Early Stopping در یادگیری ماشین چیست؟
- دسته:اخبار علمی
- هما کاشفی
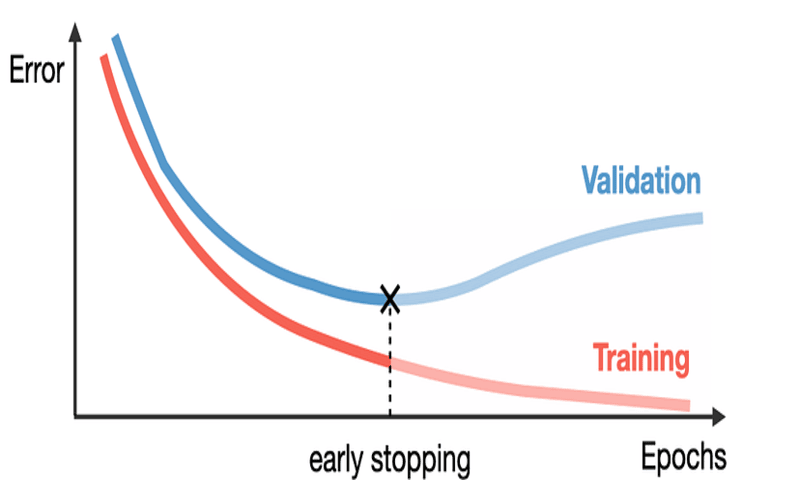
زمانی که مدلهای یادگیری ماشین را آموزش میدهیم ممکن است این مدلها روی دادهی آموزش بیش از حد آموزش ببینند و یا به اصطلاح دادهی آموزشی را حفظ کنند و بیش برازش (Overfitting) رخ دهد. اغلب در چنین مواقعی میبینیم که خطای مجموعه دادهی آموزش به طور پیوسته در طول زمان کاهش پیدا میکند اما خطای مجموعه دادهی Validation دوباره افزایش مییابد. رویکرد Early Stopping برای جلوگیری از این مسئله پیشنهاد شده است.
الگوریتم Early Stopping چیست؟
رویکرد Early Stopping به این صورت عمل میکند که پارامترهای مدل را در نقطهای برمیگرداند که خطای مجموعهی Validation پایینترین مقدار است. بنابراین مدل نهایی عملکرد بهتری روی مجموعه دادهی تست خواهد داشت.
این رویکرد هر زمان که خطا روی مجموعه داده Validation بهبود مییابد، یک کپی از پارامترهای مدل را نگهداری میکند. زمانی که آموزش مدل خاتمه مییابد به جای آنکه آخرین پارامترهای بدست آمده توسط مدل برگردانده شوند، این پارامترها برگردانده میشوند.
در رویکرد Early Stopping، تعداد تکرارهای آموزش مدل باید از قبل مشخص شود. الگوریتم زمانی خاتمه مییابد که خطا روی مجموعه دادهی Validation برای تعداد تکرارهای از قبل مشخص شده بهبود نیافته است.
الگوریتم Early Stopping در زیر نشان داده شده است.

در الگوریتم فوق n تعداد دفعات تکرار آموزش مدل و به روز رسانی پارامترهاست (پارامترها با θ نشان داده شدهاند). متغیر p که با نام patience شناخته میشود تعداد دفعات مشاهدهی بدتر شدن خطای مجموعهی Validation (یا افزایش خطای مجموعه Validation) است. برای مثال اگر مقدار p=7 باشد، فقط 7 بار بدتر شدن خطای مجموعهی Validation بررسی میشود و بعد از آن الگوریتم خاتمه مییابد. حتی اگر برای بار هشتم هم خطای مجموعهی Validation بدتر شود، دیگر بررسی نمیشود و با همان 7 بار بررسی، الگوریتم خاتمه مییابد. بنابراین انتخاب مقدار مناسب برای متغیر patience بسیار مهم است.
این استراتژی early stopping نام دارد
یکی از مسائل بسیار مهم در یادگیری ماشین آن است که چکار کنیم تا الگوریتم نه تنها روی مجموعه دادهی آموزش برای روی مجموعه دادهی تست نیز درست کار کند. مفهوم Regularization یا منظم سازی این است که هر تغییری که روی الگوریتم یادگیری ماشین اعمال میکنیم تا خطای Generalization و نه خطای آموزش را کاهش دهیم. تمام روشهای مورد استفاده در یادگیری ماشین که طراحی شدهاند تا خطای مجموعه داده ی تست را کاهش دهند Regularization نام دارند. شاید بتوان گفت رایجترین روش Regularization (منظم سازی) مورد استفاده در یادگیری عمیق همین early stopping است. علت آن است که این استراتژی هم موثر است هم ساده.
