
کتابخانههای ضروری مکمل کار با پکیج MNE پایتون
- دسته:اخبار علمی
- هما کاشفی
به منظور کار با پکیج MNE پایتون، شناخت و یادگیری چند مورد از کتابخانههای پایتون ضروری است. این کتابخانه در خواندن دیتاستهایی مثل EEG، ذخیره سازی و جداسازی و تقسیم دیتاست به بخشهای آموزش و آزمایش و همچنین استفاده از تکنیکهای آموزش مدل مانند k-fold cross validation و … ضروری هستند. این کتابخانهها عبارتند از: numpy، pandas و matplotlib و scikit-learn.
در این مقاله به بررسی این کتابخانههای مهم پایتون و نقش آنها در کار با پکیج MNE میپردازیم.
MNE یک پکیج Open-source است که برای بررسی، تجسم سازی و تحلیل دادههای نوروفیزیولوژیکی انسان به کار میرود. در این پکیج به راحتی میتوان دادههای MEG, EEG, sEEG, ECoG و NIRS و … را مطالعه و تحلیل کرد. این پکیج توابع مختلفی را برای خواندن و پیش پردازش و … در اختیار کاربران قرار میدهد. اما به منظور کار با این پکیج و پیادهسازی پروژههای یادگیری ماشین و یادگیری عمیق مربوط به دادههایی مثل EEG با انواع مختلف نیاز است که چهار مورد از مهمترین کتابخانههای پایتون را نیز بدانیم. این کتابخانهها عبارتند از:
1-کتابخانه NumPy
NumPy یا Numerical Python یک کتابخانه پایتون Open source است که تقریباً در هر فیلد علوم و مهندسی استفاده میشود. این کتابخانه یک استاندارد جهانی برای کار با دادهی عددی در پایتون است. این کتابخانه هستهی اصلی اکوسیستمهای PyData و scientific Python است. کاربران NumPy هر فردی از کدنویسان مبتدی تا محققان باتجربه میتوانند باشند که پژوهشهای صنعتی و علمی جدید انجام میدهند. از NumPy API میتوان به طور گستردهای در Pandas, Scipy, Matplotlib, scikit-learn و scikit-image و سایر پکیجهای علمی و علوم دادهی پایتون استفاده کرد.
کتابخانه NumPy شامل آرایههای چند بعدی و ساختاردادههای ماتریسی است. این کتابخانه یک آبجکت ndarray که آرایهی n بعدی همگن است را در اختیار ما قرار میدهد. از Numpy میتوان استفاده کرد و انواع مختلف عملیات ریاضیاتی روی آرایهها انجام داد. این کتابخانه، ساختار دادههای قدرتمندی به پایتون اضافه میکند و انجام محاسبات موثر با آرایهها و ماتریسها را تضمین میکند.
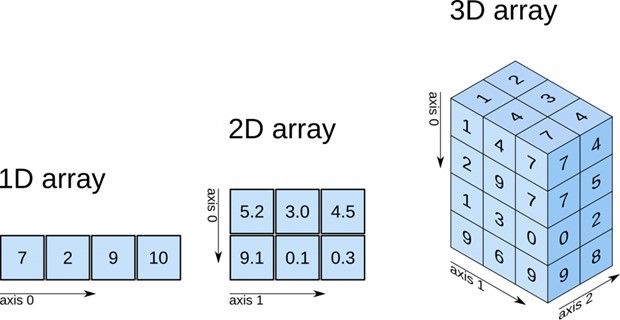
در شکل زیر نحوهی تعریف یک آرایهی یک بعدی و ساختار ذخیره سازی آن نشان داده شده است:

در شکل زیر، اندیس گذاری یک آرایه و ساختار آن در دادهها مشخص است:

