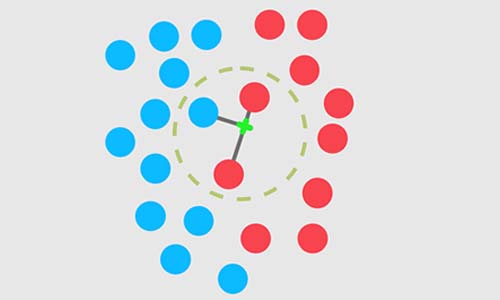
مروری مختصر بر الگوریتم نزدیکترین همسایه(KNN)
Knn مخفف عبارت k nearest neighbors است و برای تخمین خروجی داده جدید از k تا نزدیک ترین همسایه ی نمونه جدید در داده های آموزش کمک می گیرد.
اگر برای برای تست الگوریتم knn از خود داده آموزش استفاده کنیم، و تعداد k برابر یک باشد در اینصورت دقت طبقهبندی چقدر خواهد بود؟
برای جواب دادن به سوال بهتر است که در ابتدا با رویکرد تصمیمگیری الگوریتم knn آشنا شویم. knn در بحث یادگیری ماشین جزء الگوریتمهای غیرپارامتری است و از آن میتوان هم در مباحث طبقهبندی و هم رگرسیون استفاده کرد.
اکثر ما knn رو برای مسائل طبقهبندی میشناشیم و وقتی با عبارت knn روبرو میشویم یاد مسائل طبقه بندی میافتیم. ولی جالب است بدانیم که از knn میتوانیم در مسائل رگرسیون هم استفاده کنیم و اتفاقا در مسائل رگرسیون هم خوب عمل میکند!
رویکرد تصمیم گیری الگوریتم knn
Knn مخفف عبارت k nearest neighbors است و برای تخمین خروجی داده جدید(تست) از k تا نزدیکترین همسایه ی نمونه تست در داده های آموزش کمک میگیرد.
همانطور که میدانیم، الگوریتمهای یادگیری ماشین نیاز به پروسه آموزش دارند، تا با کمک داده آموزش یک دانشی را بدست بیاورند و بعدا بتوانند طبق این دانش، خروجیِ داده جدید را تخمین بزنند.
اولین نکته در مورد knn اینه که این الگوریتم نیاز به پروسه آموزش ندارد!
در این روش تنها کافیه که از قبل تعدادی نمونه به عنوان مجموعه آموزش به مدل ارائه دهیم. مدل این مجموعه را ذخیره میکند تا بعدا با کمک آنها خروحی داده های جدید را تخمین بزند.
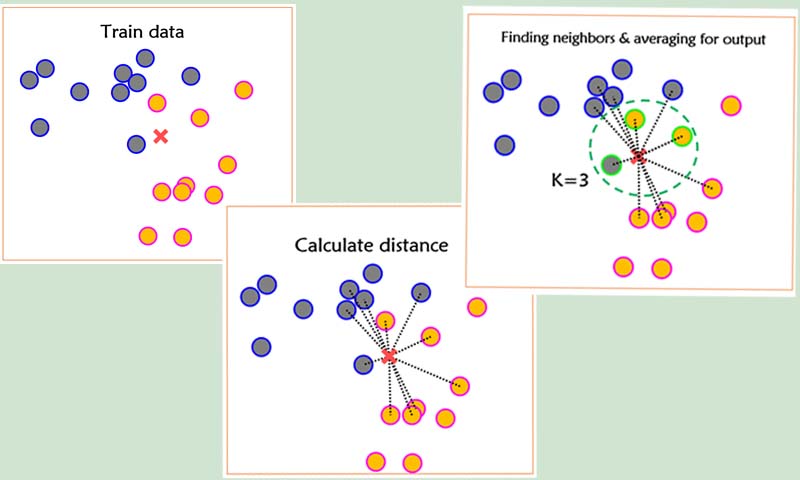
اجازه بدهید یک مثال ساده طبقه بندی ببرای درک بهتر رویکرد تصمیم گیری KNN بزنیم. فرض کنید یک مسئله طبقهبندی دو کلاسه داریم که در آن داده های آموزشی به صورت زیر در فضای دو بعدی توزیع شدهاند و فرض کنید نمونه (x) داده تست ما هست و میخواهیم لیبل این داده تست را تخمین بزنیم، به عبارتی میخواهیم این داده تست را دسته بندی بکنیم و تعیین کنیم که به چه کلاسی تعلق دارد. حال طبق روال زیر میتوانیم با کمک الگوریتم KNN لیبل داده تست را تخمین بزنیم.
