
تکنیکهای آموزش شبکه های عصبی بزرگ
- دسته:اخبار علمی
- هما کاشفی
ممکن است شبکههای عصبی عظیم، گزینهی مناسبی برای پروژهی شما باشند اما نگران روند آموزش آنها باشید. شبکههای عصبی بزرگ، مرکز اصلی پیشرفتهای اخیر در هوش مصنوعی هستند، اما آموزش این شبکهها چالش پژوهشی و مهندسی دشواری است که مستلزم سازماندهی دستهای از GPUهاست تا بتوانند یک محاسبه همزمان را انجام دهد. با افزایش سایز مدل، متخصصان یادگیری ماشین، انواع مختلفی از تکنیکها را توسعه دادهاند تا بتوانند روند آموزش مدل را در بسیاری از GPUها موازیسازی کنند. در نگاه اول، درک این تکنیکهای موازی سازی ممکن است دلهره آور به نظر برسد، اما تنها با در نظر گرفتن چند فرض در مورد ساختار محاسبات، تکنیکها واضحتر میشوند.
شکل زیر نشانگر چهار مدل روش موازیسازی روی یک مدل سه لایه است. هر رنگ نشانگر یک لایه است و خطوط نقطه چین، GPUهای مختلف را از هم جدا میکنند.
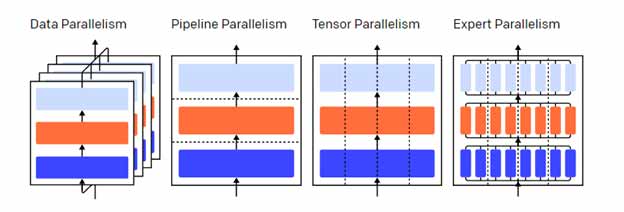
بدون موازی سازی
آموزش یک شبکه عصبی، فرآیندی تکراری است. در هر تکرار، یک pass forward روی لایههای شبکه انجام میدهیم تا خروجی را برای هر نمونهی آموزشی در هر بچ (Batch) از داده محاسبه کنیم. سپس محاسبات را به صورت عقبگرد در لایهها انجام میدهیم، با محاسبه گرادیان هر پارامتر، میخواهیم بدانیم که هر پارامتر چقدر روی خروجی نهایی اثر داشته است. گرادیان میانگین برای هر بچ، پارامترها و وضعیت بهینه سازی برای هر پارامتر به یک الگوریتم بهینه سازی مانند Adam دادهمیشود که پارامترهای تکرار بعدی و وضعیت بهینه سازی برای هر پارامتر را مشخص میکند. پس از آنکه آموزش در بچهای داده تکرار شد، مدل تکامل پیدا میکند به گونهای که خروجیهای بسیار دقیق (بسیار نزدیک به خروجی واقعی) تولید میکند.
تکنیکهای مختلف موازیسازی این فرآیند، آموزش را در ابعاد مختلف تقسیم میکنند؛ از جمله:
موازیسازی داده: زیرمجموعههای مختلف بچها را روی GPUهای مختلف اجرا کنید.
موازی سازی پایپ لاین: لایههای مختلف مدل را روی GPUهای مختلف اجرا کنید.
موازی سازی تنسور: ریاضیات مربوط به یک عملیات واحد را تجزیه کنید؛ مثلا ضرب ماتریسی در GPUها تقسیم شود.
ترکیب خبرهها: هر نمونه را تنها با کسری از هر لایه پردازش کنید.
(در این پست، فرض خواهیم کرد که شما از GPUها برای آموزش شبکههای عصبی خود استفاده میکنید، اما این ایدهها برای کسانی که از هر شتاب دهنده شبکه عصبی دیگر استفاده میکنند، کاربرد دارد).
موازی سازی پایپ لاین
در آموزش موازی پایپ لاین، تکههای متوالی مدل را بین GPUها تقسیم میکنیم. هر GPU تنها کسری از پارامترها را در خود جای میدهد و بنابراین همان مدل در هر GPU حافظه کمتری مصرف میکند.
