طبقه بند بیزین
طبقه بند بیزین یک روش آماری قوی هست که از تئوری بیزین برای دسته بندی الگوها استفاده میکند. تئوری بیزین یک روش آماری کمی هست که براساس حداقل کردن هزینههای تصمیم گیریهای مختلف کار میکند. در این مقاله میخواهیم به طور خلاصه تئوری طبقه بند بیزین را توضیح دهیم.
طبقه بند بیزین
طبقه بند بیزین براساس یک سری احتمالات کار میکند و از دانش اولیه و دانش اندازه گیری شده برای تصمیم گیری بهینه استفاده میکند.
صوت مسئله
برای درک بهتر بیایید یک مثال ساده بزنیم. فرض کنید میخواهید سیستمی طراحی کنید که بتواند ماهیهای سالمون و سیباس را دسته بندی کند. ماهیها با کمک یک نوار نقاله وارد میشوند و هرکدام که به گیت ورودی رسیدن دوربین از آن تصویر ثبت کرده و به کامپیوتر منتقل میکند. حال الگوریتم شما باید براساس تصویر ثبت شده نوع ماهی را تشخیص داده و در یکی از دو دسته قرار دهد.
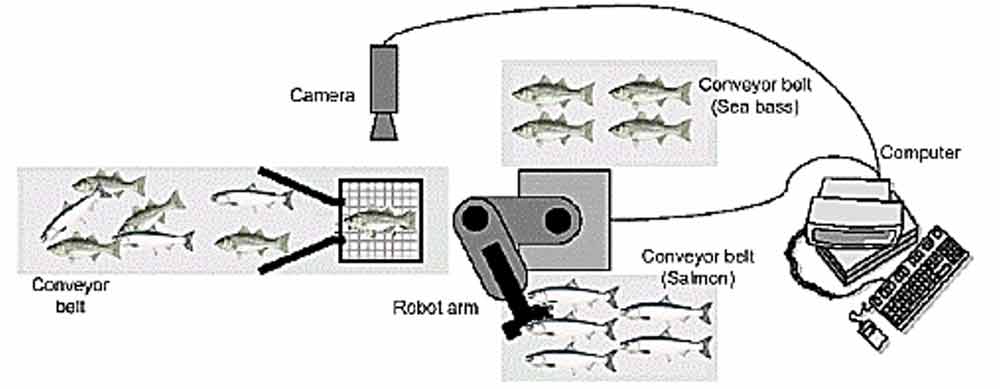
واقعیت این است که داده ها به صورت تصادفی وارد سیستم می شوند و ما نمیدانیم که کدام ماهی در هر لحظه وارد سیستم می شود! اگر ما این دانش را داشتیم و میدانستیم چه ماهی وارد سیستم می شود، در این صورت اصلا نیازی به داشتن طبقه بند نداشتیم! بحث اینه که ما نمیدونیم کدام ماهی قرار است وارد سیستم شود! برای همین قرار هست که براساس یک سری احتمالات تصمیم بگیریم.
اطلاعاتی که وارد سیستم می شود تصادفی هست ، به عبارت دیگر state و nature داده برای ما مشخص نیست و ما با یک داده تصادفی سرو کار داریم! اگر از دید تئوری بیز به این مسئله نگاه کنیم، تئوری بیز بیان میکند که هر داده یک توزیع آماری دارد، ما باید براساس آن مشخص کنیم که state of nature ورودی ها چی هست. یا به عبارتی داده به چه کلاسی تعلق دارد. طبقه بند بیزین براساس یک سری احتمالات کار میکند، هر داده ای که وارد سیستم می شود یک احتمال وقوعی به یکی از کلاس ها دارد. طبقه بند بیزین بر این اساس احتمال وقوع را تخمین میزند و با در نظر گرفتن حداقل هزینه تصمیمگیری میکند. طبقه بند بیزین تصمیم گیری (طبقه بندی) را براساس دانش اولیه و دانش اندازه گیری شده(دانسیته احتمال) تصمیم گیری میکند که در ادامه این دانش را توضیح میدهیم.