چرا میگوییم Early Stopping یک الگوریتم به شدت موثر انتخاب هایپرپارامتر است؟ بیایید اینطور به مسئله نگاه کنیم که در Early Stopping، تعداد گامهای آموزش نیز به عنوان یک هایپرپارامتر دیگر در نظر گرفته میشود. در این الگوریتم ما با تعیین تعداد گامهایی که مدل باید طی کند تا به مجموعه دادهی آموزشی فیت شود، ظرفیت موثر مدل را کنترل میکنیم. اکثر هایپرپارامترها در یادگیری ماشین با فرآیند پرهزینه سعی و خطا تعیین میشوند. به این صورت که ابتدا در آغاز آموزش، مقدار یک هایپرپارامتر را تعیین میکنیم. سپس روند آموزش را چندین بار تکرار میکنیم تا اثر این مقدار هایپرپارامتر را ببینیم. هایپرپارامتر «زمان آموزش» منحصر به فرد است. و به معنی یکبار اجرای مدل یا آموزش مدل است.
هزینهی الگوریتم Early Stopping
تنها هزینهی انتخاب این هایپرپارامتر به صورت خودکار با روش Early Stopping این است که عملکرد مدل روی مجموعه دادهی Validation در طی آموزش بررسی شود. در حالت ایدهآل این روند به موازات فرآیند آموزش روی یک ماشین جداگانه، CPU جداگانه و یا GPU جداگانه انجام میشود. اگر این منابع در دسترس نباشند، هزینهی این این ارزیابیهای دورهای به این صورت کاهش مییابد که مجموعه دادهی Validationای انتخاب شود که در مقایسه با مجموعه دادهی آموزش بسیار کوچکتر است.
هزینهی محاسباتی کوچک دیگر الگوریتم Early Stopping نیاز به نگهداری یک کپی از بهترین پارامترهاست.

این هزینه قابل چشم پوشی است، زیرا ذخیرهی این پارامترها در حافظهی بزرگتری مانند GPU قابل قبول و پذیرفتنی است. بنابراین ذخیرهی این پارامترها تأثیر بسیار کمی بر زمان کلی آموزش مدل تحمیل میکند.
الگوریتم Early Stopping یک فرم بسیار کم هزینه و سبک از رویکردهای Regularization برای بهبود قابلیت تعمیم مدل هاست. این الگوریتم هیچ تغییری در رویکرد آموزش، تابع هزینه و یا مجموعه مقادیر پارامتر مجاز ایجاد نمیکند.
بنابراین میتوان بدون اینکه به پویایی مدل صدمهای وارد شود، از الگوریتم Early Stopping استفاده کرد.
این دقیقاً بر خلاف روش Weight Decay برای منظمسازی است؛ زیرا باید مراقب بود که از weight decay به میزان زیادی استفاده نشود زیرا ممکن است مدل در مینی مم محلی (local minimum) گیر کند.
کاربرد Early Stopping
الگوریتم Early Stopping را میتوان به تنهایی یا به همراه سایر استراتژیهای Regularization استفاده کرد. حتی زمانی که از استراتژیهای Regularizationای استفاده میشود که تابع هدف را تغییر میدهند تا مدل قابل تعمیم بهتری پیدا کند. بسیار کم اتفاق میافتد که بهترین قابلیت تعمیم مدل در نقطه بهینه محلی تابع هدف باشد.
الگوریتم Early Stopping به یک مجموعه Validation نیاز دارد، این مجموعه بخشی از مجموعه دادهی آموزش است که برای آموزش به مدل تزریق نمیشود. برای اینکه از این دادههای اضافی بهترین استفاده شود، باید پس از آموزش اولیه و پس از آنکه early stopping تکمیل شد، آموزش اضافی مدل با این دادهها انجام شود. سپس در مرحلهی دوم تمام دادهها برای آموزش مدل استفاده خواهند شد.
در زیر الگوریتم استفاده از Early Stopping برای تعیین زمان آموزش و سپس آموزش مجدد با تمام دادهها آمده است.
استفاده از الگوریتم Early Stopping در کراس
برای پیاده سازی Early Stopping ما از Early Stopping Callback کراس استفاده میکنیم.
حال باید بدانیم Callback چیست؟
Callback آبجکتی است که میتواند در مراحل مختلف آموزش، عملیاتی را انجام دهد. (برای مثال در شروع یا پایان آموزش، قبل یا بعد از یک دستهی واحد)
به عنوان مثال فرض کنید من میخواهم برای خرید بیرون بروم اما هوا خیلی گرم است. میخواهم هر ساعت دمای هوا را بررسی کنم و هر وقت دما به زیر 35 درجه رسید بیرون بروم. بنابراین باید دما را در هر ساعت بررسی کنم. مثلاً از خواهر و برادرم میخواهم این کار را انجام دهند. بنابراین آنها مانند یک Callback عمل میکنند.
