ترنسفورمرها (Transformers) چطور کار میکنند؟
- دسته:اخبار علمی
- هما کاشفی
ترنسفورمرها نوعی از معماری شبکه عصبی هستند که محبوبیت زیادی پیدا کردهاند. ترنسفورما اخیراً توسط OpenAI در مدلهای زبانی مورد استفاده قرار گرفتهاند همچنین اخیراً توسط DeepMind برای AlphaStar استفاده شدهاند. ترنسفورمرها برای حل مسائل انتقال توالی (Sequence Transduction) یا ترجمه ماشینی ساخته شدهاند. یعنی هر تسکی که یک دنبالهی ورودی را به یک دنبالهی خروجی تبدیل میکند. از جملهی این مسائل تشخیص گفتار، تبدیل متن به گفتار و … است.
برای آنکه مدلها بتوانند انتقال توالی انجام دهند، لازم است که نوعی حافظه داشته باشند. برای مثال فرض کنید که میخواهیم جمله زیر را به زبان دیگری (فرانسوی) ترجمه کنیم:
ترنسفورمرز یک گروه ژاپنی است. این گروه در سال 1968 و در دوران اوج تاریخ موسیقی ژاپن تشکیل شد.
در این مثال کلمهی «گروه» در جملهی دوم به گروه «ترنسفورمرز» در جمله اول اشاره دارد. این مفهوم در ترجمه مهم است. مثالهای زیادی وجود دارد که کلمات در برخی از جملات به کلمات جملات قبلی اشاره دارند.
برای ترجمهی جملاتی از این قبیل، یک مدل باید بتواند این نوع وابستگیها و ارتباطات را کشف کند. شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی کانولوشنال (CNN) به دلیل ویژگیهایی که دارند برای حل این مشکلات استفاده میشوند. ابتدا بیایید به این دو معماری و معایب آنها بپردازیم.
شبکههای عصبی بازگشتی (RNN)
شبکههای عصبی بازگشتی، حلقههایی درون خود دارند که به آنها امکانی میدهد تا اطلاعات را در خود نگه دارند.
حلقهها را میتوان به روش دیگر نیز در نظر گرفت. شبکه عصبی بازگشتی را میتوان کپیهای متعدد از یک شبکه دانست که هرشبکه، پیامی را به شبکه بعدی منتقل میکند. اگر یک حلقه را باز کنیم چه رخ میدهد:
شکل زنجیره مانندی بوجود خواهد آمد و این ماهیت زنجیره مانند نشان میدهد که شبکههای عصبی بازگشتی به وضوح به دنبال توالیها و لیستها هستند. به این ترتیب، اگر مثلاً بخواهیم متنی را ترجمه کنیم، میتوانیم هر ورودی را به عنوان کلمه در آن متن تنظیم کنیم. شبکه عصبی بازگشتی، اطلاعات کلمه قبلی را به شبکه بعدی منتقل میکند تا بتواند از آن اطلاعات استفاده کرده و پردازش کند. تصویر زیر نشان میدهد که معمولاً یک مدل توالی به توالی با استفاده از شبکههای عصبی بازگشتی چگونه کار میکند. هر کلمه به طور جداگانه پردازش میشود و توالی بدست آمده با انتقال یک hidden state به decoding state تولید میشود و سپس خروجی را تولید میکند.
![]()
مسئلهی وابستگیهای بلند مدت
یک مدل زبانی را در نظر بگیرید که سعی دارد کلمه بعدی را بر اساس کلمات قبلی پیش بینی کند. اگر بخواهیم کلمه بعدی در جمله “…The clouds in the ” را پیش بینی کنیم، به متن زمینهی بیشتر نیاز نداریم. کاملاً آشکار است که کلمهی بعدی sky است.
در این حالت که تفاوت بین اطلاعات مربوطه و موقعیت مورد نظر، کم است، RNNها میتوانند یاد بگیرند که از اطلاعات گذشته استفاده کنند و بفهمند کلمهی بعدی این جمله چیست.
اما حالاتی وجود دارند که به متن زمینهی بیشتری نیاز داریم. برای مثال فرض کنید که شما میخواهید کلمهی آخر این متن را پیش بینی کنید: …I grew up in France…I speak fluent اطلاعات اخیر حاکی از آن است که کلمهی بعدی احتمالاً یک زبان است، اما اگر بخواهیم بدانیم کدام زبان، به زمینهی فرانسه نیاز داریم که در متن عقبتر است.
