شبکه عصبی Resnet
- دسته:اخبار علمی
- هما کاشفی
در طی چند سال اخیر، با معرفی شبکههای عصبی کانولوشنی عمیق، بسیاری از مسائل حوزهی طبقه بندی تصویر و تشخیص تصویر با دقت بالا حل شدهاند. بعضی از مسائل مربوط پیچیدهتر بودند و محققان با انجام آزمایشات مختلف به این نتیجه رسیدند که با توسعه شبکههای عصبی عمیقتر، عملکرد مدلها به شدت بهبود مییافت. عمیقتر شدن شبکه به معنای افزودن لایههای بیشتر است. اما این عمیقتر شدن شبکه و افزایش شبکه را تا کجا میتوان ادامه داد؟ شبکههای Resnet با معماری جدید در اینجا به کمک میآیند.
Resnet چیست؟
شبکه Resnet که مخفف Residual Network (شبکه باقی مانده) است نوع خاصی از شبکه عصبی است که در سال 2015 توسط Kaiming He, Xiangyu Zhang و Shaoqing Ren و Jian Sun در مقالهای با عنوان «یادگیری باقیمانده عمیق برای تشخیص تصویر» معرفی شد. مدلهای Resnet به موفقیتهای چشمگیری دست یافتند. از جملهی این موفقیتها، کسب مقام اول در رقابت ILSVRC 2015 Classification بود. نوآوری اصلی این شبکه آن بود که برای حل مشکل زیاد شدن تعداد لایهها، بلوک جدیدی به نام بلوک باقیمانده (Residual Block) معرفی شد که در ادامه توضیح داده خواهد شد.
نیاز به ResNet
در اکثر مواقع برای حل یک مسئله پیچیده، چند لایه به معماری شبکه عصبی خود اضافه میکنیم و به اصطلاح شبکه خود را عمیقتر میکنیم که در نهایت دقت و عملکرد شبکه را افزایش میدهد. منطق اصلی برای اضافه کردن لایههای بیشتر آن است که با اضافه شدن این لایهها، شبکه به تدریج ویژگیهای پیچیدهتری را یاد میگیرد. برای مثال در مسئلهی تشخیص تصاویر، لایهی اول ممکن است لبههای تصویر را تشخیص دهد، لایهی دوم زمینه را یاد بگیرد و به طور مشابه لایهی سوم میتواند کل ساختار شی یا چهره را یاد بگیرد. محققان با انجام آزمایشهای متعدد متوجه شدهاند که در مدل شبکه عصبی کانولوشنی، آستانهای برای افزایش عمق وجود دارد. در ادامه نموداری آمده است که نشان میدهد درصد خطا برای دادههای آموزش و آزمایش به ترتیب برای شبکههای 20 لایه و 56 لایه چقدر است.
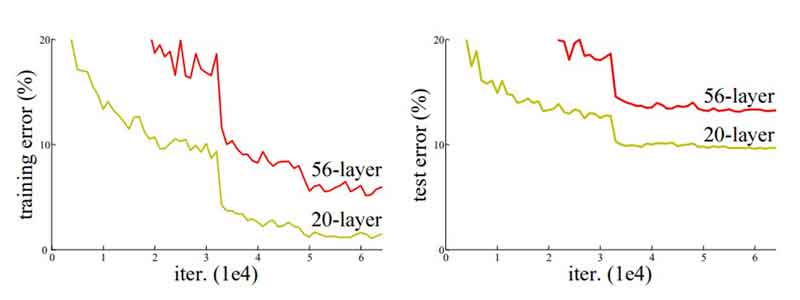
همانطور که در شکل فوق مشخص است، درصد خطا برای هر دو دادهی آزمایش و آموزش برای یک معماری 56 لایه بیشتر از یک شبکه 20 لایه است. این نشان میدهد که اضافه کردن لایههای بیشتر در شبکه همیشه به معنای بهتر شدن عملکرد آن نیست بلکه ممکن است عملکرد آن را تخریب کند. علت اینکه با عمیقتر شدن شبکه، عملکرد آن ضعیف میشود را میتوان در عوامل متعددی جستجو کرد مانند تابع بهینه سازی، وزن دهی اولیه شبکه و مهمتر از همه مسئلهی gradient vanishing.
