درک شبکههای عصبی بازگشتی و LSTM
- دسته:اخبار علمی
- هما کاشفی
اگر تابحال از Apple’s Siri و Google voice search یا Google Translate استفاده کردهاید، باید بدانید که این اپلیکیشنها از شبکههای عصبی بازگشتی (RNN) استفاده میکنند که جدیدترین الگوریتمها برای دادههای توالی هستند. RNN اولین الگوریتمی است که به دلیل وجود حافظه داخلی، ورودی را به خاطر میسپارد و آن را برای مسائل یادگیری ماشین که شامل دادههای توالی هستند، مناسب میسازد. این یکی از الگوریتمهای اصلی یادگیری عمیق است که در چند سال گذشته به دستاوردهای شگفت انگیزی منجر شده است. در این پست، نحوهی عملکرد شبکههای عصبی بازگشتی توضیح داده میشوند و همچنین مسائل عمده و نحوهی حل آنها را پوشش خواهیم داد.
مقدمهای بر شبکههای عصبی بازگشتی (RNN)
RNNها شبکه عصبی قدرتمند و قوی هستند و میتوان آنها را امیدوارکنندهترین الگوریتمهای مورد استفاده دانست؛ زیرا تنها الگوریتمی است که حافظه داخلی دارد. مانند بسیاری از الگوریتمهای یادگیری عمیق دیگر، شبکههای عصبی بازگشتی نسبتاً قدیمی هستند. آنها ابتدا در دهه 1980 ایجاد شدند اما پتانسیل واقعی آنها را در سالهای اخیر مشاهده کردیم. افزایش قدرت محاسباتی همراه با حجم انبوه دادهای که اکنون باید با آن کار کنیم و ابداع شبکه Long Short-term memory (LSTM) در دهه 1990، باعث شدهاند که RNNها به شبکههایی پیشگام تبدیل شوند.
RNNها به دلیل وجود حافظه داخلی میتوانند مفاهیم مهمی در مورد ورودی دریافتی خود به خاطر بسپارند که به آنها این امکان را میدهد در پیش بینی اتفاقات بعدی بسیار دقیق باشند. به همین دلیل است که این الگوریتمها برای دادههای توالی مانند سری زمانی، داده گفتار، متن، دادههای مالی، صوت، ویدیو، آب و هوا و بسیاری موارد دیگر، الگوریتم ارجح هستند. شبکههای عصبی بازگشتی در مقایسه با سایر الگوریتمها میتوانند درک عمیقتری از توالی ایجاد کنند.
چه زمانی باید به سراغ RNNها بروید؟
«هر زمان که دنباله یا توالی از دادهها وجود داشته باشد و پویایی زمانی که دادهها را به هم متصل میکند بسیار مهمتر از محتوای مکانی هر فریم باشد» لکس فریدمن (MIT)
از آنجاییکه RNNها در نرم افزارهای Siri و Google Translate استفاده میشوند، شبکههای عصبی بازگشتی در زندگی روزمره بسیار دیده میشوند.
شبکه عصبی بازگشتی چطور کار میکند؟
برای درک درست RNNها، شما به دانشی در مورد شبکههای Feed Forward نرمال و دادهی توالی نیاز دارید. شاید بپرسید منظور از دادهی توالی چیست؟ دادههای توالی اساساً دادههای مرتب شدهای هستند که در آنها، اطلاعات مرتبط به دنبال هم میآیند. نمونههای آن، دادههای مالی یا توالی DNA هستند. محبوبترین نوع دادهی متوالی، شاید دادههای سری زمانی باشند که مجموعهای نقاط داده هستند که به ترتیب زمانی، پشت سر هم آمدهاند.