زمانی که شکاف بین اطلاعات مربوطه و نقطهای که به آن نیاز است، زیاد شود، RNNها بی اثر میشوند. این امر به دلیل این واقعیت است که اطلاعات در هر مرحله انتقال مییابند و هر چه زنجیره طولانیتر باشد، احتمال از دست رفتن اطلاعات در طول زنجیره بیشتر میشود.
از نظر تئوریکی، RNNها میتوانند این وابستگیهای بلند مدت را یاد بگیرند. در عمل به نظر میرسد نمیتوانند آنها را یاد بگیرند. LSTM که نوع خاصی از RNN است سعی در حل این نوع مشکل دارد.
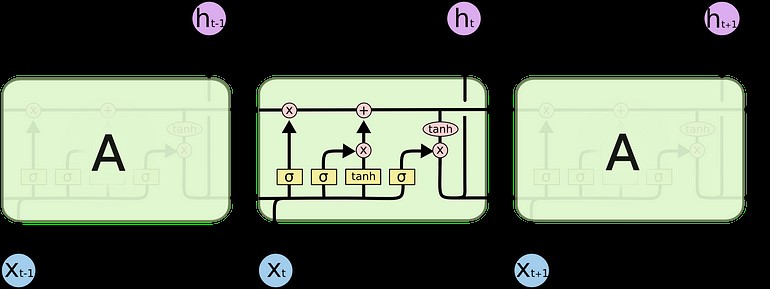
هر سلول، یک ورودی (یک کلمه در مورد ترجمه متنی)، وضعیت سلول قبلی و خروجی سلول قبلی را میگیرد. این ورودیها را دستکاری میکند و بر اساس آنها یک سلول جدید و یک خروجی تولید میکند. اینجا به جزئیات ساختار هر سلول نمیپردازیم.
در دورهی جامع و پروژه محور شبکه عصبی بازگشتی جزئیات این شبکه را به طور کامل شرح دادهایم.
در یک سلول هنگام ترجمه، اطلاعات یک جمله که برای ترجمه کلمه مهم است از یک کلمه به کلمهی دیگر منتقل میشود.
مشکلات مربوط به LSTMها
همان مشکلی که برای RNNها رخ میدهد برای LSTMها نیز رخ میدهد و زمانی که جملات خیلی طولانی هستند، LSTMها خیلی خوب عمل نمیکنند. دلیل آن است که احتمال حفظ متن از یک کلمه به کلمهی فعلی که در حال پردازش است، به نسبت فاصلهی بین دو متن به طور تصاعدی کاهش مییابد.
این بدان معناست که وقتی جملات طولانی هستند، اغلب اوقات مدل محتوای موقعیتهای دور در دنباله را فراموش میکند. مشکل دیگر RNN و LSTM این است که موازی سازی کار برای پردازش جملات دشوار است زیرا لازم است پردازش به صورت کلمه به کلمه صورت گیرد. نه تنها این مشکل وجود دارد بلکه مدلی برای پردازش وابستگیهای بلند مدت و کوتاه مدت وجود ندارد. به طور خلاصه، LSTMها و RNNها سه مشکل عمده دارند:
*محاسبات توالی مانع از امکان موازی سازی میشود.
*مدلسازی صریحی از وابستگیهای بلند مدت و کوتاه مدت وجود ندارد
*«فاصله» بین موقعیتها، خطی است.
مفهوم Attention
برای حل برخی از این مشکلات، محققان تکنیکی را ارائه کردهاند که با استفاده از آن به کلمات خاصی، توجه بیشتری میشود.
هنگام ترجمهی یک جمله، به کلمهای که در حال حاضر در حال ترجمهی آن هستم، توجه ویژهای دارم. زمانی که در حال نوشتن متن برای یک صدای ضبط شده هستم، به دقت به قسمتی که در حال رونویسی از آن هستم، گوش میدهم. و اگر از من بخواهید اتاقی که در آن نشستهام را توصیف کنم، در حین توصیف به اشیایی که در حال توصیف آنها هستم نگاهی خواهم انداخت.
شبکههای عصبی نیز میتوانند همین رفتار را داشته باشند و باید به بخشی یا زیرمجموعهای از اطلاعاتی که به آنها داده میشود، توجه بیشتری کنند. برای مثال یک RNN میتواند در خروجی RNN دیگر نیز شرکت کند. در هر گام زمانی، به موقعیتهای مختلف در RNN دیگر توجه میکند.
