
7 راه موثر برای جلوگیری از overfitting در الگوریتمهای یادگیری ماشین
وقتی یک مدل یادگیری ماشین عملکرد خیلی خوبی روی داده آموزشی داشته باشد ولی روی داده جدید عملکرد خیلی پایینی داشته باشد، در این صورت به احتمال بسیار زیاد overfitting رخ داده است. در این مقاله میخواهیم در ابتدا با مفهوم Overfitting آشنا شویم و سپس توضیح دهیم که چطور میتوان متوجه شد یک مدل overfit شده و در آخر راههای موثر برای جلوگیری از overfitting را بررسی کنیم.
overfitting چیست؟
زمانی که مدل شما روی داده آموزش خیلی خوب عمل کند ولی روی داده تست خوب عمل نکند، در این حالت مدل overfit شده و بیش از حد روی تک تک داده های آموزش fit شده است. در نتیجه روی داده آموزش دقت خیلی خوبی خواهد داشت ولی اگر داده جدید ارائه شود مدل اصلا عملکرد خوبی نخواهد داشت. به این پدیده overfitting میگوییم.
اجازه بدهید با یک مثال سادهتر مفهوم overfitting را توضیح دهیم. احتمالا خیلی از شما در محل کارتون چنین تجربهای را در پروژه های هوش مصنوعی تجربه کرده اید:
یک مدلی را آموزش داده اید و مشاهده کرده اید که دقت کار خیلی خوب بوده است. سپس بلافاصله مدل رو در پروژههای عملی استفاده کردهاید. اما چند روز بعد از طرف کاربران گزارش شده که نتایج بسیار ضعیف هستند و مدل ارائه شده توسط شما اصلا خوب عمل نمیکند!
یا دوستانی که پروژههای آکادمی انجام میدهند، حتما مشاهده کردهاند که مدل در دادههای آموزش بسیار خوب عمل کرده است، ولی به محض اینکه داده تست (داده جدید) به مدل آموزش دیده ارائه دادهاند، عملکرد مدل به طرز عجیبی پایین آمده است.

به نظر شما چه اتفاقی افتاده؟
احتمالا خیلی از شما بیش از حد خوشبین بودهاید و مدل رو با یک پایگاه داده مناسب ارزیابی نکردهاید! یا احتمالا از داده آموزش به درستی استفاده نکردهاید! در ادامه توضیح میدهیم که چطور میتوانیم از این اشتباهات دوری کنیم!
وقتی میخواهیم یک مسئله ای رو حل کنیم، سعی میکنیم به مدل آموزش دهیم تا بتواند مسئله مورد نظر حل کند: برای مثال مدلی طراحی میکنید که یک شیئ را از داخل یک تصویر شناسایی کند، یا یک متن را براساس محتوا طبقهبندی کند، یا شناسایی صوت انجام دهد و مثالهایی از قبیل اینها…
برای انجام این کار، از یک پایگاه داده استفاده میکنید و مدل را آموزش میدهید تا مسئله مورد نظر را حل کند. اگر ما کارها را به درستی انجام ندهیم ممکن است مدل فقط روی داده آموزش خوب عمل کند، و وقتی داده جدید که کمی تغییرات نسبت به داده اصلی دارد به مدل ارائه دهیم، مدل روی آنها خوب عمل نکند. به چنین حالتی پدیده overfitting میگوییم.
برای دوستانی که با شکل راحتتر متوجه میشوند، تصویر زیر پدیده overfitting را به خوبی نشان میدهد.
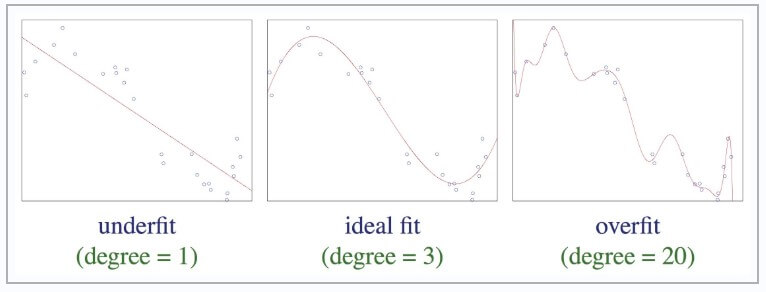
چطور میتوان متوجه شد که یک مدل overfit شده است؟
یک راه بسیار ساده برای اینکه تشخیص دهیم مدل overfit شده یا نه این است که پایگاه داده را به دو بخش آموزش و تست تقسیم کنیم، سپس عملکرد مدل را هم روی داده اموزش و هم روی داده تست بررسی کنیم. اگر مدل شما روی داده آموزش نسبت به داده تست عملکرد خیلی خوبی داشته باشد، برای مثال دقت روی داده آموزش 95 درصد و روی داده تست 50 درصد باشد، در این صورت به احتمال بسیار زیاد مدل شما overfit شده است.