حال میخواهیم بدانیم که Early Stopping Callback چگونه با استفاده از Keras پیاده سازی میشود.
Python
tf.keras.callbacks.EarlyStopping( monitor="val_loss", min_delta=0, patience=0, verbose=0, mode="auto", baseline=None, restore_best_weights=False, )
نقش هر یک از پارامترهای Early Stopping در کراس
حال باید بدانیم هر یک از این پارامترها چه هستند.
monitor: این متغیر مشخص میکند چه کمیتی باید نظارت شود. در اینجا با val_loss را داریم که خطای مجموعه دادهی val است. بنابراین Callback باید خطای مجموعهی دادهی Validation را پس از هر تکرار آموزش بررسی کند. در صورتی که کاهش خطا متوقف شود، روند آموزش هم متوقف میشود. میتوانیم به جای خطای مجموعه دادهی آموزش، دقت را در نظر بگیریم، در چنین شرایطی زمانی که دیگر دقت بهبود نمییابد، روند آموزش مدل متوقف خواهد شد.
min_delta: حداقل تغییر مقدار است که به عنوان بهبود در نظر گرفته می شود. فرض کنید ما دقت را میخواهیم مانیتور کنیم. اگر min_delta برابر با 0.5 باشد، بنابراین دقت باید حداقل 0.5 درصد افزایش یابد تا به عنوان بهبود در نظر گرفته شود.
patience:گاهی اوقات در حین آموزش مدل ممکن است متوجه شوید که loss به طور مداوم کاهش نمییابد (یا دقت به طور مداوم افزایش پیدا نمیکند). loss ممکن است برای چند تکرار به جای کاهش، افزایش یابد اما در نهایت شروع به کاهش میکند. حال اگر روند آموزش را در لحظهای که بهبود مدل متوقف میشود، متوقف کنیم ممکن است به یک مدل underfit شده برسیم. بنابراین مدل را برای چند تکرار دیگر اجرا میکنیم . و اگر پس از این تکرارها، بهبودی در مدل ایجاد نشد میتوانیم آموزش مدل را متوقف کنیم. پس متغیر patience اگر loss را مانیتور کنیم، تعداد دفعات مشاهدهی بدتر شدن خطای مجموعهی Validation (یا افزایش خطای مجموعه Validation) است.
verbose: این متغیر میتواند مقدار 0 یا 1 داشته باشد. اگر 0 باشد پیامها را نشان نمیدهد و اگر 1 باشد پیامها را نشان میدهد یعنی مشخص میکند در چه دورهای آموزش مدل متوقف شده است.
mode: سه حالت برای این متغیر وجود دارد
min: آموزش مدل زمانی متوقف میشود که کمیت موردنظر دیگر کاهش نیابد.
max: آموزش مدل زمانی متوقف میشود که کمیت موردنظر دیگر افزایش نیابد.
auto: در این حالت به طور خودکار تصمیم گرفته میشود که بسته به نام کمیت مورد نظارت از max/min استفاده شود.
baseline: مانند یک مقدار آستانه است و اگر مدل نسبت به آن خط پایه، بهبودی از خود نشان ندهد، آموزش مدل متوقف میشود.
restore_best_weights: وزنهای بهترین epoch و شماره آن epoch نگهداری میشود.
پیاده سازی Early Stopping در روند آموزش مدل در کراس
برای پیادهسازی آن در Keras به صورت زیر عمل میکنیم:
Python
from keras.callback import EarlyStopping
es2= EarlyStopping(monitor=‘val_accuracy’, patience=25, verbose=1)
نیازی نیست همهی متغیرها را مقداردهی کنید و با مقادیر پیش فرض خود مقداردهی خواهند شد.
سپس در هنگام آموزش مدل، callback را به صورت زیر مقداردهی میکنیم:
Python
epochs = 500
learning_rate = 0.1
sgd = SGD(lr=learning_rate, momentum=0, decay=0, nesterov=False)
model.compile(loss=‘binary_crossentropy’, optimizer=sgd, metrics=[‘accuracy’])
history3=model.fit(X, Y, validation_split=0.33, epochs=epochs, batch_size=28, verbose=2,callbacks=[es2])
در دورههای پردازش سیگنال مغزی با کتابخانه MNE و دوره جامع و پروژه محور کاربرد شبکههای عمیق در بینایی ماشین، برای آموزش مدلها در پروژهها از رویکرد Early Stopping بهره گرفته شده است.
دوره های مرتبط

پردازش سیگنال مغزی با کتابخانه MNE پایتون

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
دیدگاه ها