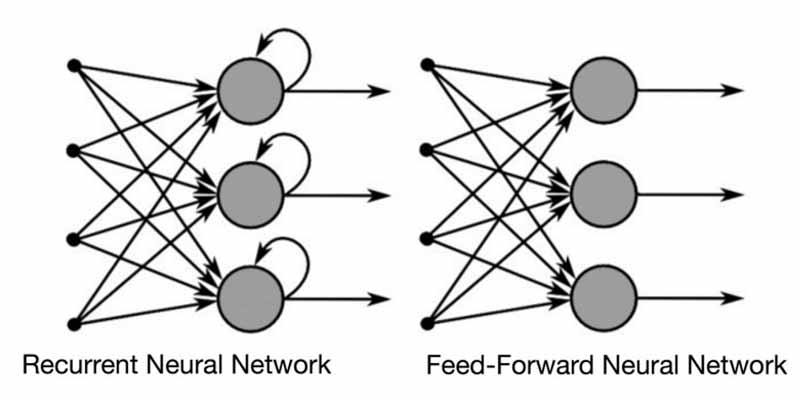
شبکههای RNN در برابر شبکههای Feed-Forward
شبکههای RNN و feed-forward نام خود را نحوهی ورود اطلاعات به خودشان میگیرند. در یک شبکه عصبی feed-forward، اطلاعات تنها در یک جهت حرکت میکند-از لایهی ورودی به لایههای پنهان و در نهایت به لایههای خروجی. اطلاعات مستقیماً در امتداد شبکه حرکت میکنند و هرگز از یک گره، دوبار اطلاعات عبور نمیکند.
شبکههای عصبی Feed-Forward هیچ حافظهای از ورودی دریافتی خود ندارند و در پیش بینی اتفاقات بعدی ضعیف عمل میکنند. از آنجاییکه یک شبکه Feed-Forward تنها ورودی فعلی را در نظر میگیرد، هیچ درکی از ترتیب در امتداد زمان ندارد. این شبکه نمیتواند چیزی در مورد آنچه که در گذشته اتفاق افتاده است را به یاد آورد، به جز آن چیزی که در زمان آموزش، آموخته است.
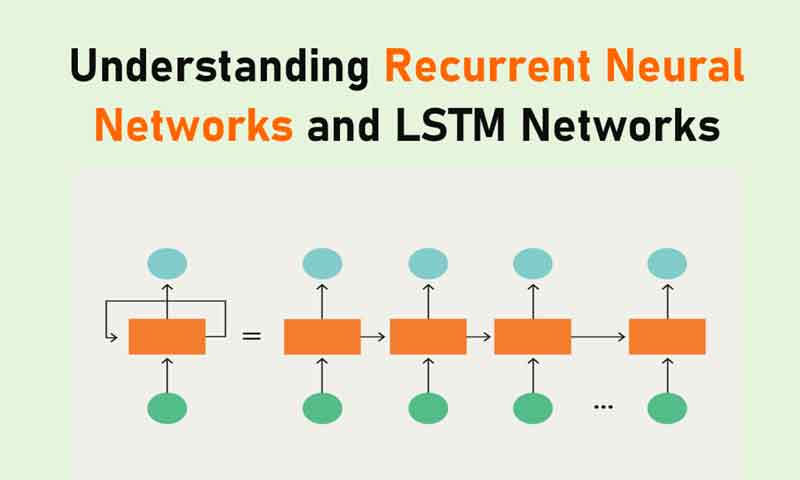
در یک شبکه RNN، اطلاعات وارد یک حلقه میشوند. زمانی که نوبت به تصمیم گیری میرسد، ورودی فعلی و آن چیزی که از ورودیهای قبلی دریافت کرده را در نظر میگیرد. دو تصویر زیر، تفاوت جریان اطلاعات بین یک شبکه RNN و شبکه Feed Forward را نشان میدهند.
یک RNN معمولی دارای حافظه کوتاه مدت است. RNN معمولی در ترکیب با LSTM، حافظهی بلند مدت خواهد داشت.