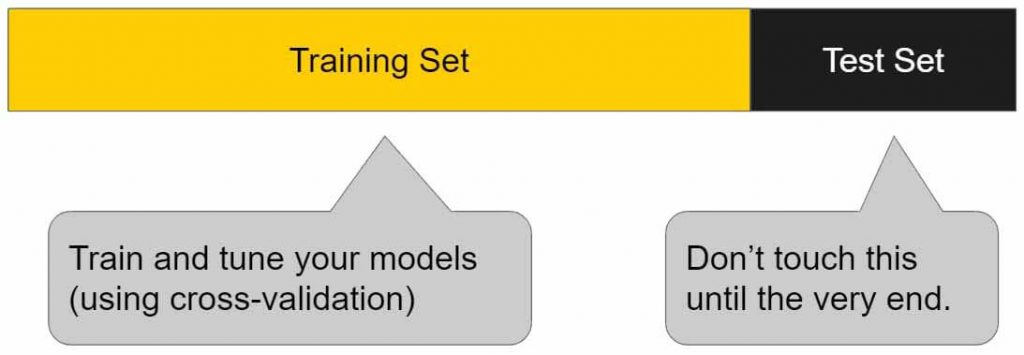
اینکه ما متوجه شویم مدل ما overfit شده است خیلی خوبه، ولی بحث مهم تر اینه که چطور از overfitting جلوگیری کنیم. در ادامه 7 راه موثر برای جلوگیری از overfitting را توضیح میدهیم.
-
تنوع پایگاه داده
مطمئن شوید که پایگاه داده مناسبی برای آموزش مدل استفاده میکنید. حتما داده مورد استفاده تنوع داشته باشد. برای مثال اگر میخواهید سیستمی طراحی کنید که بتواند از روی عکس، سگ را تشخص دهد، بهتره در تصاویر، از نژادها، رنگ ها اندازه ها و موقعیتهای مختلف سگ در پایگاه داده داشته باشید. یعنی همه تصاویر آموزشی مربوط به یک نژاد از تصویر نباشد! تا در پروسه تست و در عمل اگر یک عکس از نژاد دیگه سگها به مدل ارائه شد مدل توانایی شناسایی آن را داشته باشد.
اگر مدلهایی مثل شبکه های عصبی در پروژه ها استفاده میکنید، مدلهایی که در طول زمان و در تکرارهای مختلف آموزش میبنند، و مشاهده کردید که مدل خیلی سریع روی یک مقدار بهینه همگرا شد، احتمالا مدل شما overfit شده است. اگر پایگاه داده شما خیلی ساده باشد، مدل شما خیلی سریع روی داده فیت می شود و در نتیجه واریانس زیادی خواهد داشت.
-
استفاده از روش ارزیابی مناسب
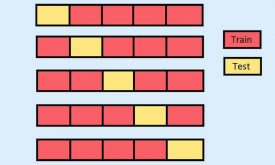
یکی از موثرترین راهها برای جلوگیری از overfit شدن مدل، استفاده از روش k-fold cross validation است. در این روش داده به k بخش یکسان تقسیم می شود، سپس مدل به تعداد k تکرار آموزش و تست می شود. در هر تکرار یک بخش برای تست و k-1 بخش برای آموزش استفاده می شود. با اینکار از تمام ظرفیت داده برای تست استفاده می شود، ولی با یک ترفند بسیار جالب دادهها طوری برای تست استفاده میشوند که در بین داده های آموزش نباشند. و چون تا حدودی مدل در هر تکرار با داده زیادی آموزش می بینید، احتمال overfitting پایین میآید.