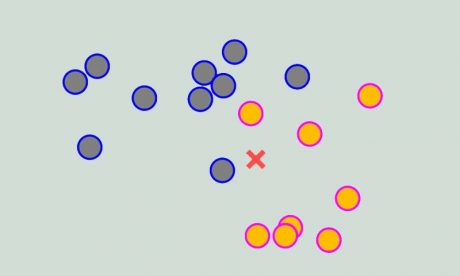
الگوریتم knn در سه مرحله لیبل داده جدید را تخمین میزند:
- در مرحله اول knn فاصله نمونه تست با تمامی نمونههای آموزش محاسبه میکند
- سپس در مرحله دوم براساس فاصله بدست آمده، k تا نزدیکترین همسایه از داده آموزش به داده تست را پیدا میکند
- در مرحله آخر رای گیری انجام میدهد تا متوجه بشود که از بین این k تا نزدیکترین همسایه کدام کلاس بیشترین همسایه از داده آموزش به نمونه تست دارد تا تصمیم بگیرد که نمونه جدید به آن کلاس تعلق دارد.
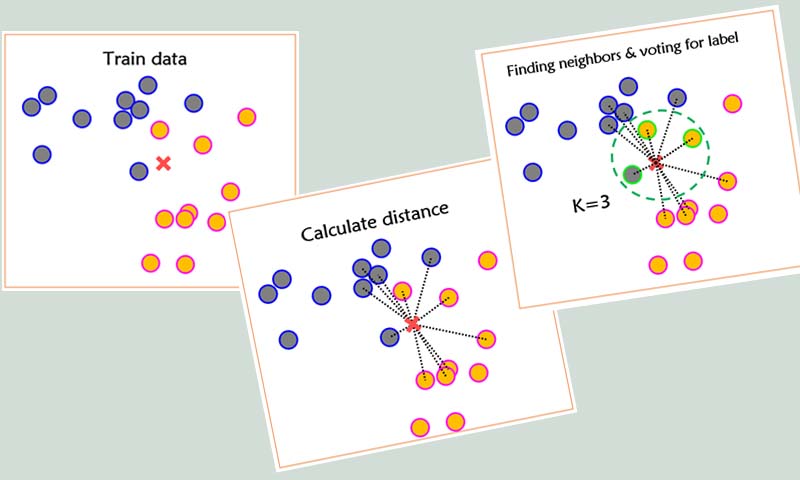
همانطور که از اسم الگوریتم knn مشخص است، این الگوریتم k نزدیکترین همسایه نمونه تست را از بین نمونههای آموزش پیدا میکند تا متوجه شود داده جدید بیشترین همسایه را از کدام داسته دارد. در رویکرد knn بنا بر این است که نمونه تست کنار نمونههای شبیه به خودش قرار میگیرد یا به عبارتی شبیه نمونه های کلاسی خواهد بود که به آن کلاس تعلق دارد. در نتیجه نمونه تست بیشترین همسایه را از کلاسی خواهد داشت که به آن کلاس تعلق دارد. یعنی اگر نمونه جدید مربوط به کلاس یک باشد، کنار نمونههای آموزش کلاس یک قرار میگیرد و اگر مربوط به کلاس دو باشد به همین ترتیب…
به نظر منطقی هم می آید، در زندگی واقعی هم خیلی از پدیده ها همچین رفتاری دارند.