برای حل این مسائل، Attention یا توجه تکنیکی است که در شبکه عصبی استفاده میشود. برای RNNها، به جای آنکه کل جمله را در hidden state رمزگذاری کنند، هر کلمه یک hidden state مربوطه دارد که تا مرحلهی رمزگشایی منتقل میشود. سپس، hidden stateها در هر مرحلهی RNN برای رمزگشایی استفاده میشوند. GIF زیر نشان میدهد که چطور این اتفاق رخ میدهد. برای حل این مشکلات، Attention تکنیکی است که در شبکه عصبی استفاده میشود. برای RNNها، به جای آنکه فقط کل جمله را در حالت پنهان رمزگذاری کنند، هر کلمه دارای یک حالت پنهان متناظر است که تا مرحله رمزگشایی منتقل شود. سپس hidden state در هر مرحله از RNN برای رمزگشایی استفاده میشود. GIF زیر نشان میدهد که این اتفاق رخ میدهد.
![]()
ایدهی اصلی این است که ممکن است اطلاعات مرتبط در هر کلمه در یک جمله وجود داشته باشد. بنابراین برای رمزگشایی دقیق، باید هر کلمه ورودی را با استفاده از attention در نظر گرفت.
برای اینکه Attention در RNNها در انتقال توالی به کار رود، رمزگذاری و رمزگشایی را به دو مرحله اصلی تقسیم میکنیم. یک مرحله به رنگ سبز است و مرحله دیگر به رنگ بنفش است. مرحله سبزرنگ، مرحله رمزگذاری نام دارد و مرحله بنفش، رمزگشایی است.

مرحله سبز مسئول ایجاد hidden state از ورودی است. به جای انتقال تنها یک hidden state به رمزگشاها، تمام hidden stateهای تولید شده توسط «کلمه» جمله را به مرحله رمزگشایی منتقل میکنیم. هر hidden state در مرحله رمزگشایی استفاده میشود تا مشخص کند که شبکه باید به کجا توجه کند.
برای مثال، هنگام ترجمه جمله “Je suis étudiant” به انگلیسی نیاز است که هنگام ترجمه، مرحله رمزگشایی به کلمات مختلف نگاه کند.
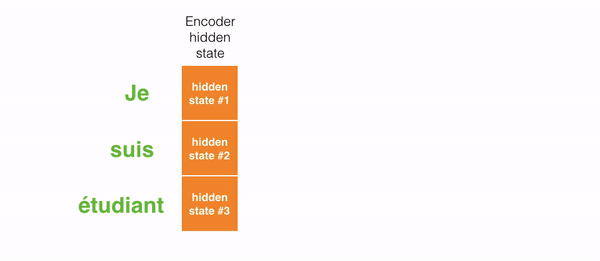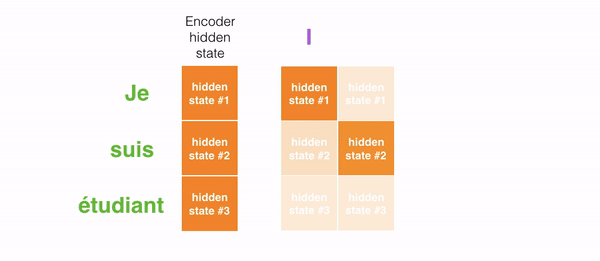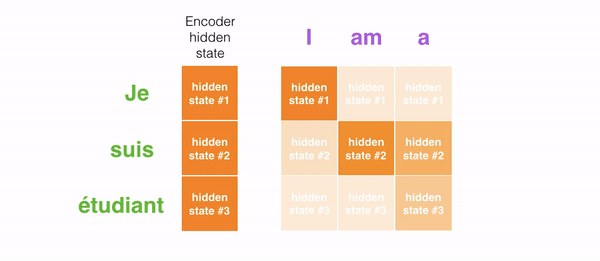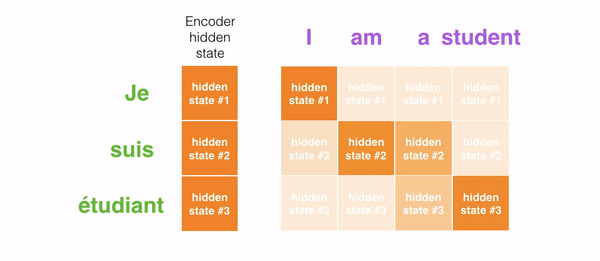
GIF فوق نشان میدهد که هنگام ترجمه جمله به انگلیسی، چطور وزنها اختصاص داده میشوند. هرچقدر رنگها تیرهتر باشند، وزن بیشتری به هر کلمه اختصاص داده میشود.
یا مثلاً وقتی جمله “L’accord sur la zone économique européenne a été signé en août 1992.” از فرانسوی به انگلیسی ترجمه میشود، به هر ورودی چقدر باید توجه شود.

