در چند دهه گذشته، شاهد افزایش قابل توجهی در توانایی پردازش اطلاعات پیرامون توسط کامپیوترها بودهایم. گوشیهای هوشمند کلام را به متن تبدیل میکنند. ماشینهای خودران، اشیا را در جاده شناسایی میکنند و از برخورد با آنها جلوگیری میکنند.
در پس تمام این پیشرفتها یک تکنیک هوش مصنوعی قرار دارد به نام یادگیری عمیق. یادگیری عمیق بر اساس شبکه عصبی کار میکند. شبکههای عصبی اطلاعات ورودی را طی گذر از لایههایی سازمان یافته به خروجی بعدشان منتقل میکنند.
دانشمدان علوم کامپیوتر از سال 1950 مشغول به آزمایش شبکه عصبی بوده اند. اما دو اتفاق بزرگ در سالهای 2012 و 1986 منجر به صنعت یادگیری عمیق امروزی شدند. در سال 2012 – انقلاب یادگیری عمیق- توانستیم عملکرد شبکه عصبی را با ایجاد تعداد لایههای بسیار، به وضوح ارتقا دهیم. این دست آورد حاصل مهیا بودن میزان عظیم داده و قدرت محاسباتی بالای تامین شده تا آن سال بود .
نویسنده: پریسا ایلون
در اینجا توضیح خواهیم داد شبکه عصبی چیست، چطور کار میکند، و از کجا پیدا شد.
– شبکه عصبی از نظر زمانی به سال 1950 بر میگردد.