در شکل زیر مثالی از اندیس گذاری در آرایه ی دو بعدی آمده است:
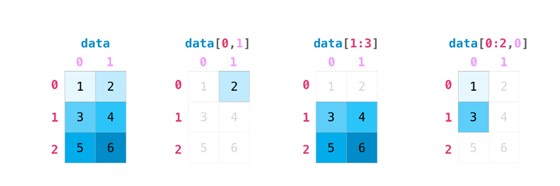
در شکل زیر عملیات روی ماتریسها در امتداد محور صفر (ستون) یا محور یک (سطر) آمده است:
از آنجاییکه گاهی اوقات نیاز است دیتای EEG داخل آرایههای Numpy ذخیره شود و عملیاتی روی آن انجام شود (برای مثال دادههای هر کلاس جدا شوند و یا برای هر دادهای برچسب تولید شود) نیاز است که برای کار با پکیج MNE پایتون، این کتابخانه را نیز بشناسیم.
2–Pandas
کتابخانه Pandas (مخفف Panel Data) یک کتابخانه نرم افزاری برای زبان برنامه نویسی پایتون برای تغییر و تحلیل داده است. به طور خاص، ساختار دادهها و عملیاتی برای جدولهای عددی و سریهای زمانی در اختیار ما قرار میدهد.
ساختار دادههای پایه در pandas به دو شکل هستند:
1-series: یک آرایهی برچسب دار یک بعدی که دادهای به هر نوع را ذخیره میکند: مانند اعداد صحیح، رشته، آبجکتهای پایتون
2-DataFrame: یک ساختار دادهی دو بعدی که دادههایی مانند آرایهی دو بعدی یا جدولی با سطر و ستون را ذخیره میکند.
برای مثال ما میتوانیم با استفاده ازیک دیکشنری که کلیدهای آن برچسبهای ستونها و مقادیر، مقادیر ستونهاست یک Dataframe بسازیم.
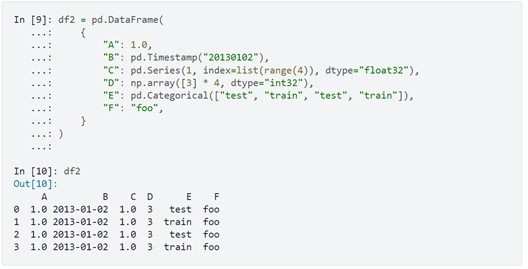
برخی از دیتاستهای EEG به فرمت .CSV هستند این دیتاست ها را میتوان به راحتی به Dataframeهای کتابخانهی Pandas تبدیل کرد و روی آنها کار کرد همچنین میتوان آرایههای Numpy را به دیتافریمهای Pandas تبدیل کرده و روی آنها کار کرد. بنابراین دانستن این کتابخانه، ضروری است.