راه خوب برای نشان دادن مفهوم حافظه شبکه عصبی بازگشتی، توضیح آن با یک مثال است:
تصور کنید که یک شبکه عصبی Feed Forward معمولی دارید و کلمه “Neuron” را به عنوان ورودی به آن میدهید و شبکه آن را کاراکتر به کاراکتر پردازش میکند. زمانی که شبکه به کاراکتر “r” میرسد، دیگر کاراکترهای “n”, “e”, “u” را فراموش کرده است و تقریباً برای این شبکه غیرممکن است که کاراکتر بعدی را برای این نوع شبکه عصبی پیش بینی کند.
با این حال یک شبکه عصبی بازگشتی به دلیل آنکه حافظه داخلی دارد میتواند آن کاراکترها را به خاطر بسپارد. این شبکه، خروجی تولید میکند و آن خروجی را کپی میکند و دوباره به شبکه بازمیگرداند.
به زبان ساده میتوان گفت: شبکههای عصبی بازگشتی، گذشتهی بلافاصله قبل خود را به زمان حال اضافه میکنند.
بنابراین یک RNN دو ورودی دارد: حال و گذشته نزدیک. این مسئله بسیار مهم است، زیرا توالی دادهها حاوی اطلاعات مهمی درباره آنچه که در آینده میآید، هست و به همین دلیل است که یک شبکه RNN میتواند کارهایی بکند که الگوریتمهای دیگر نمیتوانند انجام دهند. یک شبکه عصبی Feed-Forward مانند سایر الگوریتمهای یادگیری عمیق، یک ماتریس وزن به ورودیهای خود اختصاص میدهد و سپس خروجی را تولید میکند. توجه داشته باشید که RNNها وزن را به ورودی فعلی و همچنین به ورودی قبلی اختصاص میدهند. علاوه بر این، یک شبکه عصبی بازگشتی را هم از طریق گرادیان نزولی و هم پس انتشار خطا (BPTT) تغییر میدهد.
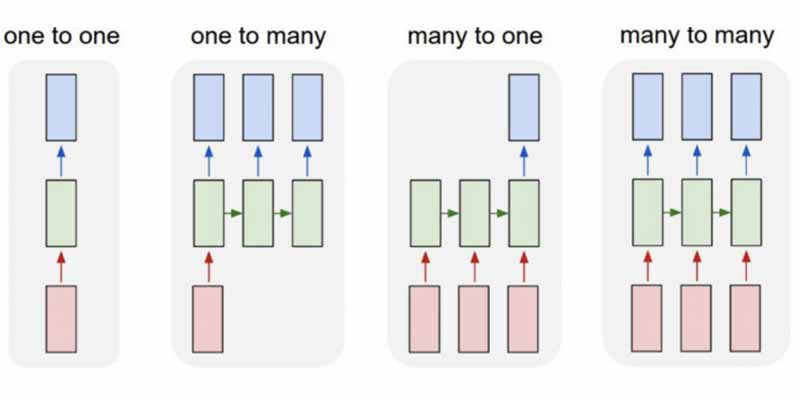
انواع RNNها
- One to One
- One to Many
- Many to One
- Many to Many
همچنین توجه داشته باشید در حالیکه شبکههای عصبی Feed-Forward یک ورودی را به یک خروجی نگاشت میکنند، RNNها ممکن است یک ورودی را به چند خروجی، چند ورودی به چند خروجی (ترجمه)، چند ورودی به یک خروجی (کلاسبندی صوت) نگاشت کنند.
پس انتشار در طول زمان
برای درک مفهوم پس انتشار در طول زمان، ابتدا باید مفاهیم Forward و Backpropagation را به خوبی درک کنید.
پس انتشار یا BackPropagation چیست؟
پس انتشار (به اختصار BP یا backprop) به عنوان الگوریتم اصلی در یادگیری ماشین شناخته میشود. پس انتشار برای محاسبه گرادیان تابع خطا با توجه به وزنهای شبکه عصبی استفاده میشود. الگوریتم، مسیر خود را به سمت عقب و از لایههای متعدد گرادیان طی میکند تا مشتق جزئی خطا را با توجه به وزنها پیدا کند. سپس backprop از این وزنها برای کاهش حاشیه خطا در هنگام آموزش استفاده میکند.
