مثال برای کرنل 3*3 لازمه که ما 1 سطر اول و آخر و یک ستون اول و آخر اضافه کنیم) ساختگی همانند شکل بالا به تصویر اضافه کنیم. مقادیر این سطر و ستونها اضافه شده میتونه صفر باشه یا کپی شده سطر و ستونهای کناری باشه و یا حالت متقارن سطر و ستونهای کناری. با اینکار ما میتوانیم روی همه پیکسلهای تصویر اصلی عمل فیلترینگ/کانولوشن را انجام دهیم.
Stride درلایه کانولوشن
استراید یا گام، مشخص میکند که پیمایش پیکسلها به چه شکل انجام شود. اگر stride=1 باشد، پیمایش به صورت یکی یکی انجام میشود، ولی اگر 2 باشد، با گام دو انجام میشود و اگر بیشتر باشد هم گام بیشتر خواهد شد. توجه کنیم که اگر پیمایش 1 باشد در نتیجه خروجی (با در نظر گرفتن padding) هم اندازه تصویر ورودی خواهد بود، ولی اگر 2 باشد، چون نصف سطر و ستونها پیمایش نمیشود، تصویر خروجی نصف تصویر ورودی خواهد بود.

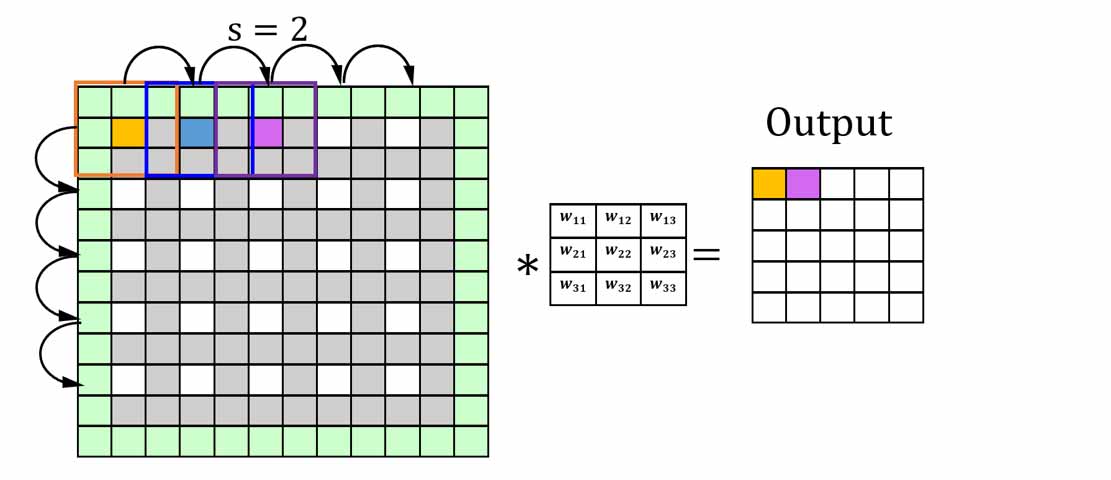
همانطور که در تصویر بالا مشخص هست، در حالت stride=2، پیکسلهایی که رنگ خاکستری دارند، پیمایش نخواهند شد
Dilatation در لایه کانولوشن
هر کرنل در لایه کانولوشن یک میدان دیدی (receptive field) دارد، و این میدان دید را اندازه کرنل مشخص میکند. برای مثال یک کرنل 3*3 میدان دید 3*3 برای تصویر ورودی دارد و تغییرات در اون ناحیه را میتواند آشکار سازی کند و اینکه این تغییرات چی باشند هم مقادیر داخل کرنل مشخص میکند.
برای اشکال کوچک، کرنل کوچک مناسب است و برای اشکال بزرگ کرنل بزرگتر. اما در نظر بگیریم که هر چقدر بخواهیم کرنل را بزرگتر در نظر بگیریم، به همان اندازه تعداد پارمتراهای شبکه نیز افزایش خواهد یافت.
یک راه ساده برای افزایش میزان receptive field یک کرنل بدون افزایش تعداد پارامترها، استفاده از تکنیک dilation هست. برای مثال اگر اندازه کرنل 3 در سه باشد و بخواهیم میزان receptive field 5*5 داشته باشد، باید dilation را برابر 2 در نظر بگیریم. یعنی در هنگام جدا کردن پیکسلهای همسایه هر پیکسل، به جای همسایگی 3*3، همسایگی 5*5 اما یک در میان جدا کنیم. اینطوری بدون افزایش پیچیدگی محاسباتی یا تعداد پارامترها، ناحیه دید کرنل را گسترش میدهیم.