در این روش تعداد نزدیکترین همسایه ها توسط کاربر مشخص میشود و سپس الگوریتم knn طبق روال گفته شده نزدیکترین همسایههای نمونه جدید را از بین نمونههای آموزش پیدا میکند و سپس رای گیری میکند که ببیند تا بیشترین همسایه ها از کدام کلاس است.
خب حالا که متوجه شدیم روال تصمیم گیری knn به چه شکل هست، بیاییم سوالی که در ابتدا پرسیدیم را بررسی کنیم.
اگر برای برای تست الگوریتم knn از خود داده آموزش استفاده کنیم، و تعداد k برابر یک باشد در اینصورت دقت طبقهبندی چقدر خواهد بود؟
سوال معنیش این است که برای تست دوباره بیاییم از خود دادههای آموزش استفاده کنیم. حال فرض کنید که لیبل این دادههایی که برای تست میخواهیم استفاده کنیم را نداریم و به knn میدهیم تا لیبل این نمونه ها را طبق رویکردی که دارد تخمین بزند.
در پروسه ارزیابی فرض بر این میگیرند که لیبل داده تست وجود ندارد، و این نمونه ها را به مدل یادگیری ماشین ارائه میدهند تا مدل براساس رویکرد تصمیم گیری خودش لیبل تک تک داده های تست را تخمین بزند. ولی ما در واقعیت لبیل داده های تست را داریم تا بعدا که مدل لیبل تک تک نمونه های تست را تخمین زد، با آنها مقایسه کنیم و پارامترهای ارزیابی را محاسبه کنیم و اگر عملکرد مدل قابل قبول بود در عمل برای تخمین لیبل داده های جدید استفاده کنیم.
حال شما فرض کنید که ما لیبل داده های تست، در این مثال شما بخوانید داده آموزش، را میخواهیم با knn که k=1 است را تخمین بزنیم و بعد با لیبلهای واقعی مقایسه کنیم تا عملکرد knn را بررسی کنیم. خب در ابتدا knn فاصله ی هر نمونه تست را با تمام نمونه های آموزش محاسبه میکند، سپس k تا نزدیکترین همسایه از داده آموزش برای هر نمونه تست پیدا میکند، و از اونجا که k=1 در نظر گرفتیم، در نتیجه لیبل نمونه تست برابر است با لیبل نزدیکترین همسایه اش در داده آموزش!
خب، نزدیکترین همسایه هر نمونه تست( آموزش) در بین دادههای آموزش که خودش هم بین اونا هست کدام نمونه خواهد شد؟
جواب خیلی ساده است، خودش! در نتیجه لیبل تخمین زده شده برای هر نمونه تست برابر با لیبل واقعی آنها خواهد بود و دقت طبقهبند برابر 100 درصد خواهد بود!
ما در عمل به این شکل مدل را ارزیابی نمیکنیم، فقط یک مثالی بسیار ساده ای بود که خواستیم دوستانی که فصل چهارم دوره شناسایی الگو و یادگیری ماشین را کمی به چالش بکشیم.
در واقعیت ما برای ارزیابی هر مدل یادگیری ماشین داده را با یک روشی به دو بخش آموزش و تست تقسیم می کنیم و سپس با کمک داده آموزش مدل را آموزش میدهیم و با داده تست مدل آموزش دیده را تست میکنیم تا ارزیابی کنیم و ببینیم که مدل با چه عملکردی میتواند داده ها را دسته بندی کند.
داده ای که در پروسه آموزش استفاده شده به هیچ عنوان در پروسه تست استفاده نمی شود!
خب دیدیم که knn رویکرد بسیار ساده و سرانگشتی دارد، ولی در اکثر پروژه ها این رویکرد خیلی خوب عمل میکند و همین سادگی و موثر بودن ایده اش باعث شده که پای ثابت اکثر مقالات تخصصی شود. Knn رویکرد بسیار ساده ای دارد و اگر به درستی ازش استفاده شود، دقت خیلی بالایی خواهد داشت! عملکرد KNN به سه تا مولفه ی بسیار مهمی وابسته است!