در شبکههای عصبی، شما اساساً Forward-Propagation انجام میدهید تا خروجی مدل خود را پیدا کنید و بررسی کنید که آیا این خروجی بدست آمده، درست است یا نادرست و پس از آن خطا را محاسبه کنید. پس انتشار چیزی جز رفتن از لایههای خروجی به سمت لایههای ورودی شبکه عصبی نیست که قرار است در طی این مسیر، مشتقات جزئی خطا با توجه به وزنها پیدا شوند و در نهایت شما میتوانید مشتقات جزئی را از وزنها کم کنید.
آن مشتقات سپس توسط گرادیان نزولی استفاده میشوند، الگوریتمی که میتواند به طور مکرر تابع معین را به حداقل برساند. سپس وزنها را تنظیم میکند (آنها را افزایش یا کاهش میدهد)، بسته به اینکه کدامیک از این موارد، خطا را کاهش میدهد. این دقیقاً همان چیزی است که یک شبکه عصبی در طی فرآیند آموزش، یاد میگیرد. بنابراین با روشBackProp ، اساساً سعی میکنید وزنهای مدل خود را در حین آموزش تغییر دهید. تصویر زیر، مفهوم Forward propagation و Backpropagation را در یک شبکه عصبی Feed-Forward نشان میدهد:
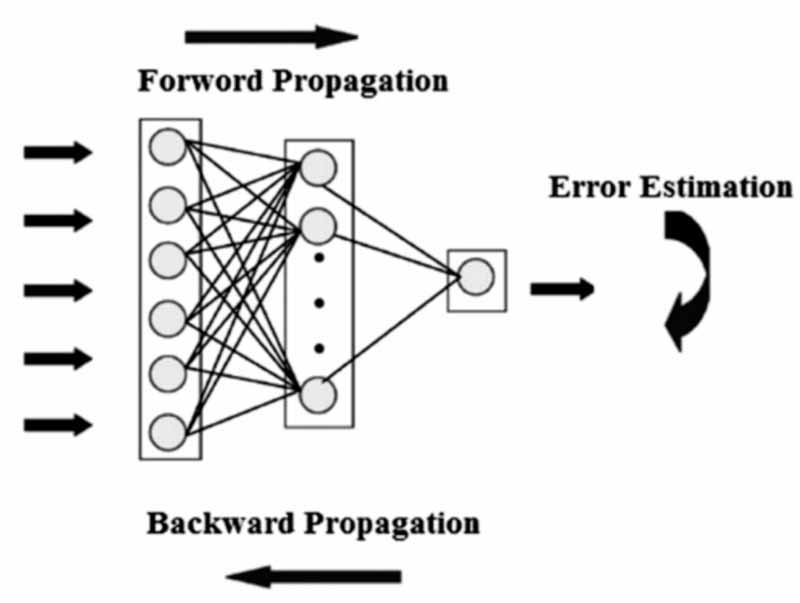
BPTT اساساً یک کلمهی فانتزی برای انجام پس انتشار روی یک unrolled RNN است. Unrolling ابزار تجسم سازی و مفهوم سازی است که به شما کمک میکند درک کنید که در یک شبکه چه میگذرد. اکثر اوقات هنگام پیاده سازی یک شبکه عصبی بازگشتی در فریم ورکهای رایج برنامه نویسی، پس انتشار به طور خودکار انجام میشود، اما شما باید بدانید که این شبکه چطور کار میکند تا بتوانید مشکلاتی که در طی فرآیند توسعه ایجاد میشوند را عیب یابی کنید.
شما میتوانید RNN را توالی از شبکههای عصبی ببینید که با روش پس انتشار، آنها را یکی پس از دیگری آموزش میدهید.