توجه کنیم که ما همچنان در مجموع 3*3 یا به عبارتی 9 پیکسل را انتخاب میکنیم، اما به جای اینکه از پنجره 3*3 به مرکزیت پیکسل انتخاب کنیم، این تعداد همسایه را (9 پیکسل) را از پنجره 5*5 یکی در میان انتخاب میکنیم. به همین شکل میتوانیم receptive field یک کرنل 3*3 رو به 7*7 با در نظر گرفتن dilation=3، یا 9*9 با در نظر گرفتن dilation=4 بدون افزایش سایز کرنل، افزایش دهیم.

حال که با مفاهیم پایه کانولوشن آشنا شدیم، میتوانیم برویم سراغ طراحی لایه کانولشن در شبکه های کانولشنالی. باید توجه کنیم که این لایه ای که طراحی میکنیم در کدام بخش از شبکه هست، اینکه تعداد تصاویر ورودی چقدر هست و یا چندتا تصویر خروجی میخواهیم از روی آنها بسازیم اندازه کرنل کانولوشن را تعییین میکند. در ادامه میخواهیم مرحله به مرحله حالتهای مختلف را بررسی کنیم و توضیح دهیم که دقیقا در هر مرحله چه اتفاقی میافتد.
انواع لایه کانولوشن در شبکه های عصبی کانولوشنالی
در لایه کانولوشن اندازه کرنل را تعداد تصاویر ورودی و تعداد تصاویر خروجی که از روی آنها میخواهیم بسازیم مشخص میکند. فقط این را داشته باشیم که هر کرنل یک یا تعدادی وزن و یک بایاس دارد. اگر تعداد تصاویر ورودی یک عدد باشد کرنل (نورون از نوع کانولوشنی) ما فقط یک وزن (ماتریس) و یک بایاس (اسکالر) خواهیم داشت. ولی اگر تعداد تصاویر ورودی بیشتر از یک باشد، کرنل ما وزنهاش به ازای هر تصویر ورودی افزایش خواهد یافت، ولی بایاس همچنان یک خواهد بود. و به تعداد تصاویر خروجی میتوانیم کرنل داشته باشیم. مثلا اگر بخواهیم از روی تصویر یا تصاویر ورودی 10 تصویر بسیازیم، لازم هست که 10 نوورن/کرنل در نظر بگیریم. هر نورون یک w (که سایز ان را اندازه فیلتر و تعداد کانال تصویر ورودی مشخص میکند) و یک بایاس دارد.
لایه کانولوشن یک ورودی یک خروجی
اگر ما در ورودی یک تصویر داشته باشیم، یا به عبارتی عمق تصویر یک باشد، مثل تصاویر باینری یا خاکستری که فقط یک ماتریس دو بعدی هستند، و بخواهیم فقط یک تصویر از روی آن بسازیم، ما یک کرنل/نورون خواهیم داشت.

لایه کانولوشن یک ورودی چند خروجی
حالت دوم این سات که تصویر ورودی چندکاناله باشد یا به عبارتی عمق تصویر ورودی بیشتر از یک باشد. برای مثال تصویر رنگی را در نظر بگیرید که سه کانال R,G,B دارد. در چنین شرایطی لایه کانولوشن به ازای هر کانال یک وزن خواهد داشت. ولی همچنان به ازای هر کرنل (که فعلا یک در نظر گرفتیم) یک عدد خواهد بود. در زمان فیلترینگ، وزن هر کانال روی تصویر ورودی کانال مدنظر اعمال خواهد شد و در نتیجه اگر سه کانال داشته باشیم، سه تا تصویر ساخته خواهد شد که این سه کانال هم باهم جمع شده و به یک تصویر نهایی تبدیل خواهد شد. یعنی ابتدا به صورت مکانی تصویر ورودی (به ازای هر کانال) فیلتر شده و سپس به صورت channel-wised باهم ترکیب می شوند و تصویر نهایی ساخته میشود.

