
انواع روشهای یادگیری ماشین
در جلسه قبل فرق بین هوش مصنوعی، یادگیری ماشین و یادگیری عمیق را توضیح دادیم. در این جلسه قصد داریم انواع قوانین یادگیری را توضیح بدهیم. ما برای هوشمند کردن یک سیستم به دو تا عامل وابسته ایم: اول اینکه به انبوهی از داده برای آموزش نیاز داریم تا مدل بتواند طبق این داده ها یاد بگیرد. دوم اینکه مدل نیاز دارد طبق یک قانونی ساختار خودش را بهینه کند و در واقع آموزش ببیند. به طور کلی از دید شناسائی آماری الگو (pattern recognition) سه دسته یادگیری ماشین داریم: یادگیری نظارت شده، یادگیری بدون نظارت و یادگیری تقویتی. در ادامه این سه روش یادگیری را توضیح میدهیم.
یادگیری نظارت شده
همانطور که از اسم این یادگیری مشخص هست، در یادگیری نظارت شده مدل به کمک یک ناظر آموزش میبیند. در واقع در این روش ورودی(x) و خروجی (y) مشخص است و هدف مدل پیدا کردن رابطه (.) f بین ورودی و خروجی می باشد.
(y= f(x
به طور کلی یادگیری نظارت شده، ما مدل را با استفاده از یک سری داده ای که از قبل لبیل(خروجی مطلوب) آنها مشخص شده است، آموزش میدهیم و هدف این است که وقتی یک داده جدید (xn) که خروجی آن مشخص نیست به مدل ارائه شد، مدل بتواند خروجی مطلوب را تولید کند.
چر این یادگیری را نظارت شده می نامیم؟
به خاطر اینکه پروسه ی یادگیری (از روی داده آموزشی) یک الگورتیم توسط یک ناظر کنترل می شود. به این ترتیب که “الگوریتم یادگیری” در تکرارهای مختلف خروجی دادههای آموزش را تخمین می زند، و سپس این خروجیها توسط یک ناظر تصحیح می شود، و زمانی که الگورتیم به عملکرد قابل قبولی می رسد، پروسه یادگیری متوقف می شود.
چند مثال از یادگیری نظارت شده
مثال 1: تشخیص نوع تومور بیمار
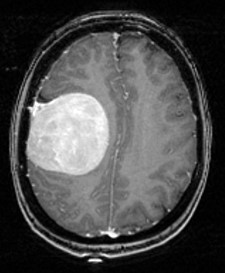
brain with tumor
برای مثال فرض کنید ما میخواهیم یک مدلی را آموزش دهیم که بتواند نوع تومور(خوشخیم یا بدخیم) یک بیمار را تشخیص دهد. در ابتدا ما از تعدادی بیمار که تعدادی از آنها تومور خوش خیم و تعدادی از آنها تومور بدخیم دارند داده ثبت می کنیم. و سپس از یک پزشک متخصص می خواهیم که نوع تومور این افراد را مشخص کند. فرض ما این است که پزشک صددرصد نوع تومور را درست تشخیص داده است. حال افرادی که تومور خوشخیم داشتند، لیبل صفر به آنها میدهیم و افرادی که تومور بدخیم داشتند لیبل یک به آنها میدهیم. الان ورودی (داده بیمار) و خروجی (لیبل تعیین شده توسط پزشک) مشخص است. اکنون مدل خود را آموزش میدهیم که رابطه بین ورودی و خروجی را پیدا کند. در پروسه آموزش داده به مدل ارائه میشود و مدل طبق دانشی که دارد یک خروجی به ازای هر داده تولید می کند، حال ما خروجی تولید شدهی مدل را به خروجی مطلوب( که پزشک تعیین کرده از قبل) مقایسه می کنیم. و میزان اشتباه مدل را اندازه گیری میکنیم و مدل خطای خود را تصحیح میکند. این پروسه انقدر تکرار می شود تا مدل بتواند به یک عملکرد قابل قبولی برسد. یعنی بتواند خروجیها درستی برای هر داده مشخص کند. حال این مدل آموزش دیده میتواند شبیه یک پزشک متخصص عمل کند و وقتی داده یک بیماری که نوع تومور آن مشخص نشده را به مدل آموزش دیده بدهیم میتواند نوع تومور را مشخص کند.
مثال 2: دسته بندی میوهها

fruit basket
فرض کنید به شما یک سبدی داده اند که پر از میوه ها مختلف است. و شما طبق تجربه اسم تمام میوه را میدانید. قرار است شما یک مدلی طراحی کنید که بتواند میوه ها را براساس رنگ و شکل از هم تفکیک کند. شما مدل را آموزش می دهید و اینجا ناظر شما هستید، زیرا که نوع میوه را میدانید. مدل شروع به یادگیری می کند و هر بار یک تخمینهایی میزند، و هر بار شما اشتباهات مدل را بازگو می کنید و مدل ساختار خودش را تغییر میدهد تا دفعه دیگه اشتباه نکند. این پروسه انقدر تکرار می شود تا اینکه مدل شما یاد میگیرد و تک تک میوه ها را براساس رنگ و شکل از هم جدا می کند.

