
AlexNet:معماری که CNNها را به چالش کشید
- دسته:اخبار علمی
- هما کاشفی
سالها پیش، ما هنوز از دیتاستهای کوچکی مثل CIFAR, NORB استفاده میکردیم که متشکل از دهها هزار تصویر بودند. این دیتاستها برای مدلهای یادگیری ماشین مناسب بودند تا تسکهای تشخیص ساده را یاد بگیرند. با این حال، زندگی واقعی هرگز ساده نیست و متغیرهای بسیار بیشتری نسبت به آنچه در این دیتاستهای کوچک یافت میشود، دارد. در دسترس بودن دیتاستهای بزرگ مانند ImageNet که از صدها هزار تا میلیونها تصاویر برچسب گذاری شده تشکیل شدهاند، نیاز به یک مدل یادگیری عمیق بسیار توانمند را افزایش داده است. پس Alexnet معرفی شد.
مسئله
شبکه های عصبی کانولوشنی (CNN)همیشه مدل مورد استفاده برای تشخیص اشیا بوده اند-آنها مدلهای بسیارقوی بوده اند که کنترل آنها ساده بوده و آموزش سادهای نیز دارند. حتی زمانی که این شبکهها روی میلیونها تصویر استفاده میشوند، دچار بیش برازش نمیشوند. عملکرد آنها تقریباً مشابه با شبکههای عصبی Feed Forward با همان سایز است. تنها مشکل آن است در تصاویر با رزولوشن بالا دیده میشود. در مقیاس ImageNet، باید نوآوری وجود داشته باشد تا بر روی GPUها بهینه شوند و در عین حال که عملکرد بهبود داده میشود، زمان آموزش نیز کاهش یابد.
دیتاست( ImageNet)
این دیتاست از بیش از 15 میلیون تصویر با رزولوشن بالا تشکیل شده است که با 22 هزار کلاس برچسب زده شدهاند. کلیدک تصاویر web scraping و برچسب زنندههای انسانی. ImageNet حتی رقابت خاص خود را دارد: چالش تشخیص بصری مقیاس بزرگ ImageNet (ILSVRC). این رقابت از زیرمجموعهای از تصاویر ImageNet استفاده میکند و محققان را به چالش میکشد تا به نرخ خطای top-5 برسند. در این رقابت، داده یک مسئله نیست؛ در حدود 1.2 میلیون تصاویر آموزشی، 50 هزار تصویر validation و 150 هزار تصاویر تست وجود دارند.
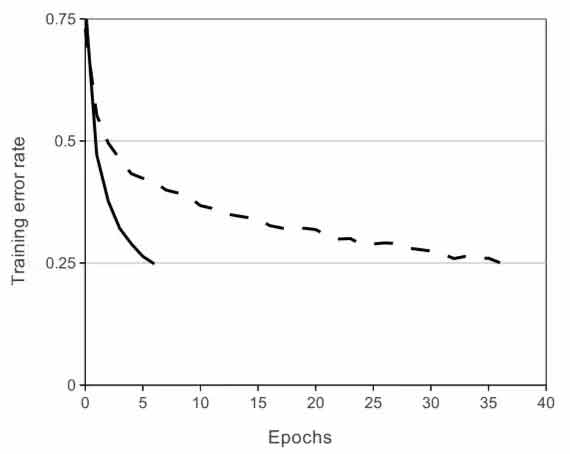
شبکه عصبی کانولوشنی که از ReLu استفاده میکند به نرخ خطای 25% روی CIFAR-10 رسیده است که شش برابر سریعتر از شبکههای کانولوشنی است که از tanh استفاده میکنند.
Alexnet
این معماری از هشت لایه تشکیل شده است: پنج لایه کانولوشنی اول و سه لایهی Fully Connected. اما این چیزی نیست که AlexNet را خاص میکند؛ اینها برخی از ویژگیهایی هستند که استفاده میشوند.
غیرخطی بودن ReLU
شبکه AlexNet از Relu به جای تابع tanh استفاده میکند. مزیت Relu در زمان آموزش آن نهفته است، شبکه CNN ای که از Relu استفاده میکند میتواند روی دیتاست CIFAR-10 به 25% خطا برسد شش برابر سریعتر از شبکهای که از tanh استفاده میکند.
چندین GPU
در آن زمان، GPUها هنوز هم 3 گیگابایت حافظه داشتند. این روند به خصوص زمانی بد بود که مجموعه دادهی آموزشی دارای 1.2 میلیون تصویر بود. AlexNet امکان آموزش روی چندین GPU را فراهم میآورد به این صورت که نیمی از نورونهای مدل را روی یک GPU قرار میدهد و نیمی دیگر را روی GPU دیگر قرار میدهد.
Poolingهای همپوشان
CNNها به طور معمول خروجی گروه نورونهای همسایه را بدون هیچ گونه همپوشانی، pool میکنند. با این حال، زمانی که نویسندگان مفهوم همپوشانی را معرفی کردند، شاهد کاهش خطا در حدود 0.5% بودند و دریافتند که مدلهایی که دارای pooling همپوشان هستند به احتمال کمتری دچار بیش برازش میشوند.
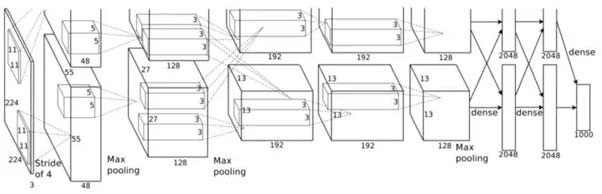
شماتیکی از معماری AlexNet
مسئله بیش برازش
AlexNet دارای حدود 60 میلیون پارامتر است که از نظر بیش برازش، یک مشکل به حساب میآید. از دو روش Data Augmentation و Dropout برای کاهش بیش برازش استفاده شده است:
نتایج
در نسخه 2010 رقابت ImageNet، بهترین مدل به خطای top-1 47.1% رسیده است. AlexNet حتی از این بهترین مدل هم پیشی گرفت. AlexNet میتواند اشیا off-center را تشخیص دهد. AlexNet در رقابت ImageNet در سال 2012 به نرخ خطای top-5 15.3% رسید.

5 برچسب محتمل خروجی AlexNet روی هشت تصویر ImageNet. برچسب درست زیر هر تصویر نوشته شده است.
AlexNet یک مدل فوق العاده قدرتمند است که به دقت بسیار بالایی روی دیتاستهای چالش برانگیز رسیده است. با این حال، حذف هر یک از لایههای کانولوشنی به شدت عملکرد AlexNet را کاهش میدهد. شبکه AlexNet یک معماری پیشرو برای تشخیص اشیا است و ممکن است کاربردهای بزرگی در حوزهی بینایی کامپیوتر هوش مصنوعی داشته باشد.
دوره های مرتبط

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دیدگاه ها