در تصویر زیر هم نحوه انجام عمل کانولوشن نشان داده شده است.

لایه کانولوشن چند ورودی-چند خروجی
حال که با فرایند کانولوشن آشنا شده ایم، میتوان حالت کامل لایه کانولوشن را بررسی کنیم. در حالتهای قبلی، ما فقط یک نورون کانولوشنی/کرنل داشتیم و این باعث میشد که ما از تصویر ورودی فقط یک تصویر خروجی بسیازیم. ایراد این رویکرد اینه که یک کرنل به تنهایی نمیتواند همه اطلاعات لازم از تصویر ورودی را استخراج کند. برای مثال ممکن است یک کرنل برای استخراج لبه های تصویر استفاده شود، یکی برای استخراج بافت تصویر، یکی برای استخراج رنگ و از این قبیل اطلاعات. پس با داشتن فقط یک کرنل نمیتوان همه این اطلاعات را همزمان استخراج کرد. پس بهتر است تعداد کرنل ها/نورونهای کانولوشنالی را زیاد کنیم. در شکل زیر حالت چند ورودی و چند خروجی را نمایش داده ایم. در اینجا به ازای هر تصویر خروجی باید یک کرنل تعریف کنیم.

هر کرنل مشخصات زیر را خواهد داشت:
نورون کانولوشنالی/کرنل: w,b
اندازه w برابر با n×r×c هست که اینجا n تعداد کانالهای تصویر ورودی هست و r×c هم اندازه فیلتر مکانی.
اندازه بایاس هم برابر با 1×1 هست.حال اگر ما چندتا از این کرنلها داشته باشیم، اندازه کرنلها به طور کلی به شکل زیر خواهد بود. اندازه w برابر با d×n×r×c هست که اینجا، d، تعداد کرنلها (همان تعداد تصاویر خروجی)، n تعداد کانالهای تصویر ورودی هست و r×c هم اندازه فیلتر مکانی. اندازه b برابر با d×1×1 هست. به ازای هر نورون یک بایاس خواهیم داشت.