عبارت به درستی استفاده شود، یعنی تعداد همسایهها را مناسب انتخاب کنیم، یا معیار فاصله مناسبی برای داده انتخاب کنیم، و همچنین از نظر همسایه ها به طور عادلانه استفاده کنیم.
رویکرد اولیه KNN برای رای گیری بر برابری است ولی باید عادلانه باشد!

مثال زیر را در نظر بگیرید:
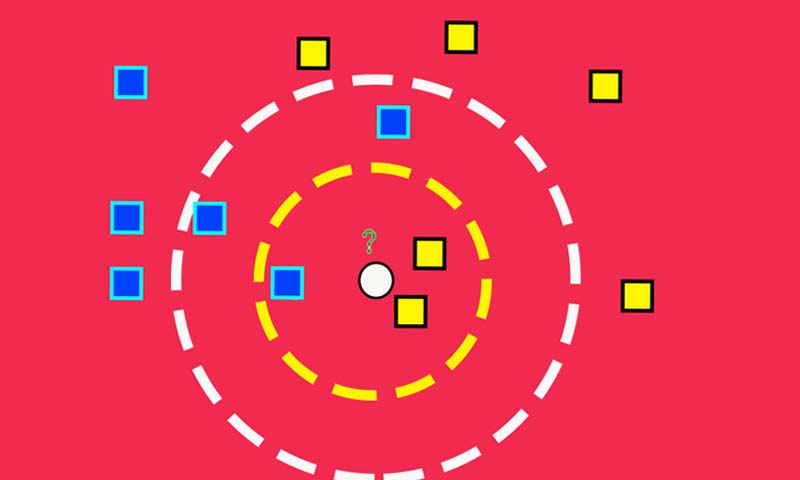
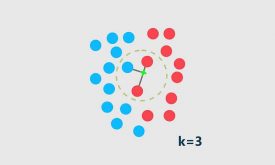
در این مثال k را چی در نظر بگیریم؟ اگر k برابر 3 باشد، نمونه تست به چه کلاسی تعلق میگیرد؟ کلاس 2، حال اگر k برابر 5 باشد چی؟ کلاس 1 ! می بینیم که نتیجه تصمیم گیری knn به تعداد همسایهها وابسته است.
عیب الگوریتم Knn
یکی از مهمترین معایب knn این است که از نظر همسایه ها به طور یکسان استفاده می کند! در حالی که باید هر همسایه ای بر اساس فاصله ای که به نمونه ی تست دارد، سهم متفاوتی در پروسه تصمیم گیری داشته باشد! همین موضوع باعث شده که الگوریتم knn به تعداد k بسیار حساس باشد.
شما اگه به یک بیمارستان بروید و یک آزمایش بالینی انجام بدهید و نتایج این آزمایش را چندین نفر بررسی کنند، برای مثال یک نفر پزشک متخصص، یک نفر پزشک عمومی و یک نفر خدماتی. و مطمئنا هر کدام براساس دانشی که دارد تصمیم متفاوتی میتواند بگیرد. حال شما میخواهید بدانید که نتیجه آزمایش شما مثبت بود یا منفی؟ اگر بخواهید براساس نظر این سه نفر تصمیم بگیرید که نتیجه آزمایش مثبت بوده یا منفی، به نظر هر کدام از این افراد چه درجه اهمیتی میدهید؟ مطمئنا شما هم به این ترتیب به نظرات درجه اهمیت خواهید داد: پزشک متخصص(بالا)، پزشک عمومی( متوسط) و خدماتی(پایین)
در knn هم باید موقع تصمیم گیری از نظر همسایه ها براساس درجه اهمیتی که دارند استفاده کنیم. به عبارتی باید در ابتدا به تک تک k تا نزدیکترین همسایه براساس فاصلهای که به نمونه ی جدید دارند یک وزن بدهیم، هر چقدر نزدیکتر وزن بیشتر، و هر چقدر دورتر وزن کمتر!