تقسیم یک مدل بزرگ به تکههای لایههای متوالی ساده است. با این حال، بین ورودیها و خروجیهای لایهها، وابستگی متوالی وجود دارد، بنابراین یک پیاده سازی ساده میتواند منجر به میزان زیادی زمان بیکاری شود به گونهای که یک worker منتظر خروجیهای ماشین قبلی است تا از آن به عنوان ورودی استفاده کند. این زمانهای انتظار، «حباب» نامیده میشوند و زمانی که ماشینهای بیکار میتوانستند برای محاسبات انجام دهند را تلف میکنند.
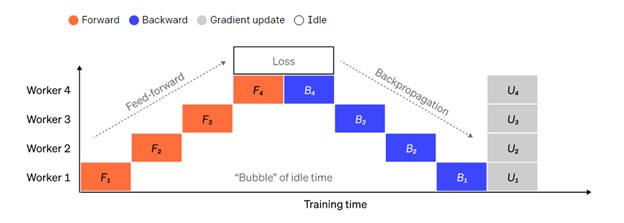
نمایی از روند موازی سازی پایپ لاین ساده که در آن مدل به شکل عمودی به 4 پارتیشن تقسیم شده است. Worker 1 پارامترهای مدل لایهی اول شبکه را دارد (نزدیکترین لایه به ورودی)، در حالیکه worker 4 پارامترهای مدل لایه چهارم شبکه را دارد (دورترین لایه به خروجی). “F”، “B” و “U” به ترتیب نشانگر عملیات Forward، Backward و Update هستند. پانویسها نشانگر آن هستند که عملیات روی کدام worker انجام میشود. در هر زمان و به دلیل وابستگی ترتیب، داده توسط یک worker پردازش میشود و به «حباب» بزرگی از زمان بیکاری منجر میشود.
میتوانیم از ایدههای موازی سازی دادهها استفاده کنیم تا هزینهی حباب را کاهش دهیم به گونهای که هر worker در هر بار تنها زیرمجموعهای از عناصر داده را پردازش میکند و به ما امکانی را میدهد تا به طور هوشمندانه، محاسبات جدید را با زمان انتظار همپوشانی کنیم. ایدهی اصلی آن است که هر بچ را به چند میکروبچ تقسیم کنیم؛ هر میکروبچ باید پردازش سریعتری داشته باشد و هر worker به محض اینکه میکروبچ بعدی در دسترس باشد، شروع به کار روی آن میکند و در نتیجه اجرای پایپ لاین را تسریع میکند. با میکروبچهای کافی، در ابتدا و انتهای هر مرحله، میتوان از workerها در اکثر مواقع با حداقل حباب استفاده کرد. میانگین گرادیانهای هر میکروبچ محاسبه میشود و به روز رسانی پارامترها تنها زمانی انجام میشود که تمامی میکروبچها تکمیل شوند.
تعداد workerهایی که مدل روی آنها تقسیم میشود معمولاً به عنوان عمق پایپ لاین شناخته میشوند.
در طی Forward pass، Workerها تنها باید خروجی تکه لایههای خود را به worker بعدی ارسال کنند؛ در طی backward pass، تنها گرادیانهای مربوط به این فعالسازی را به worker قبلی ارسال میکنند. فضای طراحی بزرگی برای نحوهی زمانبندی این مسیرهای جلورو و عقبگرد وجود دارد و اینکه چطور گرادیانها را در میکروبچها جمعآوری کنیم.
GPipe هر worker را به طور متوالی در مسیر جلورو و عقبگرد به کار میگیرد و سپس در انتها، گرادیانها را از چندین میکروبچ به طور همزمان جمع میکند. PipeDream در عوض هر worker را به گونهای برنامه ریزی میکند تا به طور متناوب مسیرهای جلورو و عقبگرد را طی کند.