banana
حال اگر یک داده جدید مثلا موز به مدل ارائه بدهید که جزء داده های آموزش نبود، مدل میتواند این میوه را در دسته موزها قرار دهد.
یادگیری نظارت شده به دوسته کلاسبندی و رگرسیون(پیشبینی) تقسیم می شود. که در جلسه بعد به طور مفصل این دو موضوع را توضیح خواهیم داد.
یادگیری بدون نظارت
در این دسته از یادگیری تنها ورودی (x) را داریم و خروجی مشخص نیست. در واقع اینجا ناظری وجود ندارد تا به الگوریتم در یادگیری کمک کند. هدف اصلی یادگیری بدون نظارت مدل کردن توزیع داده هست تا بتواند اطلاعات بیشتری در باره داده بدست آورد.
برعکس یادگیری نظارت شده، هیچ ناظری وجود ندارد و مدل مجبور است خودش ساختار مخفی دادهی بدون برچسب را پیدا کند.
مثال:خوشهبندی نمونهها

cats and dogs image for clustering
فرض کنید یک تصویر به شما تصویر زیر را نشان دادهاند که داخل آن یک سری سگ و گربه وجود دارد و فرض بر این است که شما تا الان هیچ سگ و گربه ای ندیده اید.
حال از شما میخواهند که حیوانات شبیه بهم را در یک دسته(خوشه قرار بدید). شما براساس خصوصیات ظاهری این حیوانات، آنها را در دو دسته مختلف قرار میدهید.
کاری که شما الان انجام دادید در واقع یک خوشه بندی بوده است و شما بدون هیچ دانش قبلی توانستید سگ ها و گربه ها را از هم تفکیک کنید. در واقع ماشین در یادگیری بدون نظارت به همین روال عمل می کند.
و داده ها را براساس خصوصیات و ویژگیهایشان در دسته های مختلف قرار میدهد.
یادگیری نظارت شده به دو دسته خوشهبندی و کاهش بعد تقسیم می شود. . که در جلسه بعد به طور مفصل این موضوع را توضیح خواهیم داد.
یادگیری تقویتی

reinforcement learning
یادگیری تقویتی یکی از گرایشهای یادگیری ماشینی است که از روانشناسی رفتارگرایی الهام میگیرد. این روش بر رفتارهایی تمرکز دارد که ماشین باید برای بیشینه کردن پاداشش انجام دهد. این مسئله، با توجه به گستردگیاش، در زمینههای گوناگونی مانند نظریه بازیها، نظریه کنترل، تحقیق در عملیات، نظریه اطلاعات، سامانه چندعامله، هوش ازدحامی، آمار، الگوریتم ژنتیک، بهینهسازی بر مبنای شبیهسازی بررسی میشود.
یادگیری تقویتی با یادگیری نظارت شده دو تفاوت عمده دارد، نخست اینکه در آن زوجهای صحیح ورودی و خروجی در کار نیست و رفتارهای ناکارامد نیز از بیرون اصلاح نمیشوند، و دیگر آنکه تمرکز زیادی روی کارایی زنده وجود دارد که نیازمند پیدا کردن یک تعادل مناسب بین اکتشاف چیزهای جدید و بهرهبرداری از دانش اندوخته شده دارد.
در ویدیوی داستان نحوه یادگیری شبکه عصبی است. در این انیمیشن به زیبای این مسئله به تصویر کشیده شده است. (اطلاعات بیشتر)
کاربردهای یادگیری تقویتی
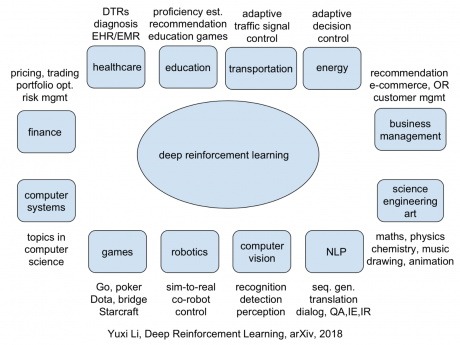
reinforcement learning applications
یادگیری تقویت در تولید، ماشینهای خودران ، مدیریت کسب و کار، سیستم های کامپیوتری، بینایی ماشین، آموزش، انرژی، امور مالی، بازی ها، مراقبت های بهداشتی، پردازش زبان طبیعی (NLP)، رباتیک، “علم، مهندسی و هنر” و حمل و نقل کاربرد دارد.
در ویدیوی زیر یکی از کاربردهای یادگیری تقویتی نشان داده شده است. و توضیح میدهید که چطور میتوان از یادگیری تقویتی برای کنترل ماشینها استفاده کرد.
دوره های مرتبط

شناسایی الگو(فصل هشتم): خوشه بندی (clustering)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)
سلام، روز بخیر
ممنونم بابت مطالب ارائه شده در صفحه، بسیار عالی بودند.
بنده روی یک مقاله کار میکنم که باید تعدادی شاخص کلیدی در مسئله انتخاب تامین کننده رو شناسایی کنم و در 4 بخش چابک، سبز، تاب آور و ناب تقسیم بندی کنم. شاخص های بسیار زیادی توی مرور ادبیات پیداکردم که هرکدام به نحوی مهم و تاثیر گذار هستند. سوال بنده اینه که اگر بخوام از بین این شاخص ها تعدادی کمی رو انتخاب و دسته بندی بکنم و به عنوان شاخص های اصلی در مسئله استفاده کنم، شما کدوم الگوریتم ماشین لرنینگ رو توصیه میکنید برای انجام ای
سلام
وقت بخیر
اگه منظورتان از شاخص ها، ویژگی های شما هست باید عرض کنم بهتره برای کاهش تعداد این شاخص ها از روشها انتخاب ویژگی استفاده کنید.
در فصل 7 دوره شناسایی الگو ، الگوریتمهای انتخاب ویژگی به صورت کامل آموزش داده شده اند.
https://onlinebme.com/product/season07-featrue-selection/
موفق باشید