بلوک Residual
مشکلات مربوط به آموزش شبکههای بسیار عمیق با معرفی شبکههای ResNet تا حدودی حل شد. این معماری Resnet از بلوکهای Residual تشکیل میشد که در شکل زیر مشاهده میکنید.
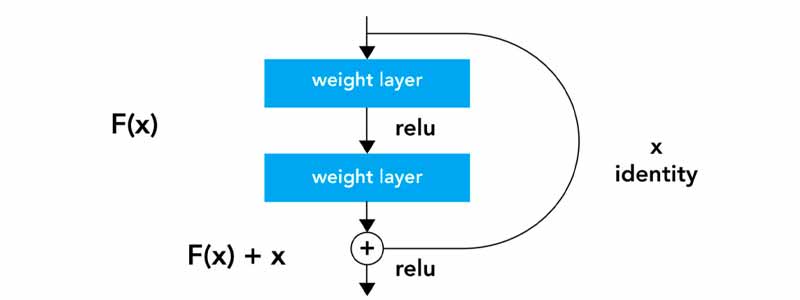
با مشاهده شکل فوق، اولین تفاوتی که متوجه میشویم آن است که یک اتصال مستقیم وجود دارد که لایهی میانی (در معماری بزرگتر، لایههای میانی) را رد کرده است. این اتصال “Skip Connection” نام دارد و عنصر اصلی بلوکهای باقیمانده است. به دلیل وجود این اتصال، خروجی لایه مشابه شبکههای دیگر نیست. ورودی “x” در وزن لایهها ضرب شده و همچنین مقدار بایاس به آن اضافه میشود. سپس این عبارت از تابع فعالسازی F(x) عبور میکند و در نهایت خروجی را داریم که با H(x) نمایش میدهیم. و به صورت زیر تعریف میشود.
H(x)=f(x)+x
در شبکههای عصبی عادی، لایهها توزیع ورودی را یاد میگیرند اما در این بلوکهای Residual، شبکه توزیع خروجی-ورودی را یاد میگیرد و به همین دلیل به این بلوکها، بلوکهای باقیمانده گفته میشود.
شبکهی ResNet چطور مشکلات ناشی از عمیق شدن شبکه را حل میکند؟
همانطور که گفته شد در شبکهی ResNet، اتصالی به نام Skip Connection وجود دارد که مسئلهی Vanishing gradient را در شبکههای عصبی عمیق حل میکند و امکانی را فراهم میآورد که گرادیان از مسیرهای Shortcut عبور کند. همچنین با وجود این اتصالات، مدل میتواند تابع همانی را یاد بگیرد که تضمین میکند لایهی بالاتر حداقل به خوبی لایهی پایینتر عمل میکنند، نه بدتر از آن.
فرض کنید ما یک شبکهی کم عمق و یک شبکهی عمیق داریم که ورودی “x” را به خروجی “y” با استفاده از تابع H(x) نگاشت میکنند. هدف ما آن است که شبکه عمیق حداقل به خوبی شبکه کم عمق کار کند و عملکرد شبکه با زیاد شدن تعداد لایهها، پایین نیاید. یک راه برای دستیابی به این هدف آن است که لایههای اضافی در شبکه عمیق، تابع همانی را یاد بگیرند و بنابراین خروجی آنها برابر با ورودی آنها باشد و در نهایت با وجود لایههای اضافی، عملکرد مدل تخریب نشود.
برای آنکه شبکه، تابع همانی را یاد بگیرد، باید F(x)=0 باشد آنگاه رابطه به صورت زیر خواهد شد
H(x)=x
در بهترین حالت، لایههای اضافی شبکه عصبی عمیق میتوانند نگاشت ورودی “x” به خروجی ”y” را نسبت به شبکههای کم عمق خود بهتر تخمین بزنند و خطا را با حاشیهی قابل توجه و معناداری کاهش دهند. بنابراین انتظار داریم که شبکه ResNet به خوبی یا بهتر از شبکههای عصبی عمیق کار کند.
اگر علاقه مند به یادگیری تخصصی شبکه عصبی ResNetهستید پیشنهاد میکنیم که دوره جامع و پروژه محور شبکه عصبی کانولوشنی را بگذارنید. در این دوره تئوری و ساختار این شبکه کامل توضیح داده شده و سپس به صورت پروژه محور پیاده سازی شده است.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

مرسی ساده و قابل فهم👌
سلام! بلوک گلوگاه (Bottleneck) رو معرفی نکردید.