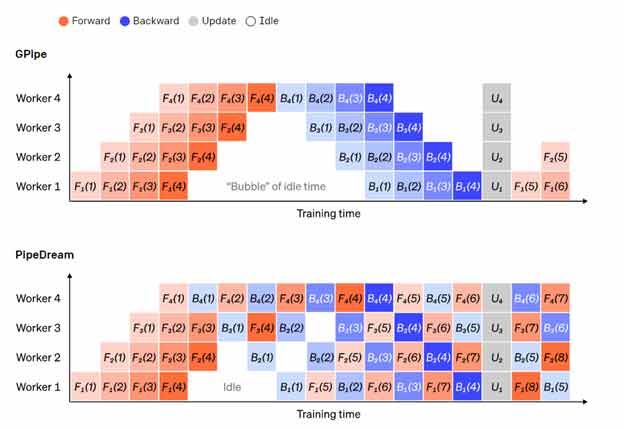
مقایسه طرحهای پایپ لاین GPipe و PipeDream با استفاده از 4 میکروبچ در هر بچ. میکروبچهای 1 تا 8 مربوط به دو بچ دادهی متوالی هستند. در تصویر «اعداد» نشانگر آن هستند که روی کدام میکروبچ، یک عملیات انجام شده است و زیرنویس نشانگر شناسه worker است. توچه داشته باشید که با انجام محاسباتی با پارامترهای مانده، PipeDream موثرتر میشود.
موازی سازی تنسور
موازی سازی تنسور، یک مدل را «به صورت عمودی» تقسیم میکند. همچنین میتوان «به صورت افقی»، عملیات خاصی را در یک لایه تقسیم کرد که معمولاً آموزش موازی تنسور نامیده میشود. برای بسیاری از مدلهای مدرن (مانند Transformer)، گلوگاه محاسباتی، ضرب یک ماتریس فعالسازی با یک ماتریس وزن بزرگ است. ضرب ماتریس را میتوان به صورت ضرب نقطهای بین جفت سطر و ستون در نظر گرفت: میتوان ضربهای نقطهای مستقل روی GPUهای مختلف محاسبه کرد، یا بخشهایی از هر ضرب نقطهای را روی GPUهای مختلف محاسبه کرد و نتایج را با هم جمع کرد. در هر یک از این استراتژیها، میتوانیم ماتریس وزن را به «shard»های با اندازه یکسان تقسیم کنیم و هر shard را روی GPU متفاوتی میزبانی کنیم و از آن shard برای محاسبه بخش مربوط به ضرب ماتریس کل استفاده کنیم قبل از اینکه نتایج را با هم ترکیب کنیم.
یک مثال Megatron-LM است که ضربهای ماتریسی را در لایههای MLP و self-attentionمربوط به Transformer موازی سازی میکند. PTD-P از تکنیکهای موازی سازی تنسور، داده و پایپ لاین استفاده میکند؛ زمانبندی پایپ لاین آن، چندین لایه غیرمتوالی را به هر دستگاه اختصاص میدهد تا با هزینه ارتباطات شبکه بیشتر، سربار حباب را کاهش دهد.
گاهی اوقات میتوان ورودی شبکه را در یک بعد موازی سازی کرد به این شکل که درجهی بالایی از محاسبات موازی نسبت به ارتباطات متقابل صورت گیرد. موازی سازی توالی یکی از این ایدههاست که در آن یک دنباله ورودی به چندین نمونه فرعی تقسیم میشود و با فراهم آوردن امکانی که محاسبات با نمونههای ریزدانهتری (granularly sized) انجام شوند، حافظه اوج را کاهش میدهد.