اما برخی از مشکلاتی که در مورد آنها بحث کردیم، با RNNها و attention حل نشدهاند. برای مثال، پردازش ورودیها به صورت موازی امکانپذیر نیست. برای حجم وسیعی از متن، زمان ترجمهی متن طولانیتر میشود.
شبکههای عصبی کانولوشنی
شبکههای عصبی کانولوشنی به حل این مشکلات کمک میکنند، با استفاده از آنها میتوانیم:
موازیسازی (برای هر لایه) انجام دهیم
از وابستگیهای محلی استفاده کنیم
فاصله بین موقعیتها، لگاریتمی است
برخی از محبوبترین شبکههای عصبی برای انتقال توالی به نامهای Wavenet و Bytenet، شبکههای عصبی کانولوشنی هستند.

علت آنکه شبکههای عصبی کانولوشنی میتوانند به صورت موازی کار کنند آن است که هر کلمه در ورودی میتواند به طور همزمان پردازش شود و لزوماً به کلمات قبلی که باید ترجمه شوند، بستگی ندارند. نه تنها این، بلکه «فاصله» بین کلمه خروجی و هر ورودی برای CNN در مرتبه Log(N) است، که اندازه ارتفاع درخت تولید شده از خروجی تا ورودی است. این فاصله بهتر از فاصلهی خروجی RNN و ورودی است که در مرتبه N است.
مشکل اینجاست که شبکههای عصبی کانولوشنی لزوماً به حل مشکل کشف وابستگیها هنگام ترجمه جمله کمک نمیکنند. به همین دلیل است که ترنسفورمر ایجاد شدند، آنها ترکیبی از دو CNN با attention هستند.
ترنسفورمرها
برای حل مشکل موازی سازی، ترنسفورمرها سعی میکنند از رمزگذارها و رمزگشاها همراه با مدلهای attention استفاده کنند. Attention، سرعت اینکه مدل میتواند یک توالی را به توالی دیگر ترجمه کند، افزایش میدهد. بیایید نگاهی به نحوهی عملکرد Transformer بیندازیم. ترنسفورمر مدلی است که از توجه برای افزایش سرعت استفاده میکند. به طور خاص، از Self-attention استفاده میکند.
![]()
ترنسفورمر
ترنسفورمر، معماری شبیه به مدل قبلی دارد. اما ترنسفورمر از شش رمزگذار و شش رمزگشا استفاده میکند.
![]()
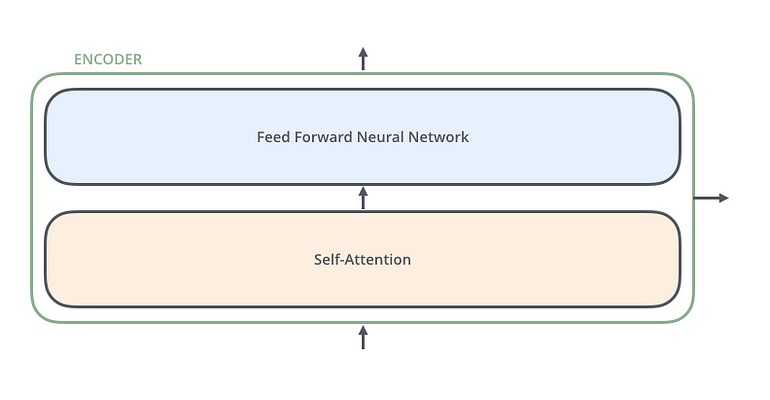
رمزگذارها بسیار شبیه به یکدیگر هستند. تمامی رمزگذارها، معماری مشابهی دارند. رمزگشاها، ویژگی یکسانی دارند یعنی آنها بسیار شبیه به یکدیگر هستند. هر رمزگذار از دو لایه تشکیل شده است: Self-Attention و Feed Forward Neural Network
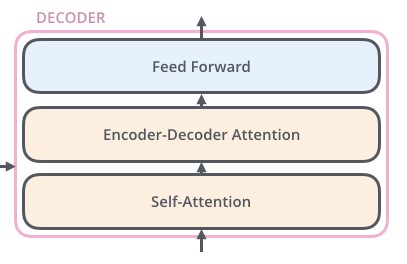
ورودیهای رمزگذار ابتدا از طریق یک لایه self-attention جریان مییابند. این به رمزگذار کمک میکند تا به کلمات دیگر در توالی ورودی نگاه کند تا یک کلمه خاص را رمزگذاری کند. رمزگشا دارای دو لایه است، اما بین آنها تنها یک لایه attention وجود دارد که به رمزگشا کمک میکند تا روی قسمتهای مربوطه جمله ورودی تمرکز کند.