تصویر زیر یک Unrolled RNN را نشان میدهد. در سمت چپ، RNN پس از علامت مساوی، unrolled میشود. توجه داشته باشید که هیچ علامت مساوی وجود ندارد تا زمانی که گامهای مختلف زمانی تجسم سازی شوند و اطلاعات از یک گام زمانی به گام دیگر انتقال داده شوند. این تصویر همچنین نشان میدهد که چرا یک شبکه RNN را میتوان به صورت توالی از شبکههای عصبی دید.
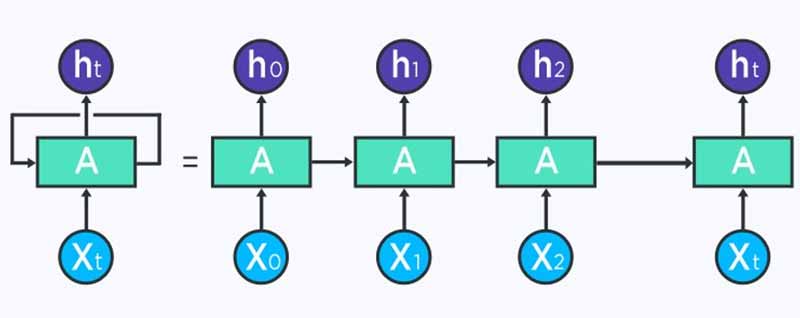
اگر BPTT انجام میدهید، باید ابتدا unrolling را مفهوم سازی کنید، زیرا خطای یک گام زمانی به گام زمانی قبلی بستگی دارد.
در BPTT، خطا از گام زمانی آخر به گام زمانی اول انتشار داده میشود. این روند امکانی را فراهم میآورد که خطا برای هر گام زمانی محاسبه شود و وزنها به روزرسانی میشوند. توجه داشته باشید که BPTT ممکن است از نظر محاسباتی پرهزینه باشد به خصوص زمانی که تعداد گامهای زمانی شما زیاد باشد.
دو مسئله در مورد RNN استاندارد
دو مانع عمده وجود دارد که RNN باید با آنها مقابله کند، اما برای درک آنها ابتدا باید بدانید که گرادیان چیست.
گرادیان، مشتق جزئی نسبت به ورودیهاست. اگر معنی آن را نمیدانید، فقط به این فکر کنید: گرادیان میسنجد که اگر ورودیها را کمی تغییر دهید، خروجی تابع چقدر تغییر میکند.
همچنین میتوانید گرادیان را شیب تابع در نظر بگیرید. هر چقدر گرادیان بیشتر باشد، شیب تندتر است و مدل سریعتر میتواند یاد بگیرد. اما اگر شیب صفر باشد، مدل یادگیری را متوقف میکند. گرادیان به سادگی، تغییر در تمام وزنها را با توجه به تغییر در خطا اندازه گیری میکند.
مسئله Exploding Gradient
Exploding Gradient زمانی بوجود میآید که الگوریتم، بدون دلیل خاصی، اهمیت بسیار زیادی به وزنها میدهد. خوشبختانه این مسئله را میتوان با gradient truncating حل کرد.
مسئله Vanishing Gradient
Vanishing Gradient زمانی رخ میدهد که مقادیر یک گرادیان خیلی کوچک میشود و مدل، یادگیری را متوقف میکند. این یک مشکل عمده در دهه 1990 بود و حل کردن آن بسیار سختتر از exploding gradient بود. خوشبختانه این مشکل با معرفی LSTM توسط Sepp Hochreiter و Juergen Schmidhuber حل شد.
شبکه Long-Short Term Memory (LSTM)
شبکههای LSTM نسخهی توسعه یافتهای از شبکههای عصبی بازگشتی هستند که حافظه را توسعه میدهند. بنابراین برای یادگیری از تجربیات مهمی که فاصله زمانی زیادی بین آنها وجود دارد، بسیار مناسب هستند.
