
انتخاب مدل یادگیری ماشین مناسب با کمک تیغ اوکام
احتمالا تا الان براتون پیش اومده که در یک پروژهای از دو مدل یادگیری ماشین استفاده کردهاید و مشاهده کردید هر دو تقریبا مثل هم عمل میکنند و بعد در انتخاب بین دو مدل به مشکل خوردهاید یا براتون سوال بوده که کدوم یکی رو انتخاب کنم بهتر است؟! بهتون یه راه ساده و کاربردی رو پیشنهاد میکنیم… تیغ اُکام! یک ابزار منطقی که سعی میکنه مسیر رو براتون هموار کنه و کمک کنه مدل مناسب رو برای مسئله انتخاب کنید!
مدل ساده یا مدل پیچیده؟ مسئله این است!
اغلب در پروژه های یادگیری ماشین برای ما سوال ایجاد میشود که چه مدلی را استفاده کنیم. برای مثال در شبکههای عصبی تعداد لایه های پنهان یا تعداد نورون ها را چقدر در نظر بگیریم که خیالمان راحت باشد مدل طراحی شده در دادههای جدید هم خوب عمل کند. در این بخش میخواهیم توضیح دهیم که چطور می توان یک مدل مناسب برای حل یک مئسله در پروژه های داده کاوی و یادگیری ماشین انتخاب کرد.
برای درک بهتر اجازه بدهید با یک سوال مبحث رو شروع کنیم . فرض کنید یک مسئله دو کلاسه داریم و با کمک دو مدل یادگیری ماشین مرز تفکیک کننده دو کلاسه را بدست آورده ایم، به نظر شما کدام مدل مناسب است؟ A ، B و یا C ؟؟؟؟
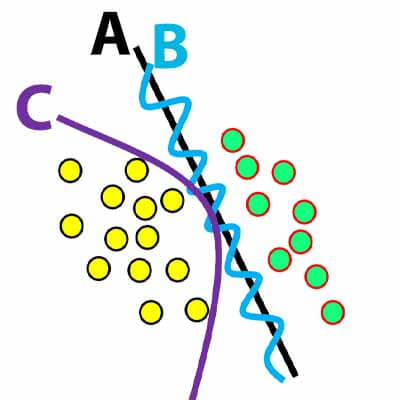
احتمالا اکثر دوستان مدل A رو انتخاب کنند، ولی سوال اینه که چرا اینو انتخاب میکنید؟ مسئله بعدی اینه که ممکنه در پروژههای عملی ابعاد داده زیاد باشه و عملا نشه فضای ویژگی را رسم کرد تا متوجه شد چه مدلی برای پیدا کردن مرز استفاده کنیم بهتر است. در این موارد چیکار میکنید؟ فرض کنید در یک مسئله مدل SVM خطی و مدل SVM غیرخطی تقریبا همانند هم عمل میکنند، الان کدام یکی را انتخاب میکنید؟ یا در یک مسئلهای شبکه عصبی تک لایه و چند لایه عملکردی تقریبا یکسان دارند، الان کدام یکی رو انتخاب میکنید؟
برای اینکه متوجه شویم در یک مسئله ای از مدلی استفاده کنیم، میتونیم از اصل تیغ اُکام استفاده کنیم!
اصل تیغ اُکام (Occam’s razor )
در توضیح و توصیف، بخشهای غیرضروری را حذف کن. تیغ اکام یک اصل حل مسئله هست که بیان میکند اگر برای پدیدهای به توضیحی نیاز داریم، باید “کمترین فرضها” را به کار ببریم و بدون ضرورت وجود چیزی را مسلم فرض نکنیم
“Entities are not to be multiplied without necessity”
قضیه تیغ اُکام مبنای فسلفی دارد و توسط ویلیام اکام مطرح شده است. خلاصه مطلب این است که اگر برای یک مسئله دو تا توضیح ارائه شده است. جوابی که ساده تر است رو انتخاب کن! به عبارتی جوابی که در آن فرضیه های کمتری استفاده شده است به احتمال بسیار زیاد پاسخ درست است.
تیغ اُکام یک ابزار منطقی و فکری است که سعی بر هموار کردن راه رسیدن به حقیقت دارد. این تیغ منطقی میگوید اگر برای یک اتفاق چندین توضیح وجود دارد، پژوهشگر (یا فیلسوف) میبایست به سادهترین آنها رجوع کند. به عبارتی توضیح یک اتفاق بایستی سادهترین در میان سایر توضیحات ارائه شده باشد امّا نه سادهتر.
تیغ اُکام، بیان میکند که اضافه شدن هر فرضیه به یک نظریه، احتمال خطای آن را افزایش میدهد. به همین دلیل توصیه میشود همیشه سادهترین توضیح را در نظر بگیریم تا احتمال درستی آن توضیح را به حداکثر مقدار ممکن برسانیم.