Self-Attention
بیایید به بردارها/تنسورهای مختلف نگاهی بیندازیم و ببینیم بین آنها اطلاعات چگونه جریان مییابد تا ورودی مدل آموزش دیده را به خروجی تبدیل کند. همانطور که در برنامههای NLP شایع است، با تبدیل هر کلمه ورودی به یک بردار شروع میکنیم و برای این منظور از الگوریتم embedding استفاده میکنیم.

هر کلمه در یک بردار با سایز 512 قرار داده شده است. این بردارها را با این کادرهای ساده نشان خواهیم داد.
Embedding در رمزگذار انجام میشود. انتزاعی که برای همه رمزگذارها مشترک است این است که آنها لیستی از بردارها به اندازه 512 را دریافت میکنند.
در رمزگذار پایین، کلمه embedding خواهد بود اما در رمزگذارهای دیگر، خروجی رمزگذاری است که مستقیماً زیر آن قرار دارد. پس از جاسازی کلمات در توالی ورودی، هر یک از آنها، از طریق دو لایهی رمزگذار جریان مییابند.
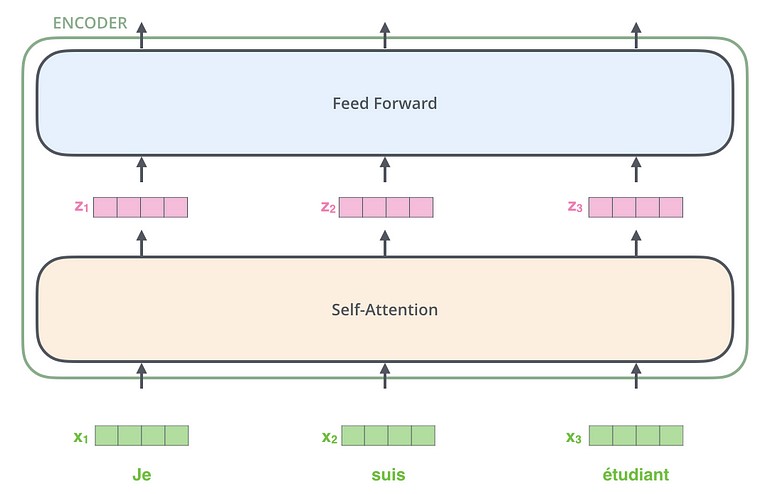
در اینجا یک ویژگی کلیدی ترنسفورمر را بررسی میکنیم واین است که کلمه در هر موقعیت از طریق مسیر خود در رمزگذار جریان مییابد. بین این مسیرها در لایهی self-attention، وابستگیهایی وجود دارد. لایهی feed-forward این وابستگیها را ندارد با این حال، مسیرهای مختلف را میتوان به صورت موازی اجرا کرد.
در مرحله بعد، مثال را با یک جمله کوتاهتر تغییر میدهیم و نگاه میکنیم که در هر زیر لایهی رمزگذار چه رخ میدهد.
Self-Attention
بیایید ابتدا نحوهی محاسبه self-attention را با استفاده از بردارها بررسی کنیم، سپس به نحوهی پیاده سازی آن با استفاده از ماتریسها ادامه میدهیم.
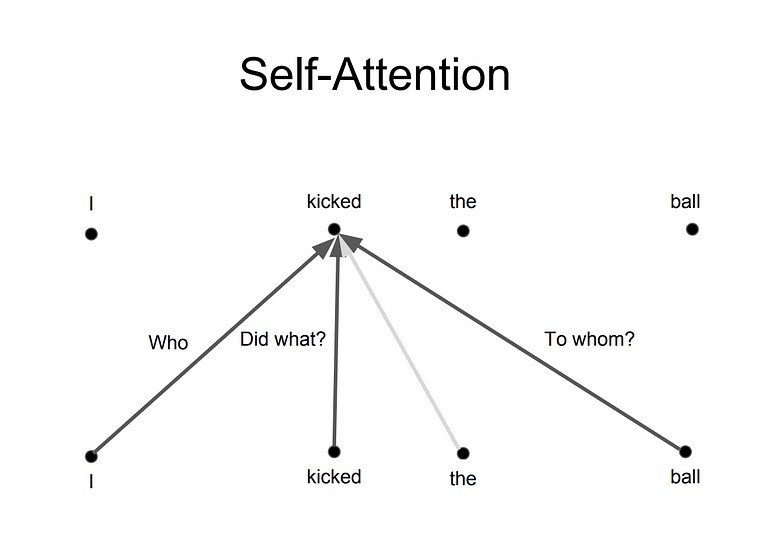
رابطه بین کلمات و توجه درست به یک کلمه
اولین گام در محاسبه self-attention آن است که سه بردار از هر بردار ورودی رمزگذار بسازیم (در این مورد، embedding هر کلمه). بنابراین برای هر کلمه یک بردار Query یک بردار Key و یک بردار Value میسازیم. این بردارها با ضرب embedding در سه ماتریس ایجاد شدهاند که در حین فرآیند آموزش، آنها را آموزش دادهایم.