شبکه LSTM چیست؟
شبکههای LSTM نسخهای از شبکههای RNN هستند که حافظه را بسط میدهند. LSTM به عنوان بلوک ساختاری لایههای RNN استفاده میشود. شبکههای LSTM به دادهها، «وزنهایی» را اختصاص میدهد و به RNN این امکان را میدهد تا اطلاعات جدید را وارد کند، اطلاعات را فراموش کند و یا به آنها اهمیت کافی دهد تا روی خروجی اثر بگذارد. واحدهای یک LSTM به عنوان واحدهای ساختاری لایههای یک RNN استفاده میشوند که اغلب شبکه LSTM نامیده میشوند.
LSTMها شبکههای RNN را قادر میسازند تا ورودیها را در مدت زمان طولانی به خاطر بسپرند. این بدین خاطر است که LSTMها حاوی اطلاعاتی در حافظه هستند، دقیقاً مانند حافظه یک کامپیوتر. LSTM میتواند اطلاعات را از حافظه خود بخواند، روی آن بنویسد و یا اطلاعات را پاک کند. این حافظه را میتوان به عنوان یک سلول گیت دار در نظر گرفت و در اینجا گیت به آن معنی است که سلول بر اساس اهمیتی که به اطلاعات میدهد، تصمیم میگیرد که اطلاعات را ذخیره یا حذف کند (یعنی گیتها را باز یا بسته کند). تخصیص اهمیت از طریق وزنها صورت میگیرد، که توسط الگوریتم آموخته میشوند. این بدان معنی است که شبکه در طول زمان یاد میگیرد که چه اطلاعاتی مهم هستند و کدام اطلاعات مهم نیستند.
در یک LSTM شما سه گیت دارید: گیت ورودی، گیت فراموشی و گیت خروجی. این گیتها تعیین میکنند که آیا اجازه ورودی جدید را بدهند (گیت ورودی)، اطلاعات را به دلیل مهم نبودن حذف کنند (گیت فراموشی) و یا اجازه دهند که در گام زمانی فعلی بر خروجی اثر بگذارد (گیت خروجی). در زیر تصویری از RNN با سه گیت آن، نشان داده شده است:
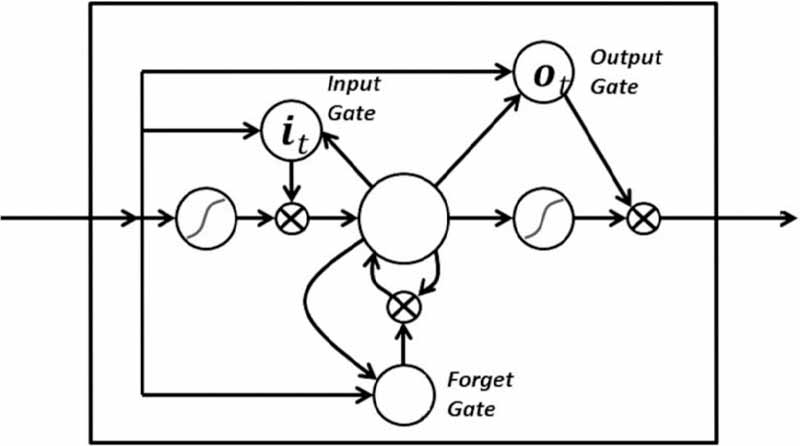
گیتها در LSTM به فرم سیگموئید هستند به این معنی که مقدار آنها از صفر تا یک متغیر است. مسئلهی مشکل ساز Vanishing Gradient از طریق LSTM حل میشود و باعث میشود که آموزش نسبتاً کوتاه شود و دقت بالا رود.
اکنون که درک درستی از نحوه عملکرد یک شبکه عصبی بازگشتی بدست آوردید، میتوانید تصمیم بگیرید که آیا این شبکه، الگوریتم مناسبی برای مسئله یادگیری ماشین شما هست یا خیر.
دوره های مرتبط

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دیدگاه ها