
نحوه ی انتخاب بهترین معیار ارزیابی برای مسائل طبقه بندی
- دسته:اخبار علمی
- نسرین رفیعی
برای اینکه یک مدل طبقه بندی را به خوبی ارزیابی کنیم باید به دقت در نظر بگیریم که کدام معیار ارزیابی مناسب ترین انتخاب است. این مقاله رایج ترین معیارهای ارزیابی که برای تسک های طبقه بندی استفاده می شود را پوشش می دهد و شامل مثال های مرتبطی است که اطلاعات لازم برای انتخاب مناسب ترین معیار از میان آن ها را در اختیار شما قرار می دهد.
راهنمای جامعی که رایج ترین معیارهای ارزیابی مورد استفاده برای طبقه بندی نظارتی و کاربرد آن ها در سناریوهای مختلف را مطرح می کند.
طبقه بندی
یک مساله طبقه بندی با پیش بینی کلاس (لیبل) یک نمونه مشاهده بر اساس ویژگیهای مربوط (ورودی) به آن مشخص می شود. انتخاب مناسب ترین معیار ارزیابی بستگی به این دارد که کاربر کدام جنبه ی عملکرد مدل را می خواهد بهینه کند.
فرض کنید یک مدل پیش بینی برای تشخیص یک بیماری مشخص داریم. اگر این مدل نتواند بیماری را تشخیص دهد، عواقب جدی مثل درمان با تاخیر و یا آسیب جانی بیمار را بر جای می گذارد. از طرف دیگر، اگر مدل به اشتباه یک فرد سالم را بیمار تشخیص دهد، باز هم خسارت های مالی را بر جای می گذارد چرا که فرد را ملزم به انجام تست و درمان های غیر ضروری می کند.
در نهایت، تصمیم بر سر اینکه کدام خطا باید مینیمم شود بستگی به مورد خاص استفاده و هزینه های مربوط به آن دارد. در ادامه برخی از رایج ترین معیارهای مورد استفاده برای روشن شدن موضوع را مطرح می کنیم.
پارامترهای ارزیابی
معیار ارزیابی صحت (Accuracy)
زمانی که کلاس ها در مجموعه داده متعادل است یعنی به تعداد برابر از نمونه ها در هر کلاس وجود دارد، از صحت می توان به عنوان یک معیار ساده و شهودی برای ارزیابی عملکرد مدل استفاده کرد. به بیان ساده، صحت درصد پیش بینی های صحیح مدل را اندازه می گیرد.
برای تشریح این موضوع، به جدول زیر نگاه کنید که کلاس داده های واقعی و کلاس داده های پیش بینی شده را نشان می دهد.

ستون های سبز، پیش بینی های صحیح را نشان می دهد. در این مثال، در کل 10 نمونه داریم که 6 تای آن ها به درستی(رنگ سبز) پیش بینی شده اند. بنابراین صحت ما مانند زیر محاسبه می شود:

برای اینکه درک بهتری از رابطه ی بالا داشته باشیم همین کافی است که بدانیم “پیش بینی های صحیح” جمع مثبت های صحیح و منفی های صحیح هستند.
- یک مثبت صحیح(TP) زمانی اتفاق می افتد که مدل، کلاس صحیح را به درستی پیش بینی کند.
- یک منفی صحیح (TN) زمانی اتفاق می افتد که مدل، کلاس منفی را به درستی پیش بینی کند.
در مثال ما، یک مثبت صحیح، خروجی است که هم کلاس داده ی واقعی و هم کلاس داده ی پیش بینی شده 1 باشد.
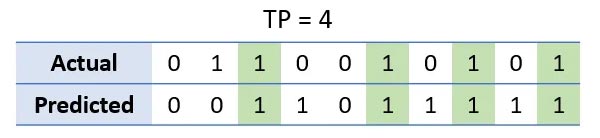
ستون های به رنگ سبز، مثبت صحیح را نشان می دهند. به همین ترتیب، یک منفی صحیح زمانی اتفاق می افتد که هم کلاس داده ی واقعی و هم کلاس داده ی پیش بینی شده، 0 باشد.
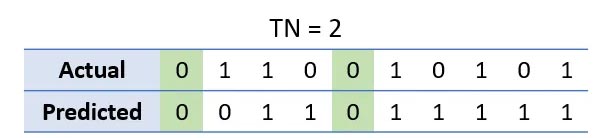
ستون های به رنگ سبز، منفی صحیح را نشان می دهند. بنابراین، می توان متناسب با این اصطلاحات فرمول صحت را به شکل زیر نوشت:

مثال: تشخیص چهره. برای تشخیص حضور یا عدم حضور یک چهره در تصویر، صحت یک معیار مناسب به عنوان هزینه مثبت غلط (شناسایی یک غیر چهره به عنوان یک چهره ) یا یک منفی غلط (شکست در شناسایی یک چهره) است که صحت این دو تقریبا برابراست. نکته: توزیع برچسب های کلاس در مجموعه داده باید متعادل باشد تا صحت به عنوان یک معیار مناسب انتخاب شود.
معیار ارزیابی دقت (Precision)
معیار دقت برای اندازه گیری نسبت پیش بینی های صحیح مثبت است. به عبارت دیگر دقت، معیاری از توانایی مدل برای شناسایی نمونه های مثبت صحیح را ارائه می کند.
به همین دلیل زمانی از دقت استفاده می شود که هدف، مینیمم کردن مثبت غلط باشد مانند تشخیص جعلی بودن کارت اعتباری یا تشخیص بیماری.
یک مثبت غلط (FP) زمانی اتفاق می افتد که مدل به اشتباه کلاس مثبت را پیش بینی می کند و نشان می دهد که شرایط داده شده وجود دارد اما در واقعیت رخ نداده است.
در مثال ما، یک مثبت غلط خروجی است که کلاس پیش بینی شده باید 0 می بود اما در واقع 1 است. ستون های به رنگ قرمز، مثبت غلط را نشان می دهد.
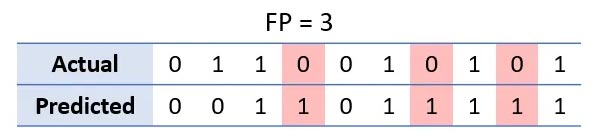
از آنجایی که دقت، نسبت پیش بینی های مثبتی را اندازه می گیرد که در واقع مثبت صحیح هستند، رابطه ی آن بصورت زیر نوشته می شود:

مثال: تشخیص ناهنجاری. برای مثال در تشخیص جعل، دقت می تواند یک معیار ارزیابی مناسب باشد مخصوصا زمانی که هزینه مثبت غلط بالا باشد. شناسایی فعالیت های غیر شیادانه به عنوان تقلب نه تنها هزینه های اضافی را به مبالغ سرمایه گذاری تحمیل می کند بلکه منجر به سطح بالایی از نارضایتی مشتریان و افزایش نرخ رشد آن می شود.
معیار ارزیابی ریکال (Recall)
زمانی که هدف یک تسک پیش بینی مینیمم کردن منفی غلط است، از ریکال به عنوان یک معیار ارزیابی مناسب استفاده می شود. ریکال نسبت مثبت صحیحی را اندازه می گیرد که مدل به درستی آن را تشخیص داده است. این معیار مخصوصا زمانی کاربرد دارد که منفی غلط هزینه ی بیشتری نسبت به مثبت غلط داشته باشد.
یک منفی غلط (FN) زمانی اتفاق می افتد که مدل به اشتباه کلاس منفی را پیش بینی می کند که نشان می دهد شرایط داده شده وجود ندارد در حالی که آن شرایط وجود دارد.
در مثال ما، یک منفی غلط خروجی است که کلاس پیش بینی شده باید 1 می بود اما در واقع 0 است.
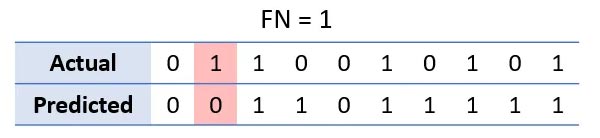
ستون های قرمز منفی غلط را نشان می دهد. ریکال به صورت زیر محاسبه می شود:
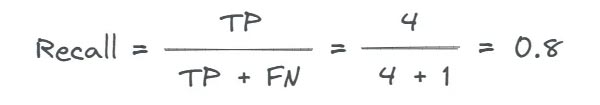
مثال: تشخیص بیماری. برای مثال در تست Covid-19 (کرونا) ، زمانی که هدف “تشخیص هرچه مورد مثبت هست” باشد ریکال گزینه ی مناسبی است . در این شرایط، تعداد زیادی از مثبت غلط دوام می آورند چون الویت مینیمم کردن منفی غلط به منظور جلوگیری از پیش روی بیماری است.
بحث جنجالی بر سر این است که هزینه ی از دست دادن مورد مثبت بسیار بیشتر از به اشتباه طبقه بندی کردن یک مورد منفی به عنوان مورد مثبت است.
معیار ارزیابی F1 Score
در مواقعی که هم مثبت غلط و هم منفی غلط جنبه های مهمی برای تصمیم گیری هستند برای مثال در تشخیص اسپم، F1 Score یک معیار سرراست است.
F1 Score میانگین هارمونیکی از دقت و ریکال است و با در نظرگیری مثبت غلط و منفی غلط، معیار متعادلی از عملکرد مدل ارائه می کند.
این معیار ارزیابی به صورت زیر محاسبه می شود:

مثال( طبقه بندی مدارک): برای مثال در تشخیص اسپم، وقتی که هدف ایجاد یک تعادل میان دقت و ریکال است، F1 Score یک معیار مناسب برای ارزیابی است. یک طبقه بند ایمیل اسپم باید تا جایی که امکان دارد ایمیل های اسپم زیادی را به درستی طبقه کند (ریکال) ضمن اینکه از طبقه بندی ناصحیح ایمیل های عادی به عنوان اسپم جلوگیری کند (دقت).
معیار ارزیابی ناحیه زیر منحنی ROC(AUC)
منحنی مشخصه عملکرد گیرنده یا منحنی ROC گرافی است که عملکرد طبقه بند باینری در تمام آستانه های طبقه بندی را نشان می دهد.
ناحیه زیر منحنی ROC یا AUC این که چقدر یک طبقه بند باینری می تواند کلاس های مثبت و منفی را با آستانه های مختلف از هم سوا کند را اندازه می گیرد.
این معیار مخصوصا زمانی کاربرد دارد که هزینه ی مثبت غلط و منفی غلط متفاوت باشد. زیرا این معیار، trade-off بین نرخ مثبت صحیح (حساسیت:sensitivity) و نرخ مثبت غلط (خاصیت : 1-specificity) در آستانه های مختلف را در نظر می گیرد. با تنظیم آستانه، می توانیم به طبقه بندی برسیم که با توجه به هزینه مثبت غلط و منفی غلط یک مساله خاص، بین حساسیت و خاصیت الویت بندی می کند.
نرخ مثبت صحیح(TPR) یا حساسیت، نسبت موارد مثبت واقعی را اندازه می گیرد که مدل آن ها را به درستی شناسایی کرده است. این دقیقا شبیه ریکال است.
این معیار به صورت زیر محاسبه می شود:

نرخ مثبت غلط (FPR) یا 1-specificity نسبت موارد منفی واقعی را اندازه می گیرد که مدل آن ها را به اشتباه به عنوان مثبت طبقه بندی کرده است.
این معیار به صورت زیر محاسبه می شود:

با تغییر آستانه طبقه بندی از 0 تا 1 و محاسبه TPR و FPR برای هر آستانه ، یک منحنی ROC و مقدار مربوطه AUC می توان به دست آورد. خط مورب، عملکرد طبقه بند رندوم را نشان می دهد – طبقه بند رندوم طبقه بندی است که حدس های رندوم درباره ی برچسب کلاس هر نمونه می زند.
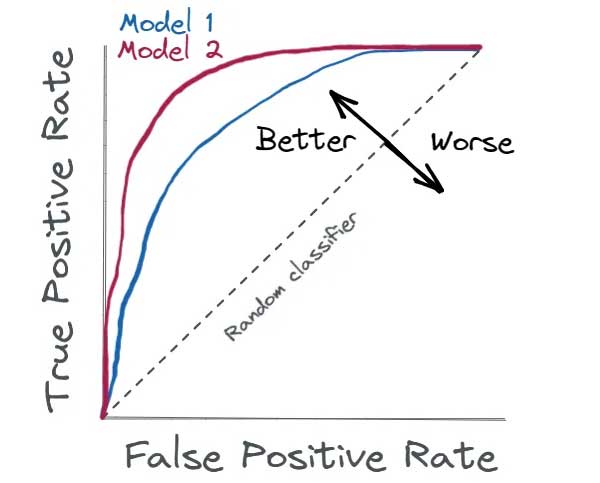
هرچه منحنی ROC به گوشه بالا سمت چپ نزدیکتر باشد، عملکرد طبقه بند بهتر است. اگر AUC مربوطه 1 باشد، طبقه بندی عالی را نشان می دهد در حالی که اگر AUC ، 0.5 باشد عملکرد رندوم طبقه بندی را نشان می دهد.
مثال: مسائل رنکینگ یا درجه بندی. زمانی که هدف، درجه بندی نمونه بر اساس شباهت (likelihood) در یک کلاس یا شباهت به یکدیگر باشد، AUC معیار مناسبی است زیرا می تواند توانایی مدل برای درجه بندی صحیح نمونه ها را نسبت به اینکه فقط آن ها طبقه بندی کند؛ نشان دهد. برای مثال، این معیار در تبلیغات آنلاین به کار برده می شود چون می تواند توانایی مدل برای درجه بندی صحیح کاربران بر اساس شباهت کلیک کردنشان بر یک تبلیغ را ارزیابی کند تا اینکه فقط خروجی باینری کلیک کردن یا کلینک نکردن را پیش بینی کند.
تلفات لگاریتمی-Log Loss
تلفات لگاریتمی که به log loss یا تلفات انتروپی متقابل هم معروف است یک متریک ارزیابی مفید برای طبقه بندی مسائلی است که تخمین احتمال مهم است. log loss تفاوت میان احتمالات پیش بینی شده کلاس ها و برچسب واقعی کلاس را اندازه می گیرد. این معیار مخصوصا زمانی به کار برده می شود که هدف جریمه کردن مدل برای بیش از حد مطمئن بودن از پیش بینی کلاس غلط است. از این معیار به عنوان تابع تلفات(loss function) در آموزش رگرسیون معمولی و شبکه های عصبی نیز استفاده می شود.
برای یک تک نمونه، که y برچسب صحیح و تخمین احتمال را نشان می دهد، log loss به صورت زیر محاسبه می شود:
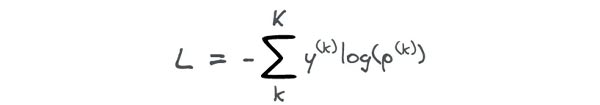
زمانی که برچسب صحیح 1 باشد ، log loss به عنوان تابعی از احتمالا پیش بینی شده به صورت زیر در می آید:
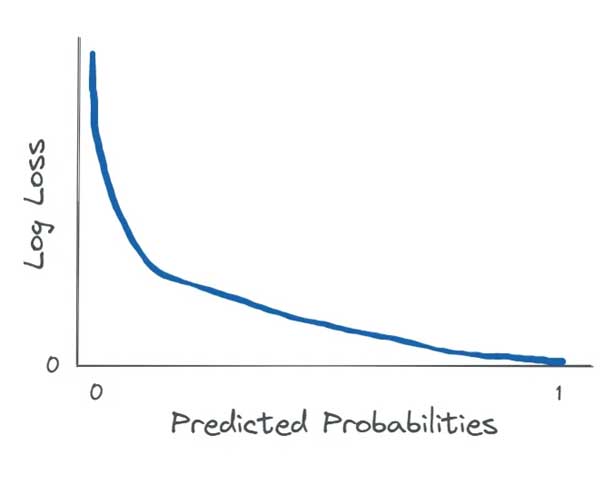
به وضوح می توان دید که هرچه طبقه بند از 1 بودن برچسب صحیح مطمئن تر باشد log loss کوچک تر می شود.
log loss را می توان برای مسائل طبقه بندی چندکلاسه نیز تعمیم داد. برای یک تک نمونه که k برچسب کلاس و K تعداد کل کلاس ها را نشان می دهد؛ log loss را می توان به صورت زیر محاسبه کرد:
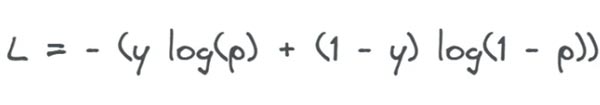
هم در طبقه بندی باینری و هم در طبقه بندی چند کلاسه، log loss یک معیار کمک کننده است که مشخص می کند چقدر احتمالات پیش بینی شده با برچسب های صحیح کلاس مطابقت دارد.
مثال: برآورد ریسک بستانکاری. برای مثال از log loss می توان برای ارزیابی عملکرد یک مدل ریسک بستانکاری -که پیش بینی می کند چقدر یک وام گیرنده در قبال وام قصور می کند- استفاده کرد. هزینه ی منفی غلط (پیش بینی یک وام گیرنده ی قابل اعتماد به عنوان یک وام گیرنده ی غیر قابل اعتماد) می تواند بسیار بیشتر از هزینه ی مثبت غلط (پیش بینی یک وام گیرنده ی غیر قابل اعتماد به عنوان یک وام گیرنده ی قابل اعتماد) باشد. بنابراین، مینیمم کردن log loss می تواند به مینیمم کردن ریسک مالی قرض دادن در این سناریو کمک کند.
نتیجه
برای ارزیابی دقیق عملکرد یک طبقه بند و تصمیم گیری آگاهانه بر اساس پیش بینی های آن، انتخاب یک معیار مناسب ارزیابی ضروری به نظر می رسد. در بسیاری از موارد، این انتخاب به شدت به مساله ی خاص شما بستگی دارد. فاکتورهای مهمی که باید در نظر بگیرید شامل این موارد است :
تعادل میان کلاس ها در یک مجموعه داده/ مینیمم کردن کدام مهم است: مثبت غلط یا منفی غلط یا هر دو؟/ اهمیت درجه بندی و تخمین احتمالات
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)
دیدگاه ها