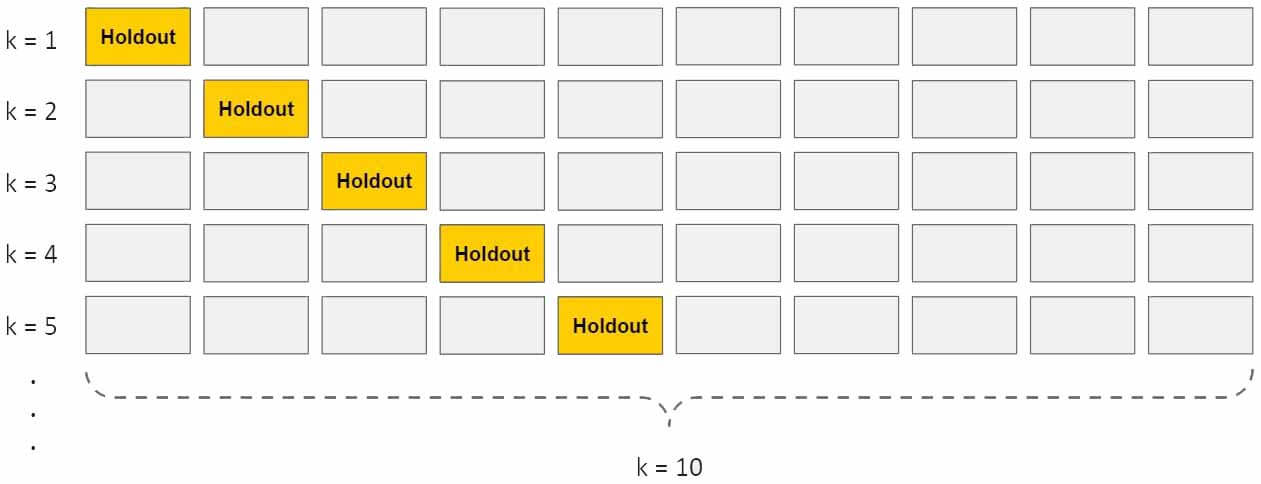
-
استفاده از داده آموزشی زیاد
یکی دیگر از راههای جلوگیری از overfitting استفاده از داده آموزشی زیاد است. داده زیاد به مدل کمک میکند شناخت بهتری از سیگنال ورودی بدست بیاورد. داده سوخت الگوریتمهای یادگیری ماشین است و هر چقدر بیشتر یعنی دانش بیشتر، شناخت بیشتر مدل از مسئله. در کل داده زیاد به مدل کمک میکند تا درک بهتری از سیگنال ورودی بدست بیاورد.
وقتی کاربر داده زیادی برای آموزش مدل استفاده میکند، باعث میشود مدل توان فیت شدن روی همه داده ها را نداشته باشد، و مدل را مجبور میکند که generalized بشود و در داده های جدید هم خوب عمل کند.
ولی ممکن است این روش همیشه جوابگو نباشد، چرا که ممکنه در داده زیاد، نویز زیادی هم باشد، و به جای کمک به مدل، کارو براش سختتر کند. یعنی مدل به جای اینکه به سمت شناخت بهتر سیگنال سوق پیدا کند ممکن است به اشتباه به سمت نویز میل پیدا کند.
-
کاهش تعداد ویژگیها
با اینکه خیلی از مدلها به طور ذاتی انتخاب ویژگی را انجام میدهند، ولی ما میتوانیم به طور دستی با کمک یه سری روشهایی در ابتدا ویژگیهای مناسب را انتخاب کرده و ابعاد داده را کاهش دهیم.
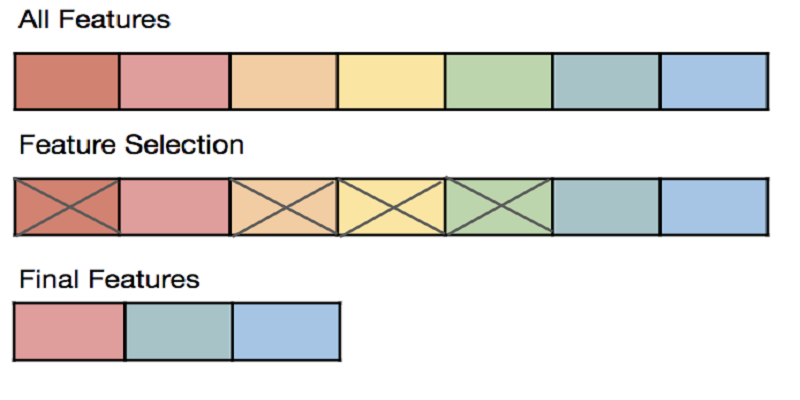
به خاطر داشته باشیم که هرچقدر ابعاد داده افزایش یابد، احتمال overfitting مدل به افزایش می یابد!
