کار با دادههای تنک (Sparse Data)
- دسته:اخبار علمی
- هما کاشفی
دادهی تنک یا Sparse Data دادهای است که تعداد زیادی مقادیر صفر دارد. دادهی تنک را نباید با دادهی از دست رفته یا missing data اشتباه گرفت زیرا دادهی تنک مقادیر خالی یا صفر را نشان میدهد در حالیکه دادهی از دست رفته به این معنی است که برخی از مقادیر از دست رفته یا گم شدهاند و مقادیر آنها مشخص نیست و معمولاً این مقادیر از دست رفته را با null نشان میدهند.
دیتاستهای تنک که حاوی تعداد زیادی مقادیر صفر هستند ممکن است مشکلاتی چون بیش برازش در مدلهای یادگیری ماشین ایجاد کنند. به همین دلیل است که پرداختن به دادههای تنک یکی از پیچیدهترین فرآیندها در یادگیری ماشین است.
اغلب اوقات، تنک بودن دادهها مشکلاتی در یادگیری ماشین ایجاد میکند که باید به درستی مدیریت شود. با این حال گاهی اوقات این ویژگی تنک بودن در دیتاستها خوب است زیرا ممکن است حافظهی شبکههای معمولی را کاهش دهد و زمان آموزش شبکههای در حال رشد یادگیری عمیق را کاهش میدهد.
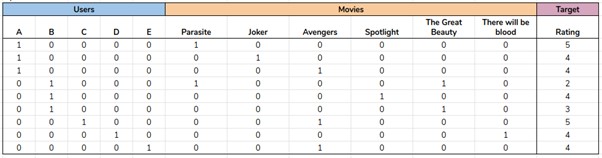
در تصویر فوق میتوانیم ببینیم که دیتاستی با مقادیر زیادی صفر داریم به این معنی است که دیتاست تنک است. اکثر اوقات هنگامی که با one-hot encoder کار میکنیم این نوع تنک بودن مشاهده میشود که علت هم اصول کاری one-hot encoder است.
نیاز به مدیریت دادههای تنک
دادههای تنک، مشکلات زیادی در هنگام آموزش مدلهای یادگیری ماشین ایجاد میکنند. به دلیل مشکلات مربوط باید به درستی مدیریت شوند.
از مشکلات رایج داده ی تنک به صورت زیر است:
1-بیش برازش
اگر تعداد زیادی ویژگی در دادهی آموزش وجود داشته باشد، سپس هنگام آموزش مدل شرایطی پیش میآید که هر گام در دادهی آموزش به دقت بالاتری منجر میشود و عملکرد دیتای تست کمتر میشود.
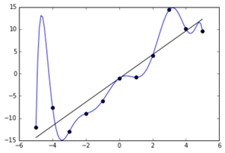
در تصویر فوق میتوانیم ببینیم که مدل دچار بیش برازش روی دادهی آموزش شده است به این معنی است که سعی میکند روند دادهی آموزشی را تقلید کند. در نهایت چنین شرایطی باعث کاهش عملکرد و دقت مدل روی دادهی تست و یا دادهی ناشناس میشود.
2-اجتناب از حذف دادههای مهم
برخی از الگوریتمهای یادگیری ماشین به این صورت هستند که اهمیت دادههای تنک را نادیده میگیرند و تنها روی دادهی متراکم آموزش داده میشوند و روی آن فیت میشوند. این مدلها هیچ اطلاعاتی از دیتاستهای تنک دریافت نمیکنند.
دادههای تنک دارای قدرت آموزش و اطلاعات مفید هستند که برخی از الگوریتمها این قدرت را نادیده میگیرند. بنابراین همیشه کار با دادههای تنک ساده نیست.
3-پیچیدگی مکانی
اگر دیتاست یک ویژگی تنک داشته باشد؛ فضای بیشتری نسبت به ذخیره سازی نسبت به دادهی متراکم دارد؛ از این رو، پیچیدگی مکانی افزایش خواهد یافت. به این دلیل، برای کار با این داده به قدرت محاسباتی بالاتری نیاز است.
4-پیچیدگی زمانی
اگر دیتاست تنک باشد نسبت به دادهی متراکم، آموزش مدل به زمان بیشتری نیاز خواهد داشت.
5-تغییر در رفتار الگوریتمها
برخی از الگوریتمها ممکن است روی دادههای تنک خوب عمل نکند. رگرسیون لجستیک یکی از الگوریتمهایی است که اگر روی دادهی تنک آموزش ببیند، رفتار مناسبی را نشان نمیدهد.