وقتی با چند توضیح برای یک موضوع مواجه میشویم، بهتر است در گام اول سادهترین توضیح را برای بررسی انتخاب کنیم. با این کار در صورتی که آن توضیح یا نظریه درست نباشد، کوتاهترین راه را برای رد آن انتخاب کردهایم.
نام این اصل از دو کلمه تشکیل شده است که کلمه اول یعنی تیغ، برمیگردد به حذف فرضیات اضافه از یک نظریه یا توضیح با استفاده از آن و کلمه دوم هم برمیگردد به اسم یک فیلسوف انگلیسی با نام کامل ویلیام اُکام که در قرن چهاردهم میزیسته و این اصل را مطرح کرده است.
مفهوم پارامتر در مدلهای یادگیری ماشین
قبل اینکه توضیح دهیم چطور میتوان با کمک اصل تیغ اُکام مدل مناسب را انتخاب کرد بهتر است در ابتدا با مفهوم پارامتر آشنا شویم.در حوزه یادگیری ماشین، مدلها از یک سری پارامترها تشکیل شده اند و در پروسه یادگیری با کمک پایگاه داده، پارامترها را تنظیم میکنند تا بتوانند طبق آنها مسئله را حل کنند.
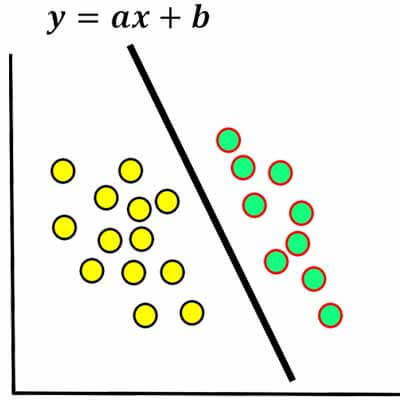
برای مثال در یک مسئله دو کلاسه خطی، مرز دادهها یک مرز خطی هست و اگر شیب و عرض مبدا خط را پیدا کنیم میتوانیم دادهها را با کمک خط دستهبندی کنیم. svm خطی، شبکه عصبی تک لایه، در پروسه یادگیری دنبال پیدا کردن شیب و عرض از مبدا خط(مرز تصمیمگیری) هستند. و تابع هزینه آنها خطی هست و دارای دو پارامتر، که در پروسه یادگیری مقدار بهینه این دو پارامتر را پیدا میکنند، که به عبارتی همان شیب و عرض از مبدا مرز رو پیدا میکنند! این مدلها در فضای دو بعدی دو تا پارامتر دارند. و اگر فضا بیشتر شود تعداد پارامترها نیز افزایش می یابد.
حال اگر مرز غیرخطی باشد، آیا با کمک این دو تا پارامتر میتوان مرز بهینه برای تفکیک دو کلاس بدست آورد؟ خیر با این دو پارامتر نهایتا میتوان یک مرز خطی بدست آورد. به عبارتی اگر مدل خطی باشد توان حل یک مسئله غیرخطی را نخواهد داشت.
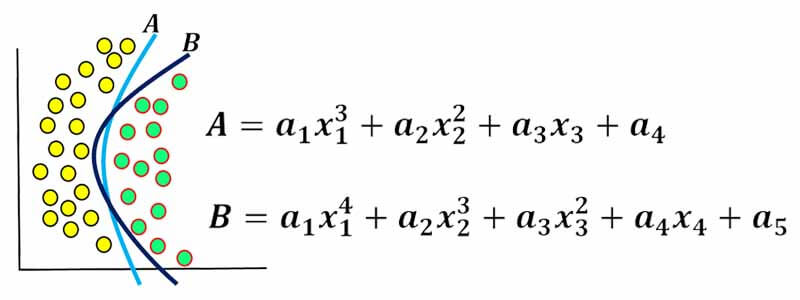
لازم است که تعداد پارامترهای مدل افزایش یابد تا بتواند مرز را پیدا کند، هرچقدر تعداد پارامترها افزایش یابد قابلیت پیدا کردن مرزهای پیچیده افزایش می یابد!
انتخاب مدل مناسب با تیغ اوکام
خب سوال این است که چطور میتوان از این اصل در داده کاوی و یادگیری ماشین برای انتخاب مدل مناسب استفاده کرد؟ فرض کنید یک مسئله ای دارید و در آن از دو مدل برای حل مئسله استفاده کرده اید و هر دو مدل عملکرد یکسانی دارند. مدل اول پیچیده و غیرخطی و مدل دوم ساده و خطی است. مدل پیچیده تعداد پارمترهای زیادی نسبت به مدل ساده تر دارد. اینجا پارامتر برمیگردد به همان فرضیه ها در اصل تیغ اکام .