به الگوریتمی که به صورت وزندار رای گیری انجام میدهد weighted knn یا به اختصار wknn می گوییم.
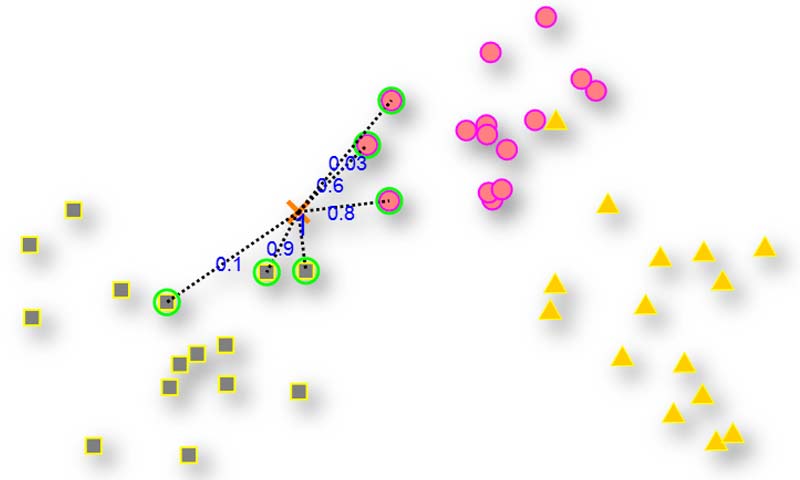
چطور از knn در مسائل رگرسیون استفاده کنیم؟
خب میدانیم که در مسائل رگرسیون خروجی نمونه ها به صورت پیوسته است، در حالی که در مسائل طبقه بندی خروجی گسسته است. خب الان چطور از knn در مسائل رگرسیون استفاده کنیم؟
با یک تغییر کوچک خیلی راحت میتوانیم از knn در مسائل رگرسیون هم استفاده کنیم. تنها کافیه که در مرحله آخر به جای رای گیری، از خروجی k تا نزدیک ترین همسایه میانگین بگیریم و هر چی بدست آمد، میشود خروجی نمونه جدید!
چطوری میتوانیم مسئله وزندار را در مسائل رگرسیون در نظر بگیریم؟
چرا که اینجا هم باز همان مسئله وجود دارد، باید در محاسبه خروجی نمونه جدید، همسایه های نزدیکتر تاثیر بیشتری نسبت به همسایه های دورهداشته باشند.
جواب سوال خیلی ساده است، میانگین گیری وزندار! به جای اینکه همه نمونه ها در میانگین گیری به طور یکسان سهم داشته باشند، سهم متفاوتی داشته باشند.
اگر علاقه مند هستید که در مورد knn بیشتر بدانید و به طور تخصصی این الگوریتم را یاد بگیرید پیشنهاد میکنیم فصل چهارم دوره جامع شناسایی الگو-یادگیری ماشین را نگاه کنید.
در این فصل در ابتدا تئوری الگوریتم knn کامل از پایه آموزش داده میشود، سپس مرحله به مرحله پیاده سازی میشود، و روی یک مثال بسیار ساده اعمال می شود تا درک بهتری از روند تصمیم گیری knn داشته باشیم. سپس چندین پروژه عملی انجام می شود تا با کاربرد عملی این روش و چالش های استفاده از این روش در پروژه های عملی آشنا شویم.
الگوریتم knn و wknn (چندین روش برای وزندار طبقه مقالات تخصصی ) هم در مسائل طبقه بندی و هم در مسائل رگرسیون همراه با پروژه های عملی آموزش داده شده اند و آزمایشهای مختلفی هم انجام شده است تا به صورت عملی با مزایا و معایب این الگوریتمها بهتر آشنا شویم.
دوره شناسایی الگو-یادگیری ماشین: الگوریتم knn-wknn
دوره های مرتبط


شناسایی الگو(فصل4 بخش اول): کلاسبند نزدیکترین همسایه knn و الگوریتمهای بهبودیافته شده آن(wknn)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

دیدگاه ها