شبکه عصبی یک ایده قدیمی است. در سال 1957 مقالهای توسط Frank Rosenblatt چاپ شد که مفهوم اولیه شبکه عصبی را تحت عنوان پرسپترون توضیح داد. سال 1958 او سیستم اولیهای را طراحی کرد که میتوانست یک تصویر ساده را آنالیز کند و اشکال سادهای را شناسایی کند.
هدف اصلی Rosenblatt ساخت یک سیستم کاربردی برای کلاسبندی تصاویر بود. هر چند او مایل بود از این طریق کارکرد مغز را بهتر درک کند، اما، این مساله در زمینههای مختلفی علاقهمندان خود را پیدا کرد.
اساسا، هر نورون در شبکه عصبی تنها یک تابع ریاضیاتی است. هر نورون مجموعهای از ورودیهای وزن یافته را پردازش میکند. هر چه وزن سیناپسی بیشتر باشد آن سیناپس به میزان بیشتری خروجی نورون را متاثر میکند. خروجی نورون سپس به تابعی غیر خطی داده میشود به نام تابع فعال- که شبکه را قادر میکند پدیدههای غیرخطی پیچیده را مدل کند.
قدرت مدل اولیه Rosenblatt و در مجموع شبکه عصبی در توانایی یادگیری آن از مثالهای ارائه شده است. یک شبکه با تنظیم وزنها و بازخوردی که هر بار از عملکرد سیستم در مواجهه با مثالهای ورودی دریافت میکند قادر است یاد بگیرد.
اگر شبکه یک تصویر را به درستی کلاسبندی کند، مقادیر وزنهایی که در تعیین جواب درست کمک کرده بودند افزایش مییابند و مابقی وزنها کاهش و اگر شبکه تصویری را به نادرستی کلاسبندی کند تمام وزنها برعکس میشوند.
به این ترتیب شبکههای اولیه به نحوهای مشابه رفتار انسان یاد گرفتند. اما بعدا نشان داده شد این شبکههای عصبی داراری محدودیت بسیاری هستند.
شبکه عصبی اولیه Rosenblatt تنها دارای یک یا دو لایه قابل آموزش بود و این برای پردازش اطلاعات پیچیده پدیدههای واقعی ناکارآمد بود، به همین دلیل رفته رفته از محبوبیت شبکههای عصبی کاسته شد.
اما بعد در سال 1986 مقاله دیگری به چاپ رسید که مفهوم پس انتشار را معرفی میکرد، روشی عملی برای آموزش شبکههای عصبی عمیق.
تصور کنید شما یک مهندس در شرکت نرم افزارهای افسانهای هستید و میبایست برنامهای طراحی کنید که تشخیص دهد آیا در یک تصویر هات داگ وجود دارد یا نه. شما کار را با یک شبکه عصبی اولیه شروع میکنید و این شبکه یک تصویر را به عنوان ورودی دریافت میکند و در خروجی عددی بین صفر و یک قرار میدهد. عدد یک به معنی وجود هات داگ در تصویر است و عدد صفر به معنی عدم وجود آن.
برای آموزش شبکه، شما تصاویر بسیاری را جمع آوری میکنید و هرکدام را برحسب داشتن یا نداشتن هات داگ نشانهگذاری میکنید. سپس اولین تصویر را که دارای هات داگ است وارد شبکه میکنید و در خروجی عدد 0.07 را دریافت میکنید که گویای عدم وجود هات داگ است. این پاسخ اشتباه است و شبکه باید عددی نزدیک به یک را نشان دهد.
هدف از پس انتشار خطا تنظیم وزنهای سیناپسی است به نحوی که اگر همان تصویر مجدد نشان داده شد شبکه عدد بالاتری را در خروجی قرار دهد. به این منظور، الگوریتم پس انتشار با ارزیابی ورودی نورون در لایه خروجی شروع میکند. وزن هر ورودی عددی متفاوت است و پس انتشار خطا وزنها را برای ایجاد مقدار عددی بالاتر تغییر خواهد داد.
این الگوریتم از لایه دوم تا آخر مقادیر خطایی برای هر نورون تعیین میکند و در ادامه روند تنظیم وزنها را مرتبا از لایههای بعدی تا آخر تکرار میکند. به این ترتیب، شبکه تعیین میکند در صورت ایجاد تغییرات کوچکی در هر ورودی، خروجی چگونه تغییر میکند و آیا این تغییر منجر به پاسخ درستتر میشود یا نه .
پس انتشار خطا به طور قابل توجهی قابلیت شبکه عصبی را افزایش داد و افراد قادر شدند شبکههای پیچیدهای متشکل از چندین لایه طراحی کنند.
پس از آن، مقاله دیگری در سال 1998 به چاپ رسید که توضیح داد سیستمهای قوی تعیین الگو با اتکا به یادگیری خودکار ایجاد خواهند شد.
