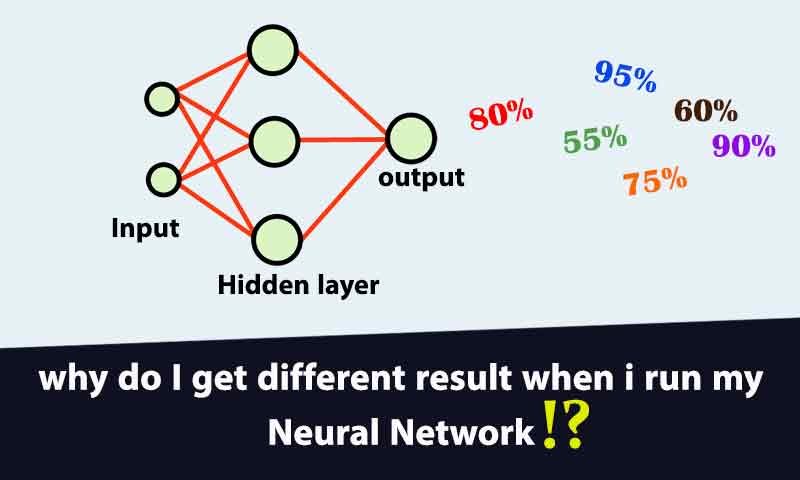
چرا هر موقع شبکه عصبی را اجرا میکنم جواب متفاوتی بدست می آید؟
روند یادگیری شبکه های عصبی مصنوعی به عوامل مختلفی وابسته است و عملکرد شبکه عصبی کاملا تحت تاثیر این عوامل قرار میگیرد. در پروژه ها اکثرا با این مشکل مواجه می شویم که شبکه عصبی در هر اجرا به یک عملکرد و دقت متفاوتی میرسد. در این مقاله توضیح میدهیم که چطور میتوان این مسئله را حل کرد تا شبکه عصبی به نتایج پایدار همگرا شود.
حتما برای شما هم پیش آماده که از یک شبکه عصبی در پروژه خودتون استفاده کرده اید و هر بار که اجرا کرده اید به یک نتیجه متفاوت رسیده اید. این برای یک پروژه اصلا نتیجه مناسب و قابل اعتماد نیست. شبکه عصبی ما باید نتایج پایدار و قابل اعتمادی بدهد تا بتوان در عمل از آن استفاده کرد. نتایجی پایدار هستند که در همه اجراها یکسان و یا حداقل نزدیک بهم باشند. نه اینکه در هر اجرا یک عدد عجیب غریب بدست بیاید. در این مقاله در ابتدا دلایل ناپایداری نتایج شبکه عصبی و سپس راه حل این مشکل را بررسی می کنیم.
دلیل اول: تصادفی بودن مقدار اولیه وزنهای سیناپسی
دانش شبکه های عصبی در وزنهای سیناپسی آنها نهفته است. و شبکه های عصبی در پروسه آموزش وزنهای سیناپسی بین نورونها را محاسبه می کنند. به عبارتی شبکه عصبی از روی داده آموزش دانش مورد نیاز را بدست آورده و در وزنهای سیناپسی ذخیره میکند.
معمولا در اکثر شبکه های عصبی در زمان شروع آموزش یک مقدار تصادفی به عنوان مقدار اولیه برای وزنهای سیناپسی تعریف می شود و سپس شبکه عصبی سعی در تنظیم مقدار مناسب وزنهای شبکه عصبی می کند. از آنجا که مقدار اولیه وزنهای سیناپسی به صورت تصادفی تعریف می شود، باعث میشود که در هر اجرا شبکه عصبی به یک نتیجه متفاوتی همگرا شود. چون مقدار اولیه وزنهای سیناپسی کاملا روند یادگیری شبکه های عصبی را تحت تاثیر قرار میدهند.

همین تصادفی بودن وزنهای سیناپسی دلیل اصلی عدم پایداری نتایج هست. چون هر بار که شبکه اجرا می شود، در پروسه آموزش مقدار اولیه تصادفی برای وزنهای سیناپسی تعیین میشود و در نتیجه روند یادگیری تحت تاثیر قرار میگیرد و مدل در پروسه تست یک مقدار متفاوتی در مقایسه با اجراهای دیگه بدست می آورد.
دلیل دوم: انتخاب تصادفی داده ها به صورت تصادفی
اهمیت پایگاه داده برای الگوریتمهای یادگیری ماشین: الگوریتمهای یادگیری ماشین کاملا به پایگاه داده وابسته هستند و میشه گفت که پایگاه داده برای الگوریتمهای یادگیری ماشین همانند سوخت برای ماشینها هست. پایگاه داده دانشی هست در مورد یک پدیده و الگوریتمهای یادگیری ماشین این دانش را در پروسه آموزش از روی پایگاه داده بدست می آورند. شبکه های عصبی هم که جزء الگوریتمهای یادگیری ماشین هستند و از این قضیه مثتثنی نیستند.
یکی از دلایل ناپایداری نتایج میتواند به خاطر این باشد که شما در پروسه آموزش پایگاه داده را به صورت تصادفی به مدل ارائه دهید. یعنی در هر اجرای شبکه عصبی، از مجموعه داده ها، یک تعداد به صورت کاملا تصادفی برای آموزش انتخاب شوند و در نتیجه در هر اجرا شبکه های عصبی به یک پایگاه داده متفاوتی آموزش ببینید و در نتیجه دانش متفاوتی بدست آورد و در نتیجه در اجراهای مختلف به یک نتیجه متفاوتی برسد!