دانش اولیه و طراحی طبقه بند براساس دانش اولیه
دانش اولیه دانشی(اطلاعاتی) است که بدون اندازه گیری بدست میآید. برای درک بهتر این دانش برگردیم به مثال ماهی سالمون و سیباس. فرض کنید ماهیها از یک دریایی صید میشوند که یک صیاد بومی چندین سال است که در آنجا ماهی گیری می کند. و براساس تجربه چندساله متوجه شده است که 80 درصد ماهیهای این دریا سالمون و 20 درصدشون سیباس است. ما همان ابتدا این دانش رو بدون اندازه گیری بدست آورده ایم که در تصمیم گیری خیلی میتوانند کمک کننده و مفید باشند.
برای مثال فرض کنید میخواهیم سیستم ما فقط براساس این دانش اولیه تصمیم گیری کند. در اینصورت برای داشتن حداقل خطا بهتر است به صورت زیر تصیمم گیری کنیم:
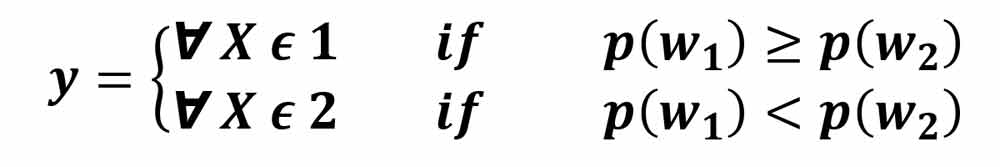
اگر بخواهیم فقط براساس دانش اولیه طبقه بند را طراحی کنیم، در این صورت طبقه بند بدون ثبت تصویر از ماهی ورودی تصمیم گیری خواهد کرد و همیشه هم یک نوع تصمیم میگیرید. برای مثال در این مسئله براساس دانش اولیه ای که صیاد بومی به ما داده است طبقه بند ما در خروجی فقط عدد یک را میدهد. یعنی بدون در نظر گرفتن اینکه چه ماهی وارد سیستم شده، همه رو سالمون تشخیص میدهد و اگر خطای طبقه بندی را محاسبه کنیم، 20 درصد خطای تصمیم گیری خواهد بود! همانطور که دیدیم دانش اولیه اطلاعات خیلی مفیدی ارائه می دهد و باعث می شود تصمیمی بگیریم که کمترین خطا را داشته باشد.
البته باید این را در نظر بگیریم که طراحی طبقه بند تنها براساس دانش اولیه زمانی خوب عمل میکند که احتمال یکی از کلاسها خیلی بیشتر از دومی باشد. این اطلاعات خوب هستند ولی کافی نیستند و ما باید از این اطلاعات کنار سایر اطلاعات استفاده کنیم تا به یک تصمیم گیری بهینه تری برسیم. هدف از مثال فقط برجسته کردن اهمیت دانش اولیه است.
تصمیم گیری براساس دانش اندازه گیری شده
مهمترین اطلاعات در مورد مسئله مورد نظر اطلاعات اندازه گیری شده است. ما میتوانیم از ماهیهایی که وارد میشوند یک سری پارامتر(ویژگی) استخراج کنیم و از آن برای تصمیم گیری استفاده کنیم. وقتی در مورد ویژگی صحبت میکنیم، منظور ویژگیهایی هست که در بین دو کلاس مقدار متفاوتی دارند. برای مثال ما شدت روشنایی سطح پوست ماهیها را به عنوان ویژگی استخراج کردیم. همانطور که در شکل هم مشخص هست شدت روشنایی ماهیهای دو گروه باهم رنج متفاوتی دارند. اگر هیستوگرام آماری ویژگی ماهیهای دو گروه را رسم کنیم میبینیم که ویژگی استخراج شده در هر گروه یک توزیع آماری متفاوتی دارد. ما اگر مرز بین دو توزیع را پیدا کنیم با دقت بالایی میتوانیم داده ها را دسته بندی کنیم.