-
رگوله سازی (regularization)
رگوله سازی با کمک تکنیکهای مختلف، مدل را مجبور میکند که از پیچیدگی دوری کرده و تا جایی که میتواند سادهتر باشد.
رگولهسازی به نوع مدلی که استفاده میکنیم بستگی دارد. برای مثال اگر مدل ما درخت تصمیم است، اینجا محدود کردن تعداد شاخه های مدل یه نوع رگوله سازی است.
در بعضی موارد برای رگوله کردن یک الگورتیم، پارامتری به تابع هزینه الگوریتم اضافه میکنند و بعد با کمک روشهای cross validation مقدار مناسب برای این پارمتر انتخاب میکنند.
-
توقف زودهنگام پروسه آموزش
وقتی مدلی استفاده میکنیم که در طول تکرارهای مختلف آموزش میبیند، میتوانیم در هر تکرار عملکرد مدل را بررسی کنیم، و تا زمانی که مدل خوب عمل می کند، پروسه آموزش را ادامه بدهیم، ولی به محض اینکه متوجه شدیم مدل به سمت overfitting میل پیدا میکنه، آموزش را سریع متوقف کنیم.
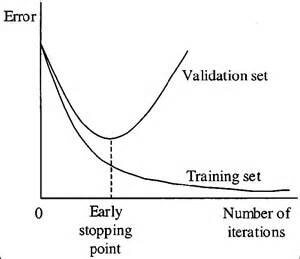
راهش این است که در هر تکرار مدل آموزش دیده را با داده تست(جدید) ارزیابی کنیم و خطا را محاسبه کنیم. تا زمانی که خطای مدل روی داده تست شیب رو به پایین دارد، پروسه آموزش را ادامه دهیم. ولی به محض اینکه خطای داده تست افزایش پیدا کرد، آموزش را متوقف کنیم.
امروزه از این تکنیک خیلی استفاده میکنند.
-
یادگیری جمعی(ensemble learning)
یادگیری جمعی تکنیکهایی در یادگیری ماشین است که برای تخمین خروجی داده، به جای استفاده از یک مدل، از چندین مدل به طور همزمان استفاده میکنند. معروفترین تکنیکهای یادگیری جمعی boosting و bagging هست.
با تفاوت این دو تکنیک boosting و bagging قبلا آشنا شده ایم و به طور مفصل این مسئله را بررسی کردهایم.
هر دو تکنیک به نوعی میخواهند مسئله overfitting را حل کنند ولی رویکردی کاملا عکس هم دارند. در boosting از مدلهای ساده استفاده میشود، و با کمک ترکیب این مدلهای ساده یک یادگیرنده قوی میسازند و مسئله را حل میکنند. در این رویکرد از آنجا که مدلهای پایه ساختار سادهای دارند، در نتیجه به تنهایی هر کدام خاصیت generalization خیلی خوبی دارند. در نتیجه هیچ کدام از این مدلها overfit نخواهند شد، در عین حال کنار هم مسئله پیچیده را حل میکنند.
ولی حواسمون به تکنیک boosting باشد، این تکنیک یک شمشیر دو لبه است! اگر خوب استفاده نشود خودش منجر به overfitting میشود!
تکنیک bagging بر خلاف boosting از مدل پایه قوی استفاده میکند و این مدلها ساختار پیچیدهای دارند و حتما پتانسیل overfit شدن را دارند. هدف این تکینک این است که جواب مدلها را smooth کنند. شکل زیر گویای کار هست.