الان به نظر شما کدام مدل را انتخاب کنیم بهتر است؟ طبق این اصل تیغ اکام اینجا بهتر است از مدل دوم که سادهتر است استفاده کنیم. چون تعداد پارامترهای کمتری برای پیدا کردن مرز استفاده میکند. چرا؟ چون میدانیم که تعداد پارامترهای مورد استفاده شده در یک مدل غیرخطی به مراتب بیشتر از مدل خطی است.
مدلهای غیرخطی توان حل مسائل پیچیده را دارند ولی احتمال اینکه overfit شوند بسیار زیاد است و هر چقدر مدل پیچیده تر شود به احتمال زیاد خاصیت generalization خود را از دست میدهد! از طرفی مدلهای ساده خاصیت generalization خیلی خوبی دارند، به نویز حساسیت بسیار کمی دارند، ولی توانایی حل مسائل خیلی پیچیده را ندارند!
در این مثالی که مطرح کردیم، هر دو مدل عملکرد یکسانی دارند. پس ما طبق اصل تیغ اکام مدل ساده تر را انتخاب میکنیم. از دید علوم داده هم منطقی است. چرا که مدلهای ساده خاصیت generalization خوبی دارند و روی داده جدید هم بهتر عمل خواهند کرد!
حال فرض کنید چنین مسئله ای داریم؟ از چه مدلی استفاده کنیم؟ A,B,C ؟
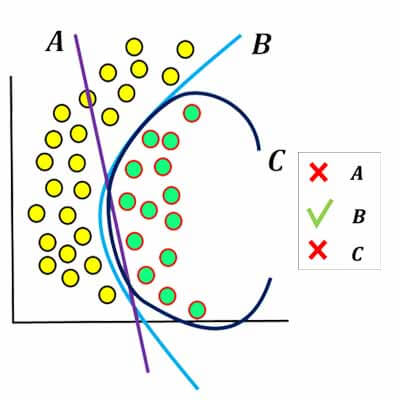
مدل A یک مدل خطی است، و مدل B و C یک مدل غیرخطی هستند. الان سوال این است که کدام یکی را انتخاب کنیم.
هشدار
توجه کنیم که همیشه مدل سادهتر بهترین مدل نیست! در توضیح یک اتفاق بایستی سادهترین در میان سایر توضیحات ارائه شده باشد امّا نه سادهتر. در یادگیری ماشین هم همین مسئله رو باید بهش توجه کنیم. ممکن است یک مسئله ای داشته باشیم که نتوان با یک مدل خطی حلش کنیم، مثلا یک داده ای داریم که در فضای غیرخطی توزیع شده است، مطئنا مدلهای خطی قابلیت پیدا کردن چنین مرزی را ندارند! و ما مجبوریم از مدلهای غیرخطی استفاده کنیم، ولی سوال اینه تا چه حد غیرخطی؟ ما میتونیم در بین مدلهای غیرخطی ساده ترین را انتخاب کنیم تا دچار overfitting هم نشویم.
آلبرت اینشتین در این مورد گفته:
هر چیزی را باید هر چقدر که میتوانید ساده کنید ولی نه خیلی ساده.
در این مثال انتخاب ما قطعا مدل A نخواهد بود! چرا که توان حل چنین مسئله را ندارد. حال در بین مدلها دو مدل باقی مانده است که باید یکی را انتخاب کنیم. بین مدل B و C از قضیه تیغ اُکام کمک میگیریم. و ساده ترین را انتخاب میکنیم.
همانطور که میبینیم هر دو مدل B و C عملکرد تقریبا یکسانی دارند. مدل B نسبت به مدل C مرز هموارتری دارد و نشان میدهد که تعداد پارامترهای کمتری نسبت به مدل C دارد. مدل C عملکرد بهتری روی این داده دارد. چرا که تعداد پارامترهای زیادی دارد و متیواند مرزهای پیچیده را پیدا کند. ولی در این مسئله تقریبا overfit شده است و در داده جدید عملکرد خوبی نخواهد داشت.
بنابراین ما مدل B را برای حل این مسئله استفاده کنیم. این مدل در داده جدید هم خوب عمل خواهد کرد.
چطور میتوانیم تعداد لایهها در شبکه عصبی یا تعداد پارامترهای در سایر مدلها مثل درجه polynomial در svm غیرخطی را با کمک قضیه اُکام تعیین کنیم تا دچار overfitting نشویم؟
در شبکه های عصبی با ساختارهای ساده تر شروع میکنیم و رفته رفته تعداد لایه ها را افزایش میدهیم، تا زمانی که دقت هم روی داده آموزش و هم روی داده تست افزایش پیدا میکند، تعداد لایه ها را افزایش میدهیم. ولی اگر از یک مرحل به بعد عملکرد یکسان باقی ماند دیگه ادامه نمیدهیم و طبق قضیه اکام ساده ترین را اتنخاب میکنیم. و یا ممکن است بعد یک مرحله دقت مدل روی داده آموزشی افزایش یابد و روی داده تست کاهش یابد. اینجا overfitting رخ داده است و اصلا نباید مدل را پیچیده بکنیم!