ترکیبی از خبرهها (MoE)
با رویکرد ترکیب خبرهها (MoE)، تنها کسری از شبکه برای محاسبه خروجی هر ورودی استفاده میشود. یکی از رویکردهای نمونه، داشتن مجموعهای از وزنهاست و شبکه میتواند انتخاب کند که کدام مجموعه را استفاده کند و برای این منظور از مکانیزیم گیت بندی در زمان استنتاج استفاده میکند. این روند بدون اینکه هزینهی محاسباتی را افزایش دهد، وجود پارامترهای بیشتری را ممکن میسازد. هر مجموعه از وزنها «خبره» نامیده میشود به این امید که شبکه یاد خواهد گرفت محاسبات و مهارتهای تخصصی را به هر خبره اختصاص دهد. خبره های مختلف را میتوان روی GPUهای مختلف میزبانی کرد و راهی برای افزایش تعداد GPUهای مورد استفاده برای یک مدل ارائه داد.
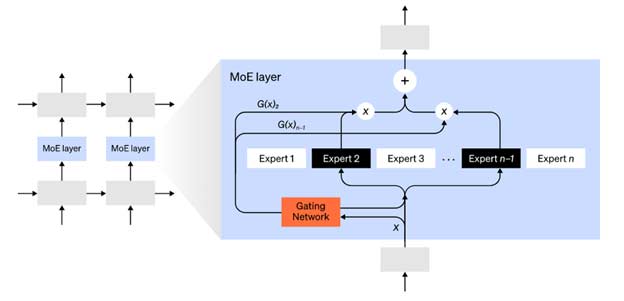
شماتیک لایهی ترکیبی از خبرهها (MoE). تنها 2 خبره از n خبره توسط شبکه گیت انتخاب میشوند.
Gshard یک MoE Transformer را تا 600 میلیارد پارامتر مقیاس بندی میکند با طراحی که در آن تنها لایههای MoE در چندین دستگاه TPU تقسیم میشوند و لایههای دیگر به طور کامل کپی میشوند.
سایر طرحهای ذخیره سازی حافظه
استراتژیهای محاسباتی دیگری نیز وجود دارند که آموزش شبکههای عصبی بزرگ را قابل تحملتر میکنند. برای مثال:
برای محاسبه گرادیان، شما باید فعالسازیهای اصلی شبکه را ذخیره کرده باشید، که باعث میشود RAM زیادی مصرف شود. Checkpointing تنها زیرمجموعهای از فعالسازیها را ذخیره میکند و فعالسازیهای میانی را تنها در طی backward pass محاسبه میکند. این امر باعث میشود در حافظه صرفه جویی شود.
Mixed Precision Training به معنی آموزش مدلها با اعداد با دقت کمتر است (معمولاً FP16). شتاب دهندههای مدرن میتوانند با اعداد با دقت کمتر به FLOP بالاتر برسند و همچنین میتوانید در RAM دستگاه صرفه جویی کنید. اگر تکنیک به درستی استفاده شود، تقریباً میتوان گفت مدل هیچ دقتی را از دست نمیدهد.
Offloading عبارت است از بارگذاری موقت دادههای استفاده نشده روی CPU یا بین دستگاههای مختلف، و اینکه بتوان در صورت نیاز آنها را دوباره بازخوانی کرد. پیاده سازیهای ساده، سرعت آموزش را به شدت کاهش میدهند اما پیادهسازیهای پیچیده، داده را از قبل واکشی میکنند و بنابراین دستگاه هرگز منتظر نمیماند. یکی از پیادهسازیهای این ایده ZeRO است که پارامترها، گرادیانها و وضعیتهای بهینه ساز را در تمام سخت افزارهای موجود تقسیم میکند و در صورت نیاز آنها را عملی میکند.
همچنین میتوان از فشرده سازی برای ذخیره سازی نتایج میانی در شبکه استفاده کرد. برای مثال، Gist فعالسازیهایی که برای backward pass هستند را ذخیره میکند؛ DALL.E قبل از همگام سازی گرادیانها، آنها را فشرده میکند.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دیدگاه ها