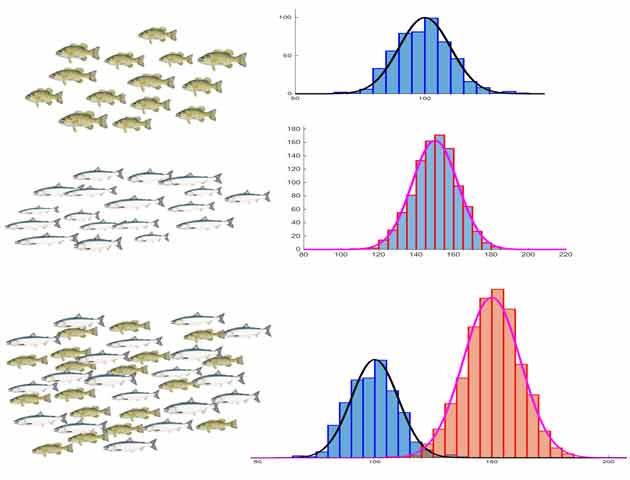
برای دسته بندی داده ها براساس اطلاعات اندازه گیری شده کافی هست که هر ماهی که وارد سیستم شد اول ویژگی یا ویژگی های مورد نظر را استخراج کنیم و سپس شباهت آنرا با توزیع تک تک کلاس ها بدست بیاوریم و سپس تصمیم گیری بکنیم. داده ورودی به کلاسی تعلق خواهد داشت که بیشترین شباهت(بیشترین درجه عضویت) را با توزیع آماری دادههای آن کلاس داشته باشد.
اگر فرض کنیم توزیع داده های هر کلاس نرمال است و باهم متفاوت هستند( یعنی ویژگی استخراج شده در دو گروه متفاوت باشد) و ما توزیع هر داده را تخمین بزنیم(با کمک ماکزیمم شباهت زده می شود)، میتوانیم دادههای ورودی را دسته بندی کنیم. کافی هست که درجه احتمال وقوع(درجه عضویت) داده ورودی را به هر کلاس محاسبه کنیم و سپس تصمیم گیری کنیم.
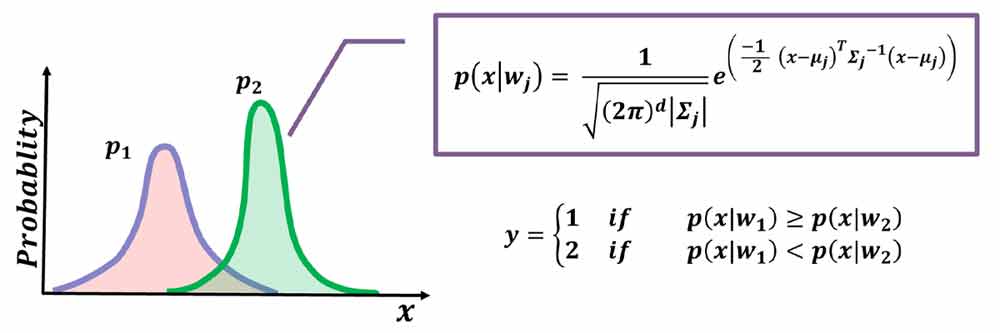
ما برای طراحی چنین سیستمی لازم است که یک پایگاه داده برای آموزش داشته باشیم و با کمک ماکزیمم شباهت توزیع هر کلاس را تخمین بزنیم و سپس با کمک آن طبق رابطه زیر درجه عضویت دادههای جدید را به هر کلاس محاسبه کنیم و دسته بندی کنیم. داده ورودی به کلاسی تعلق دارد که بیشترین شباهت(بیشترین درجه عضویت) را با توزیع آماری داده های آن کلاس داشته باشد.
طبقه بند بهینه چه نوع طبقه بندی است؟
همانطور که دیدیم هم اطلاعات اندازه گیری شده و هم دانش اولیه اطلاعات مفیدی ارائه می دهند و برای همین طبقه بهینه طبقه بندی است که بتواند از این دو اطلاعات به طور همزمان برای تصمیم گیری استفاده کند تا به یک تصمیم بهتری برسد.
نحوه تصمیم گیری توسط طبقه بند بیزین
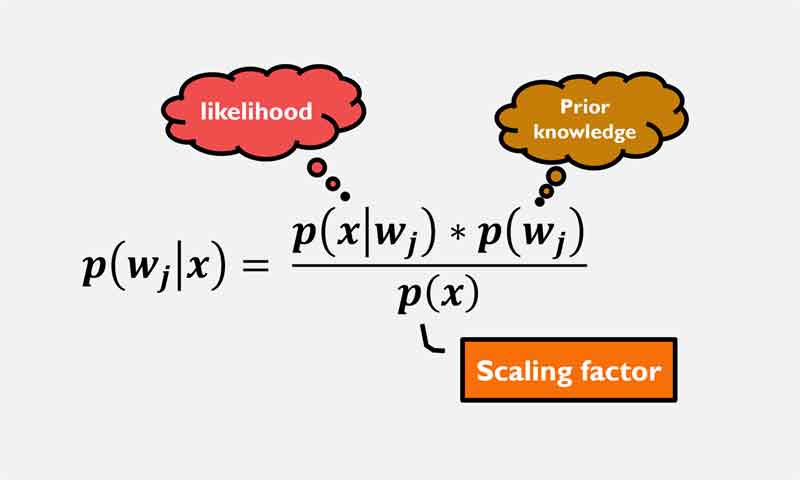
طبقه بند بیزین طبقه رابطه زیر دانش اولیه و دانش اندازه گیری شده را به احتمالات پسین تبدیل می کند و از آن برای تصمیم گیری استفاده میکند. به این صورت که داده جدید به کلاسی تعلق دارد که بیشترین احتمال پسین را نسبت به آن کلاس در مقایسه با سایر کلاسها داشته باشد.