در ادامه سه راهکار بیان میکنیم که هر کدام به نوبه خودشون در حل مشکل میتوانند موثر باشند(راه حل اول و آخر مهم هستند).
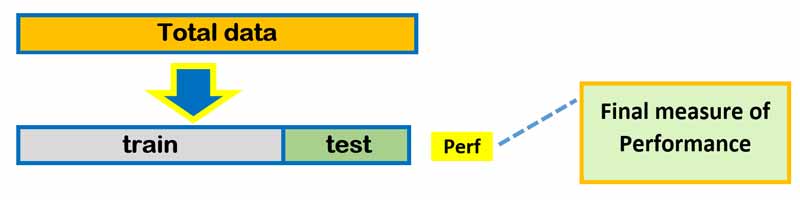
راه حل اول: انتخاب غیرتصادفی داده های آموزش
برای حل مشکل انتخاب داده ها راه چاره این است که داده ها را تصادفی انتخاب نکنیم. در همه اجرا ها ترتیب انتخاب داده ها غیرتصادفی باشد. برای مثال میتوانیم از روشی مثل k-fold cross validation استفاده کنیم. و یا اگر قرار هست مدل یک بار تست و ترین شود(روش the hold out method)، در این صورت بخش آموزش و تست به صورت غیرتصادفی انتخاب شود. برای مثال 70 درصد بخش اول داده ها برای آموزش و 30 درصد باقی برای تست استفاده شود.
راه حل دوم: تعیین مقدار ثابت برای وزنهای سیناپسی
از آنجا که مقدار اولیه برای وزنهای سیناپسی روند یادگیری شبکه عصبی را تحت تاثیر قرار می دهد، میتوانیم یک مقدار ثابت برای وزنهای سیناپسی در نظر بگیریم. مثلا مقدار همه را 0.1 در نظر بگیریم. با این راهکار میشه یجورایی مشکل عدم پایداری را حل کرد. البته اگر شبکه عصبی با این مقادیر اولیه بتونه آموزش ببینه!
در خیلی از موارد بهتر است که وزنهای اولیه تصادفی تعریف شوند تا شبکه امکان آموزش را داشته باشد. برای همین ممکنه تعیین مقادیر ثابت غیرتصادفی گزینه ی مناسبی برای حل مسئله نباشد. راهکارهای بعدی را نگاه کنید.
.
راه حل سوم: تعیین مقادیر تصافی با مقدار بسیار کم
مقدار اولیه وزنهای سیناپسی را تصادفی اما بسیار کوچک در نظر بگیریم. در این حالت امکان همگرایی به یک مقدار نزدیک بهم در همه اجرا ها وجود دارد. اگر مقدار اولیه وزنهای سیناپسی تصادفی کوچک باشد، در زمان آموزش، شبکه جهت رسیدن به وزنهای سیناپسی بهینه به مدت زمان آموزش زیادی نیاز خواهد داشت.
طبق تجربه متوجه شده ام که اگر مقدار تصادفی وزنهای سیناپسی را خیلی کوچک در نظر بگیریم بهتر است که نرخ یادگیری را هم کم درنظر بگیریم تا شبکه راحتتر بتواند وزنهای سیناپسی را بدست آورد. به همین خاطر اگر مقدار وزنهای سیناپسی را کوچک در نظر بگیریم بهتر است نرخ یادگیری را کم و از طرفی تعداد تکرارهای آموزش را بیشتر بکنیم تا شبکه فرصت کافی برای آموزش و بدست آوردن دانش کافی داشته باشد. اگر شانس بیاوریم و شبکه در مینیمم محلی گیر نکند در هر اجرا به عملکرد و دقت مشابهی خواهیم رسید.
این راه حل خیلی جاها موثر هست ولی ممکنه در برخی موارد نتواند مشکل را حل کند. راه حل چهارم میشه گفت بهترین راهکار برای حل مشکل هست که در ادامه توضیح میدهیم.
راه حل چهارم: تعیین مقدار ثابت ولی تصادفی در همه آموزشها(اجراها)
در ابتدای کار مقدار اولیه تصادفی برای وزنهای سیناپسی مشخص کنیم . سپس در همه اجراها از همین مقادیر تصادفی به عنوان مقدار اولیه برای وزنهای سیناپسی استفاده کنیم. در این صورت در همه اجراها شرایط اولیه یکسان هست و در نتیجه آن همیشه عملکرد و دقت شبکه در همه اجراها یکسان خواهد بود.
اگر علاقه مند به یادگیری تخصصی شبکه های عصبی مصنوعی هستید پیشنهاد میکنیم دوره جامع پیاده سازی شبکه های عصبی را نگاه کنید. این دوره اولین دوره تخصصی در ایران است که در آن تمامی شبکه های عصبی به طور مرحله مرحله پیاده سازی شده است. بدون اینکه از تولباکسی استفاده شود. مباحث تئوری این دوره طبق کتاب مرجع Simon & Haykins آموزش داده شده است.
دوره های مرتبط

پکیج کامل پیادهسازی گام به گام شبکههای عصبی
شبکه عصبی ELM (جلسه نهم)

شبکه عصبی پرسپترون چندلایه (جلسه چهارم)
پیاده سازی شبکه عصبی پرسپترون تک لایه (جلسه دوم)
دیدگاه ها