3-کتابخانه Matplotlib
کتابخانهی Matplotlib یک کتابخانهی جامع برای ایجاد تجسمسازیهای ایستا، متحرک و تعاملی در پایتون است. با استفاده از این کتابخانه به راحتی میتوانید انواع نمودارهای خطی، نقطهای، میلهای، دایرهای و … را ایجاد کنید و خروجی مناسب از کار خود را نمایش دهید. ما برای نمایش بسیاری از خروجیهای پردازشهای خود در MNE به این کتابخانه نیاز داریم.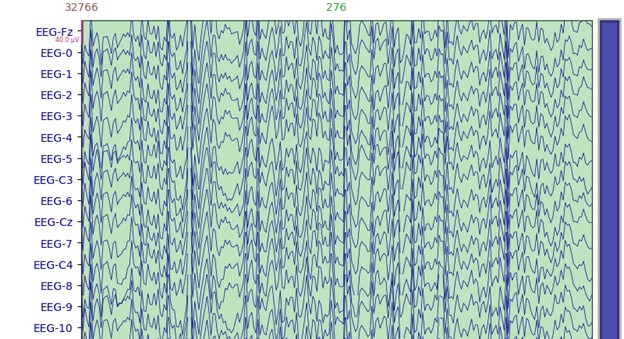
بسیاری از آبجکتهای پکیج MNE دارای متد plot هستند که این متدهای plot همگی بر پایهی کتابخانهی matplotlib هستند.
4-کتابخانه Scikit-learn
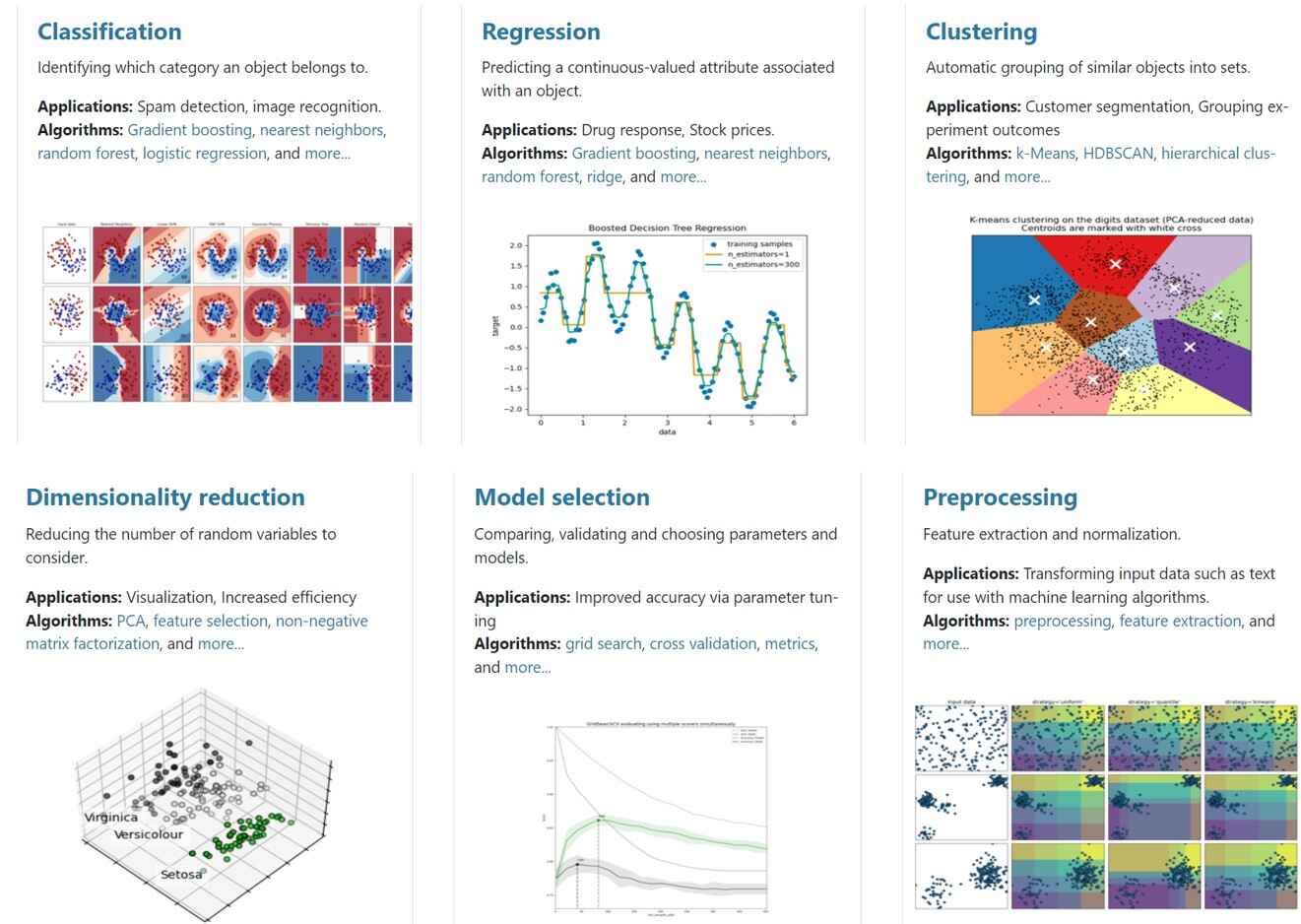
کتابخانه scikit-learn یک کتابخانهی جامع برای پیادهسازی الگوریتمهای یادگیری ماشین در پایتون است. این کتابخانه یک ابزار موثر و ساده برای تحلیل داده است و میتوان آن را به همراه کتابخانههای دیگر چون NumPy, Scipy, Matplotlib استفاده کرد. این کتابخانه برای حوزههای مختلف یادگیری ماشین چون Classification, Regression, Clustering, Dimensionality Reduction و Model selection و preprocessing کاربرد دارد.
دوره های مرتبط

دوره پردازش سیگنال قلبی ECG

پردازش سیگنال مغزی با کتابخانه MNE پایتون

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

برنامه نویسی شیء گرا در پایتون Python

کتابخانه NumPy و matplotlib در پایتون

اصول برنامه نویسی پایتون Python

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
دیدگاه ها