برای تعیین درجه polynomial در svm غیرخطی تا زمانی که دقت هم روی داده تست و داده آموزش افزایش میابد درجه را افزایش میدهم.
هر موقعی که یک مدل یادگیری ماشین را یک مرتبه پیچیده نسبت به مرحله قبل پیچیده تر میکنیم باید ببینیم ارزش این همه پیچیدگی را دارد یا نه! مدل ساده را به عنوان معیار(benchmark) در نظر میگیریم. بعد نیتجه مدلهای پیچیده را بررسی میکنیم تا به این سوال جواب بدهیم: آیا ارزش پیچیده کردن مدل وجود دارد؟ اگه نه پس مدل سادهتر را انتخاب می کنیم.
البته مدل ذهنی تیغ اوکام یک قانون نیست بلکه یک راهنمای پیشنهادی در موقعیتهای مختلف در زندگی هست. گاهی اوقات یک توضیح پیچیده، درستترین توضیح است؛ اما دلیلی وجود ندارد که ما در تمامی موقعیتها همان ابتدای کار به سراغ پیچیدهترین توضیح برویم در حالی که گزینههای سادهتری هم وجود دارند
تجربه شخصی خودم
وقتی قرار است یک مسئلهای را با کمک شبکههای عصبی حلش کنم، در ابتدا سادهترین شبکه رو انتخاب میکنم. شبکه عصبی تک لایه با قانون یادگیری وینرهاف! هم ساده هست و هم سریع یاد میگیره. مثلا در مسائل طبقهبندی در همان ابتدا چک میکنم ببینم که آیا این داده رو میشه با کمک این شبکهی تک لایه با دقت بالایی دسته بندی کرد؟ اگر دقت خیلی خوب باشد سراغ شبکه های پیچیده تر نمیروم!
اگر دقت خوب نباشد احتمال میدهم فضا غیرخطی هست و این شبکه توان حل چنین مسئله ای را ندارد. بهتر است با شبکههای عصبی چندلایه امتحان کنم. ولی باز همچنان سراغ شبکههای عصبی چندلایه نمیروم! چون میدونید که تعیین ساختار مناسب، قانون یادگیری مناسب، پارمترهای مناسب برای یادگیری شبکههای عصبی چندلایه داستان هست! وقتم رو بیخودی هدر نمیدهم. اول مطمئن میشوم که داده مناسب هست یا نه. چون ممکنه اصلا داده مناسب نباشد و ویژگیهای خوبی استخراج نشده باشد، پس بروم سراغ شبکه عصبی چندین ساعت وقتم بی مورد هدر میرود! برای اینکه مطمئن شوم داده مناسب هست میرم سراغ مدلهای سادهتر در بین روشهایی که توانایی حل مسائل غیرخطی را دارند. اکثر مواقع در گام دوم میروم سراغ الگوریتم knn که یک روش خوب و بسیار ساده است و توان حل مسائل غیرخطی را هم دارد. نتیجه باعث میشود که دو تا قضاوت بکنم و دو تا ایده در ذهن داشته باشم.
اگر این الگوریتم هم عملکرد خیلی بدی داشته باشد احتمال اینکه داده مناسب نیست زیاد میشه. و امید زیادی برای رسیدن به دقت خیلی خوب توسط شبکههای عصبی نخواهم داشت. ولی باز با شبکههای عصبی چندلایه هم در گام سوم مسئله را بررسی میکنم. ولی اگر خیلی خوب عمل نکرد زیاد وقتم رو روی تعیین ساختار و پارامترهای شبکه هدر نمیدهم چون قبلا به این رسیده بودم که داده مناسب نیست و الان مطمئن شدم. و در گام چهارم اگر مقدور باشد میرم سراغ مراحل قبل از طبقهبندی، مثل پیشپردازش، استخراج ویژگی و انتخاب ویژگی.
ولی اگر دقت knn بهتر از شبکه عصبی تک لایه باشه، احتمال میدهم که داده غیرخطی هست و بهتر است از مدلهای غیرخطی کمک بگیرم. در گام سوم میروم سراغ شبکههای عصبی چندلایه و سعی میکنم ساختار و پارامترهای مناسب را برای شبکه عصبی چندلایه انتخاب کنم تا به دقت خوبی برسم. و این رویکرد بهم کمک میکنه وقتم رو هدفمند صرف پروژه بکنم.
دوره های مرتبط

پکیج کامل پیادهسازی گام به گام شبکههای عصبی

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

دیدگاه ها