راههایی برای کار با دیتاستهای تنک
راههای زیادی برای کار با دیتاستهای تنک وجود دارد.
1-تبدیل ویژگی از فضای متراکم به فضای تنک
در هنگام آموزش یک مدل یادگیری ماشین همیشه خوب است که ویژگیهای متراکم داشته باشیم. اگر دیتاست دارای دادههای تنک باشد، رویکرد بهتر آن است که آن را به ویژگیهای متراکم تبدیل کنیم.
روشهای مختلفی وجود دارند که میتوانیم ویژگیها را متراکم کنیم:
1-استفاده از روش PCA
PCA یک روش کاهش ابعاد است که برای کاهش ابعاد دیتاست و انتخاب مهمترین ویژگیها در خروجی استفاده میشود.
در مثال زیر پیادهسازی PCA روی دیتاست نشان داده شده است
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(df)
pca_df = pd.DataFrame(data = principalComponents
, columns = [‘principal component 1’, ‘principal component 2’])
df = pd.concat([pca_df, df[[‘label’]]], axis = 1)
2-هش بندی ویژگیها
روش Feature Hashing روشی است که برای دیتاستهای تنک استفاده میشود و در آن دیتاست به تعداد مطلوب خروجی تبدیل میشود.
from sklearn.feature_extraction import FeatureHasherh = FeatureHasher(n_features=10)p = [{‘dog’: 1, ‘cat’:2, ‘elephant’:4},{‘dog’: 2, ‘run’: 5}]f = h.transform(p)f.toarray()
3-حذف ویژگیها از مدل
حذف ویژگیها از مدل یکی از سادهترین و سریعترین روشها برای کار با دیتاستهای تنک است. این روش شامل حذف ویژگیهایی از دیتاست هستند که برای آموزش مدل، مهم نیستند.
با این حال، لازم به ذکر است که گاهی اوقات دیتاستهای تنک میتوانند اطلاعات مفید و مهمی داشته باشند که نباید از مدل حذف شوند و میتوانند به عملکرد و دقت بالاتر مدل منجر شوند.
حذف کامل ستونی که دادهی تنک دارد:
import pandas as pddf = pd.drop([‘SparseColumnName’],axis=1)
3-استفاده از روشهایی که تحت تأثیر دیتاستهای تنک قرار نمیگیرند
برخی از مدلهای یادگیری ماشین نسبت به دیتاستهای تنک تأثیرناپذیرند و رفتار این مدلها تحت تأثیر دیتاستهای تنک قرار نمیگیرد. این رویکرد را میتوان مورد استفاده قرار داد و از این الگوریتمها استفاده کرد.
برای مثال، الگوریتم نرمال K means تحت تأثیر دیتاستهای تنک قرار میگیرد و بد عمل میکند و به دقت پایینتری منجر میشود. الگوریتم K means وزن دار آنتروپی تحت تأثیر دادهی تنک قرار نمیگیرد و نتایج معقولی به دست نیدهد. بنابراین هنگام کار با دیتاستهای تنک میتوان از الگوریتم entropy-weighted k means استفاده کرد.
نتیجهگیری
دادهی تنک در یادگیری ماشین یک مشکل گسترده است به خصوص هنگام کار با one hot encoding. به دلیل مشکلات ناشی از دادههای پراکنده (مانند بیش برازش، عملکرد پایین مدلها) مدیریت این نوع دادهها توصیه میشود تا بتوان مدلهای بهتری ساخت و به عملکرد بالاتری در مدلهای یادگیری ماشین دست یافت.
در نهایت:
1-دادههای تنک با دادههای از دست رفته متفاوت هستند. این داده فرمی از داده است که حاوی تعداد زیادی مقادیر صفر است.
2-دادههای تنک باید به درستی مدیریت شوند تا از مشکلاتی مانند پیچیدگی زمانی و مکانی، عملکرد پایین مدل و بیش برازش و غیره جلوگیری شود.
3-کاهش ابعاد، تبدیل ویژگیهای تنک به ویژگیهای متراکم و استفاده از الگوریتمهایی مانند entropy-weighted K means که تحت تأثیر تنک بودن دادهها قرار نمیگیرند میتوانند به عنوان یک راه حل در نظر گرفته شوند.
دوره های مرتبط

پردازش سیگنال مغزی با کتابخانه MNE پایتون

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
دیدگاه ها