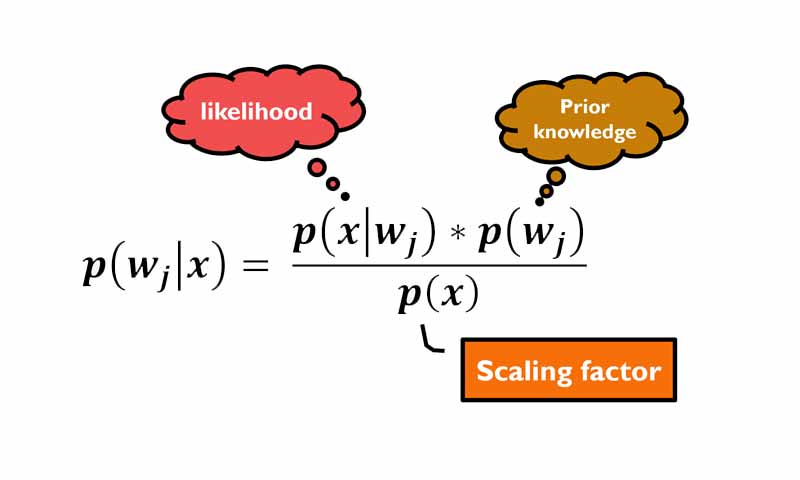
در این رابطه p(wj) دانش اولیه (احتمال وقوع هر کلاس که بدون اندازه گیری بدست می آید) است، p(x|wj) میزان شباهت داده ورودی به هر کلاس را مشخص می کند و p(x) یک scaling factor هست و باعث میشود احتمال پیسن یک مقداری بین صفر و یک شود و و هیچ نقشی در تصمیم گیری ندارد!
از آنجا که طبقه بند برای تصمیم گیری استفاده میکند یک طبقه بند بهینه است و اگر اطلاعات مورد نظر به طور دقیق بهش ارائه شود بهینه ترین طبقه بند برای تصمیم گیری می تواند باشد. یعنی دانش اولیه درست تعیین شود، و توزیع داده ها به طور دقیق تخمین زده شوند.
در فصل اول دوره جامع شناسایی الگو و یادگیری ماشین، تئوری و پیاده سازی طبقه بند بیزین به صورت مرحله به مرحله آموزش داده شده است و سپس در پروژه های عملی جهت دسته بندی داده ها استفاده شده است. به دوستانی که میخواهند به صورت تخصصی تر با طبقه بند بیزین و سایر الگوریتمهای یادگیری ماشین آشنا شوند پیشنهاد میکنیم دوره جامع شناسایی الگو و یادگیری ماشین را نگاه کنند. این دوره اولین دوره تخصصی در ایران هست که در 140 ساعت ویدیوی آموزشی به صورت تخصصی تمامی الگوریتمهای یادگیری ماشین را آموزش داده ایم. در این دوره در ابتدا تئوری الگوریتم ها طبق مراجع معتبر آموزش داده شده و سپس به صورت مرحله به مرحله پیاده سازی می شوند و در آخر هم در چندین پروژه عملی استفاده می شوند تا نحوه انجام پروژه های عملی با کمک الگوریتمهای یادگیری ماشین آشنا شوید.
دوره های مرتبط

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)
شناسایی الگو- کلاسبندهای پارامتری (فصل1و2)

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

شناسایی الگو(فصل ششم): تئوری و پیاده سازی الگوریتمهای کاهش بعد PCA و LDA

شناسایی الگو(فصل هفتم): انتخاب ویژگی (feature selection)

دیدگاه ها