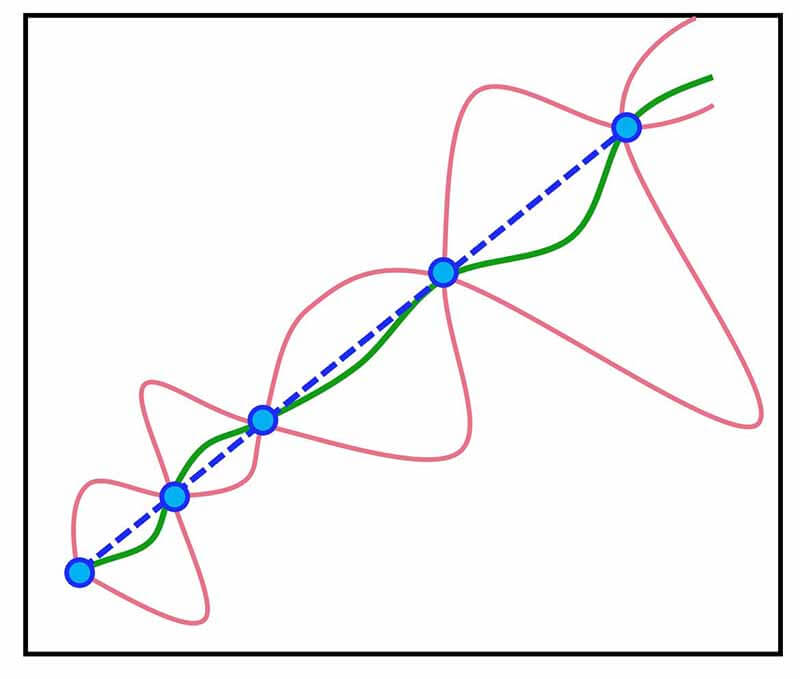
جالب است بدانیم که این تکنیک زمانی خوب عمل میکند و از overfitting جلوگیری میکند که مدلها پتانسیل overfitting داشته باشند!
خود من به شخصه برای رفع overfitting تکنیک bagging را استفاده می کنم. ولی وقتی مدلم بایاس داشته باشه، یعنی هم روی داده آموزش دقت پایینی داشته باشم و هر روی داده تست، میرم سراغ تکنیک boosting!
تجربه شخصی خودم
یه راه خیلی خوب برای اینکه مطمئن شوید مدل ارائه شده overfit شده است یا نه، اینه که نتایج را با مدلهای دیگری هم بدست بیاورید.. مثلا اگر از شبکه های عصبی برای حل مسئله استفاده میکنید، ببینید با svm به چه دقتی میرسید یا با knn یا lda. من خودم همیشه وقتی یک پروژه ای انجام میدهم، حتما با سایر مدلها هم نتایج رو بررسی میکنم. مخصوصا زمانی که از شبکههای عصبی استفاده میکنم حتما با سایر مدلها هم دقت رو بدست میارم تا ببینم اونا به چه صورت روی پایگاه داده عمل میکنند.
حالا جدا از بحث overfitting یک مبحثی رو هم بگم که تجربه خودم هست و در اکثر پروژه ها این کارو انجام میدم. اولا همیشه از روشهای مناسب ارزیابی برای ارزیابی مدل استفاده میکنم. مثل روش k-fold cross validation تا از لحاظ ارزیابی خیالم راحت باشه.
وقتی یک پروژه ی یادگیری ماشین انجام میدهم و به دقت خوبی نمیرسم، اولین کاری که میکنم اینه که با سایر مدلها هم عملکرد رو بررسی میکنم. مخصوصا زمانی که مدلم شبکه عصبی باشه! میدونین که شبکه های عصبی پروسه یادگیریشون داستان داره!
اگر دقت همه مدل ها خوب نباشه به این نتیجه میرسم که مشکل از پایگاه داده ام است. چون اگر پایگاه داده ام خوب بود، بین این مدلها حداقل باید یکیشون خوب عمل میکرد!
برای همین وقتم رو برای تعیین ساختار مناسب برای شبکه عصبی، و یا تنظیم پارامترهای شبکه عصبی تلف نمیکنم! چون مشکل یه جای دیگه است و سعیم رو میکنم پایگاه داده رو بهتر کنم. یا ویژگی های مناسبی استخراج کنم. خلاصه رو بخشهای قبل طبقه بندی وقت میزارم و اون بخش رو بهتر میکنم!
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

[…] در بین مدلهای غیرخطی ساده ترین را انتخاب کنیم تا دچار overfitting هم […]
[…] ولی متاسفانه خیلی از روش ها مرسوم در ابعاد بالا دچار overfitting شده و اصلا خوب عمل نمیکنند. و از آنجا که svm برای پیدا […]
[…] یادگیری ماشین با آن روبرو هستند. برخی از روش ها را برای جلوگیری از Overfitting در شبکه های عصبی توضیح […]
خسته نباشید. عالی بود
ممنون از لطف و محبت شما