هر چند پس انتشار، شبکههای عمیق را از نظر محاسباتای ارتقا داد، اما هنوز شبکهها نیاز به منابع محاسباتی بیشتری داشتند. یک شبکه عصبی به نام AlexNet در مقالهای مطرح شد که نگاه مردم را به این مساله تغییر داد. در این مقاله نشان داده شد اگر شبکه عمیق علاوه بر توان محاسباتی قوی، دادههای بسیار بسیار زیادی داشته باشد عملکرد آن به طرز قابل توجهی بهبود مییابد.
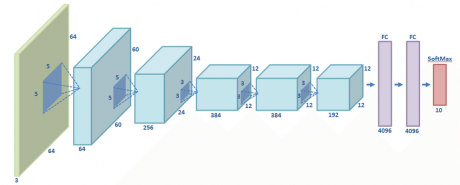
AlexNet توسط سه دانشمند حوزه کامپیوتر در دانشگاه تورنتو معرفی شد که قصد شرکت در یک مسابقه آکادمیک به نام را داشتند. برگزارکنندگان مسابقه مجموعهای عظیم متشکل از یک میلیون تصویر تهیه کرده بودند که هر کدام از آنها در گروههای مختلف نشانه گذاری شده بودند از جمله گیلاس یا پلنگ و غیره. محققین هوش مصنوعی میبایست نرم افزار یادگیری ماشین خود را به کمک تعدادی از تصاویر آموزش میدادند و بعد در مورد نشانه بقیه تصاویر آن را ارزیابی میکردند. نرم افزارهای رقابتی پنج نشانه ممکن را از بین هزار نشانه برای هر تصویر انتخاب میکردند. اگر یکی از این نشانهها با نشانه واقعی مطابقت داشت پاسخ صحیح در نظر گرفته میشد.
مساله پیچیده بود و تا قبل از آن در سال 2012 نتایج چندان درخشان نبودند.
در سال 2012 تیم AlexNet با 16 درصد خطا رقبا خود را کنار زد.
محققان دانشگاه تورنتو برای دستیابی به این موفقیت تکنیکهای متعددی را استفاده کردند. یکی از آنها استفاده از شبکه عصبی پیچشی بود.
Jie Tang محقق هوش مصنوعی میگوید” مثل این هست که یک شابلون یا الگو تهیه کنید و بعد آن را برابر هر نقطه از عکس مطابقت دهید. ” شما یک شابلون تصویر سگ دارید و بعد گوشه بالای تصویر را با شابلون خود مقایسه میکنید تا ببینید آیا مشابه است؟ اگر نه شابلون را روی تصویر جا به جا میکنید تا آن را پیدا کنید. شابلون مطابق خواهد شد و نیازی نیست هر قسمت از شبکه عصبی کلاسبندی مربوط به سگ مجزایی برای خود داشته باشد.
نکته مهم دیگر در موفقیت AlexNet استفاده از کارتهای گرافیکی برای افزایش سرعت پروسه یادگیری بود. کارتهای گرافیکی توان پردازش موازی بالایی دارند که مناسب آموزش تکرار شونده درگیر در شبکه عصبی است.
در نهایت، موفقیت AlexNet مدیون مجموعه بزرگ داده ImageNet بود. یک میلیون تصویر. در واقع ترکیبی از یک شبکه پیچیده و مجموعه دیتا عظیم که اجازه داد AlexNet به موفقیت چشم گیری نائل شود.
در حقیقت، تمام این امکانات قبل از موفقیت AlexNet هم وجود داشت اما کسی به فکر یکی کردن آنها نبود.
عمیقتر شدن شبکه بدون بزرگ بودن مجموعه آموزشی منجر به عملکرد خوبی نمیشد و برعکس بزرگ بودن داده نمیتواند عملکرد یک شبکه عصبی ساده را به میزان قابل توجهی بهبود دهد. هر دو لازم اند، هم داده کلان و هم شبکه عمیق و توان محاسباتی زیاد برای آموزش دیدن در یک بازه زمانی معقول. تیم AlexNet برای اولین بار تمام اینها را در یک نرم افزار جمع کرد.
پس از این موفقیت کسب شده توسط شبکه عصبی عمیق، افراد بسیاری در حوزه آکادمیک و صنعت متوجه ارزش آن شدند.
انقلاب یادگیری عمیق به سرعت وارد صنعت شد. گوگل از این تکنولوژی برای جستجوی تصویر و فیسبوک و اپل در نرم افزارهای تشخیص چهره و اشیا بهره بردند. یادگیری عمیق در تشخیص صدا نیز وارد شده است و شرکت های بسیاری در تشخیص کلمه ادا شده توسط فرد یا تولید یک صدای طبیعی از آن استفاده میکنند.
یادگیری عمیق به دلیل کاربردی بودن در حوزههای مختلف طرفداران بسیاری پیدا کرده است. در چند دهه گذشته دانشمندان ساختارهای مختلفی برای کاربران طراحی کردهاند که قابل استفاده در برنامههای یادگیری هستند، از جمله کانولوشنهایی که تشخیص تصویر موفقی دارند. یادگیری عمیق قادر است الگوهای پیچیده بسیاری را بدون کمک انسان تشخیص دهد. میتوان انتظار داشت در سالهای آینده، پیشرفت بسیاری در این زمینه ایجاد شود.
دوره های مرتبط

آموزش تولباکس EEGLAB-پیش پردازش سیگنال EEG

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

اصول برنامه نویسی پایتون Python

دیدگاه ها