در چنین حالتی، هر کرنل روی تصویر ورودی همانند حالت قبلی که صحبت کردیم اعمال خواهد شد، و در نتیجه به ازای هر کدام یک تصویر ساخته خواهد شد، و با کنارهم قرار دادن آنها d تا تصویر در خروجی خواهیم داشت. به عبارتی تصویر خروجی d تعداد کانال (عمق) خواهد داشت. فرایند در شکل زیر نشان داده شده است.
شما منتقل کنم.
نحوه طراحی لایه کانولوشن در PyTorch
در طراحی لایه کانولوشن، لازم هست که پارامترهای زیر را مشخص کنید. بسته به اینکه پارامترها، تعداد کرنلها و تعداد کانالهای تصویر ورودی، لایه کانولوشن به یکی از حالتهای گفته شده طراحی خواهد شد.
Python
from torch import nn import torch conv_layer= nn.Conv2d(in_channels=1, out_channels=16, kernel_size=(3,3), padding= (1,1), stride=1,dilation=1,groups=1) x= torch.rand(32,1,28,28) y= conv_layer(x) print(y.size()) … torch.Size([32, 16, 28, 28])
توضیح پارمترهای لایه کانولوشن
- in_channels: تعداد کانالهای تصویر ورودی
- از آنجا که اینجا فرض کردیم تعداد کانالها یک هست، برای همین مقدار آنرا یک در نظر گرفتیم.
- out_channels: تعداد کانالهای تصویر خروجی یا به عبارتی تعداد کرنلها
- به ازای هر کرنال یک تصویر ساخته میشود، که با کنارهم قرار گرفتن همه آنها تصویر خروجی با عمق d یا همان تعداد کانال d ساخته خواهد شد.
- در این مثال، تعداد کرنلها را 16 در نظر گرفتیم، در نتیجه تصویر خروجی 16 کانال خواهد داشت.
- Kernel_size: اندازه مکانی فیلتر/کرنلها
- در این مثال اندازه کرنل را 3*3 در نظر گرفته ایم.
- padding: همانطور که گفتیم، اگر بخواهیم فیلتر روی همه پیکسلها اعمال شود.
- لازم هست که به اندازه مرتبط با کرنل سطر و ستون اضافه کنیم. از آنجا که اندازه فیلتر 3*3 هست، پس برای همین نیاز هست یک سطر/ستون اول و یک سطر و ستون آخر اضافه شود. رابطه جنرال میتواند این باشد r//2,c//2. که در این رابطه r تعداد سطرهای کرنل و c تعداد ستونهای آن هست. و علامت // تقسیم مسطح هست.
- stride: گام پیمایش پیکسلها. ما در این مثال 1 در نظر گرفتیم.
- dilation: در مورد این ویژگی صحبت شد، ما اینجا 1 در نظر گرفتیم و برای همین از همان میدان دیدی که خود کرنل پوشش میدهد همسایه های هر پیکسل موقع اعمال کانولوشن انتخاب خواهند شد. اگر مقدار dilation را بزرگتر در نظر میگرفتیم در نتیجه این تعداد همسایه را از ناحیه وسیعتری انتخاب میکرد.
- group: یک ویژگی خیلی مهم هت که بعدا به طور مفصل در موردش صحبت خواهیم کرد.
لازم به ذکر هست که بعد از عمل کانولوشن یک لایه batch-normalization جهت تسهیل همگرایی شبکه، و سپس یک لایه غیرخطی (همان تابع فعال غیرخطی مثل ReLU) جهت اعمال خاصیت غیرخطی بودن ( nonlinearity) اضافه کنیم. لایه های کانولوشن بدون تابع فعال غیرخطی توانایی خیلی بالایی در استخراج ویژگی نخواهند داشت. چرا که چنین لایه هایی بدون تابع فعال غیرخطی ویژگی های ساده تری استخراج خواهند کرد. اما با کمک توابع غیرخطی، به لایه کانولوشن این توانایی را میدهیم که بتواند ویژگی های خطی ای از داده ورودی استخراج کند، یا به عبارتی بتواند الگوهای پیچیده تری را استخراج کند.
CONV→ Batch Normalization → ReLU
در ادامه شبکه عصبی LeNet را معرفی و پیاده سازی خواهیم کرد. فعلا فقط با لایه های کانولوشن آشنا شده ایم. در پست بعدی، لایه pooling و fully connected ها و نقش هر کدام از آنها در شبکه های کانولوشنی را بررسی خواهیم کرد و سپس شبکه عصبی lenet را در پایتورچ پیاده سازی خواهیم کرد.
دوستان عزیزم، مباحث گفته شده بخشی کوتاه از دوره جامع و تخصصی یادگیری عمیق هست.
ما در دوره یادگیری عمیق، ابتدا شبکه های عصبی عمیق را کاملا به صورت دستی پیاده سازی میکنیم و بعدش میریم سراغ ابزارهای آماده در پایتورچ. و برای پیاده سازی دستی هم، اول ریاضیات و اثبات روابط، بعدش نمایش ماتریسی عملیات، را کامل یاد میگیریم. در آخر هم بعد از معرفی ابزار پایتورچ پروژه های عملی مختلف در زمینه های پردازش تصویر، پردازش سیگنال و پردازش متن انجام میدهیم تا با چالشهای واقعی انجام پروژه به صورت عملی آشنا شویم.
دوستانی که قصد یادگیری تخصصی و عمیق شبکه های عمیق هستند، پیشنهاد میکنم دوره جامع یادگیری عمیق مارا نگاه کنند. در این دوره که بیش از یک سال طول کشید تا مباحث آماده شود، سعی کردیم مباحث مهم و کاربردی را همه از لحاظ تئوری و هم از لحاظ عملی آموزش دهم و تا درک تخصصی از این ابزار بدست بیاریم و بتونیم از آنها در انجام پرژه ها به خوبی استفاده کنیم و از همه مهمتر بتونیم این شبکه ها را توسعه دهیم. چه از لحاظ ریاضیات و چه از لحاظ ساختار در کاربردهای مختلف.
دوره های مرتبط

آموزش تولباکس EEGLAB-پیش پردازش سیگنال EEG

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

اصول برنامه نویسی پایتون Python

[…] مطالعه پست قبلی: لایه کانولوشن در شبکه های کانولوشنالی […]