توجه داشته باشید که این بردارهای جدید از نظر ابعاد کوچکتر از بردار embedding هستند. ابعاد آنها 64 است در حالیکه Embedding و بردارهای ورودی/خروجی رمزگذار دارای ابعاد 512 هستند. آنها نباید کوچکتر از این ابعاد باشند، این یک انتخاب معماری برای آن است که محاسبات multiheaded attention ثابت باشند.
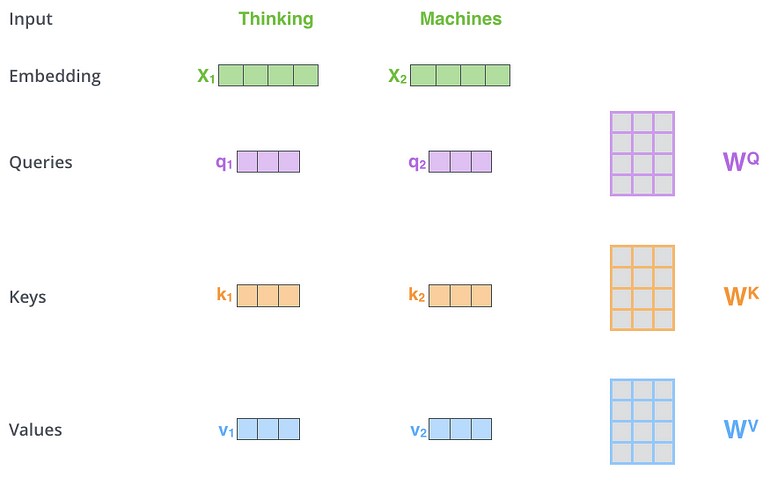
ضرب در ماتریس وزن WQ یک بردار q1 تولید میکند که بردار “query” مرتبط با آن کامه است. ما با ایجاد query و key و یک مقدار برای هر کلمه در جمله ورودی، کار را تمام میکنیم.
بردارهای query، key و value چه هستند؟
آنها انتزاعاتی هستند که برای محاسبه و تفکر در مورد attention مفید هستند. هنگامی که در ادامه بخوانید که attention چطور محاسبه شده است، تقریباً تمام آنچه که باید در مورد نقش هر یک از این بردارها بدانید را خواهید دانست.
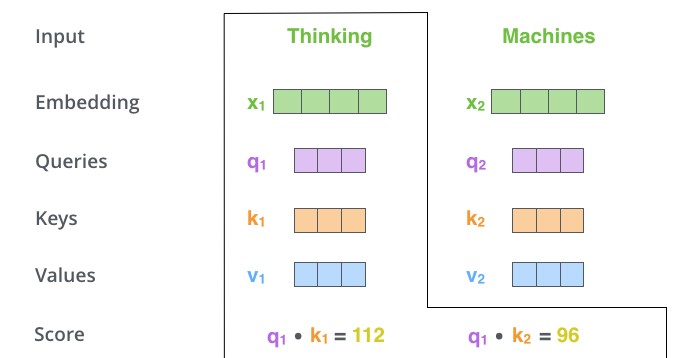
گام دوم در محاسبه self-attention محاسبه امتیاز است. فرض کنید ما self-attention را برای کلمه اول در این مثال محاسبه میکنیم ما باید به هر کلمه از جملهی ورودی در برابر این کلمه نمره دهیم. این امتیاز تعیین میکند که وقتی کلمهای را در یک موقعیت خاص رمزگذاری میکنیم روی سایر قسمتهای جمله ورودی باید تمرکز کنیم.
این امتیاز با حاصلضرب نقطهای بردار query با بردار key محاسبه میشود. بنابراین اگر self-attention را برای یک کلمه در موقعیت #1 پردازش کنیم، امتیاز دوم، ضرب نقطهای q1, k1 است. امتیاز دوم، ضرب نقطهای q1, k2 است.
گامهای سوم و چهارم آن است که امتیازها را بر 8 تقسیم کنیم. این منجر به داشتن گرادیانهای پایدارتر میشود. در اینجا مقادیر ممکن دیگری وجود دارند، سپس باید نتیجه را از طریق عملیات softmax عبور دهیم. لایهی softmax امتیازها را نرمال میکند بنابراین همهی آنها مثبت هستند و مجموع آنها 1 میشوند.
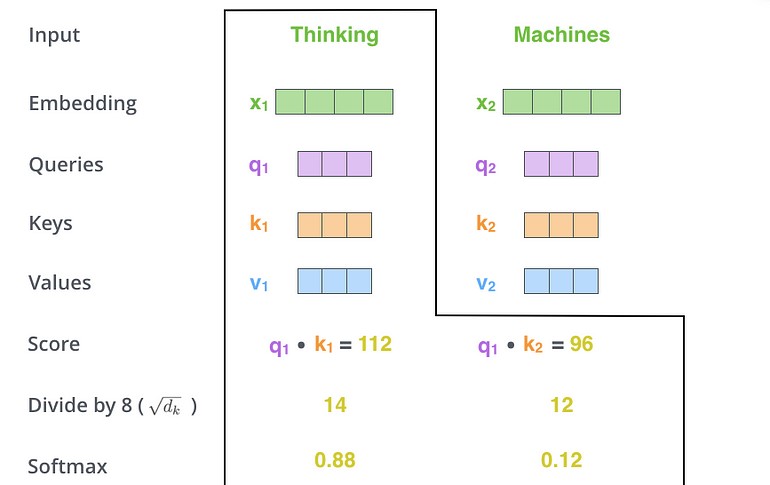
امتیاز بدست آمده از لایه softmax تعیین میکند که هر کلمه در این موقعیت چگونه بیان میشود. واضح است که کلمه در این موقعیت، بالاترین امتیاز softmax را خواهد داشت اما گاهی اوقات توجه به کلمه دیگری که به کلمه فعلی مربوط است، مفید است.
گام پنجم، ضرب هر بردار مقدار در امتیاز softmax است (برای آمادهسازی جمع بندی آنها). شهود این کار آن است که مقادیر کلمههایی که میخواهیم روی آنها تمرکز کنیم را دست نخورده نگاه داریم و کلمات نامربوط را حذف کنیم (مثلاً با ضرب آنها در اعداد کوچکی مانند 0.001).
گام ششم، جمع بردارهای ارزش وزندار است. این مرحله، خروجی لایهی self-attention را در هر موقعیت تولید میکند (برای کلمه اول).
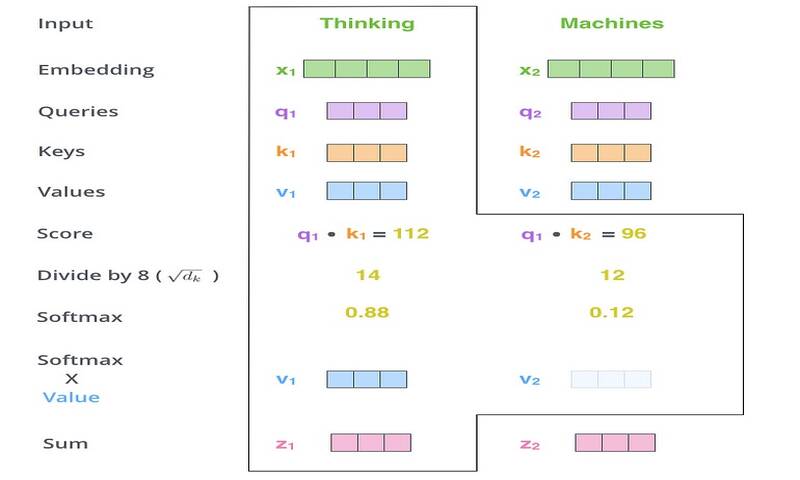
این لایه، محاسبهی self-attention است. بردار بدست آمده را میتوانیم به شبکه عصبی feed-forward ارسال کنیم. اما در پیادهسازی واقعی، این محاسبه به صورت ماتریسی برای پردازش سریعتر انجام میشود.
Multihead attention
ترنسفورمرها اساساً اینگونه کار میکنند. چند جزئیات دیگر وجود دارد که باعث میشود ترنسفورمرها بهتر کار کنند. برای مثال به جای اینکه ترنسفورمرها تنها در یک بعد به یکدیگر توجه کنند، از مفهوم multihead attention استفاده میکنند.
ایدهی اصلی آن است هر زمان که یک کلمه را ترجمه میکنید، ممکن است بر اساس نوع سوالی که از شما پرسیده شده است به هر کلمه توجه متفاوتی داشته باشید. تصاویر زیر نشاندهندهی این معنی هستند. برای مثال هر زمان که شما کلمه “kicked” را در جملهی “I kicked the ball”, ترجمه میکنید ممکن است بپرسید “Who kicked”. بسته به پاسخ، ترجمه کلمه به زبان دیگر میتواند تغییر کند. یا سوالات دیگری بپرسید مثلاً “Did What?”
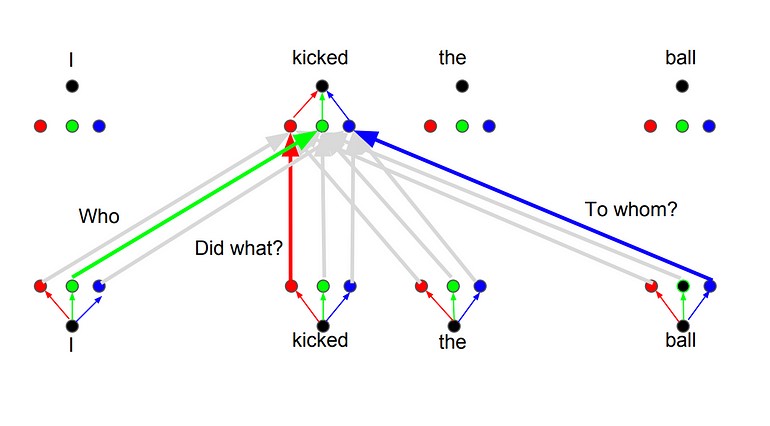
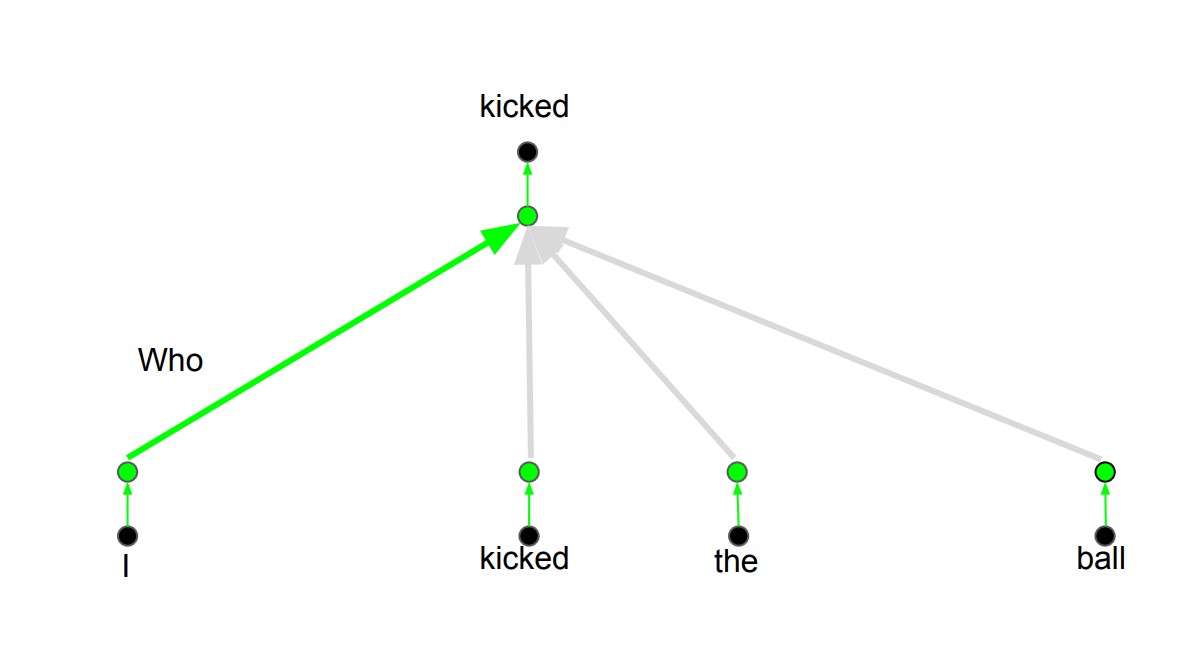
در این مقاله توضیح دادیم که ترنسفورمرها چطور کار میکنند و این روش را چطور میتوان برای انتقال توالی استفاده کرد.
دوره های مرتبط

خیلی ترجمه تحت الفظی بود.
عالییییی ممنون
ممنون از لطف شما