مفهوم کانولوشن در CNN
- دسته:اخبار علمی
- هما کاشفی
اگر بخواهیم تفاوت اصلی لایههای کانولوشن را با لایههای معمول شبکههای عصبی بیان کنیم، میتوانیم بگوییم لایههای Dense الگوهای global را در فضای ویژگی ورودی خود یاد میگیرند در حالیکه لایههای کانولوشن الگوهای local را یاد میگیرند. برای مثال یک تصویر را میتوان به الگوهای local چون edgeها، textureها و غیره تقسیم کرد. همچنین لایههای کانولوشنی میتوانند ویژگیها را به صورت سلسله مراتبی (از سادهترین ویژگیها چون خط و نقطه تا پیچیدهترین ویژگیها چون یک شی کامل) یاد بگیرند.
لایههای کانولوشنی دو ویژگی جالب دارند:
1)الگوهایی که این شبکهها یاد میگیرند translation-invariant هستند: پس از یاد گیری الگویی خاص در گوشهی پایین سمت راست یک تصویر، یک convnet میتواند ویژگی مشابه آن را در هرجای دیگری از تصویر تشخیص دهد: برای مثال در گوشهی بالا سمت چپ تصویر. یک مدل dense باید این الگو را دوباره به عنوان یک الگوی جدید در یک موقعیت جدید یاد بگیرد. همین امر باعث شده است که شبکههای convnet در هنگام پردازش تصاویر کارایی بیشتری داشته باشند؛ این شبکهها به نمونههای آموزشی کمتری نیاز دارند تا بتوانند بازنماییهایی از تصویر را یاد بگیرند زیرا آنها قدرت تعمیم دهی دارند.
2)آنها میتوانند سلسله مراتب الگوها را یاد بگیرند: اولین لایهی کانولوشن، الگوهای local کوچکی چون لبهها را یاد میگیرد و لایهی کانولوشن دوم الگوهای بزرگتری که از ویژگیهای لایههای اول ساخته شده را یاد میگیرد و به همین ترتیب تا انتها. این قابلیت به شبکههای convnet امکانی میدهد که مفاهیم بصری انتزاعی و پیچیده را یاد بگیرند.
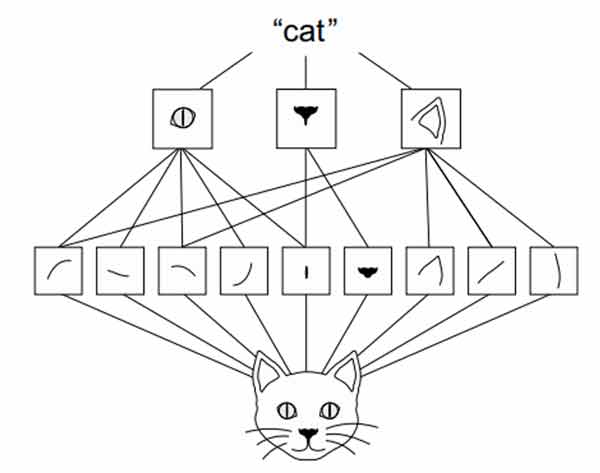
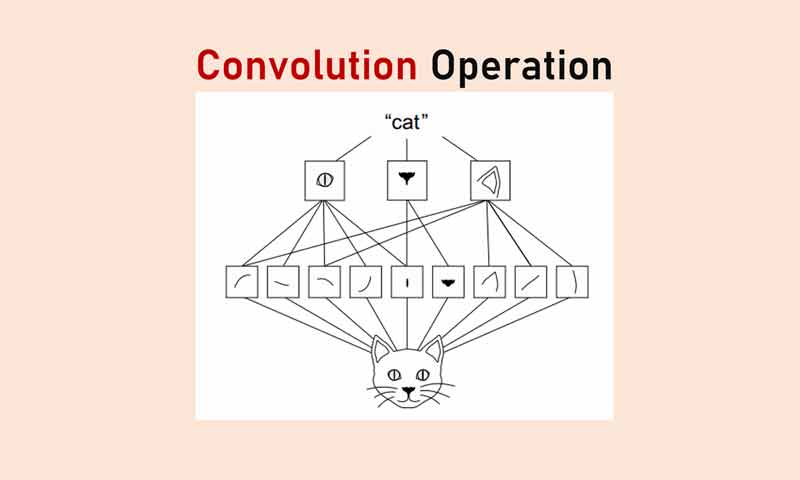
دنیای بصری از سلسله مراتب ماژولهای بصری تشکیل شده است: خطوط اولیه یا بافتهای اولیه به اجزای سادهای چون چشمها یا گوشها تبدیل میشوند و در نهایت به مفاهیم سطح بالاتری چون «گربه» میرسند.
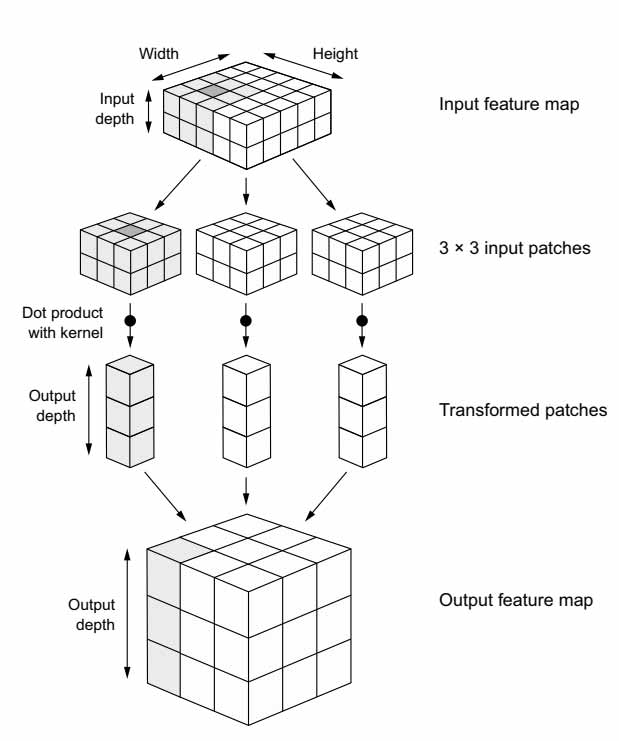
کانولوشن روی تنسورهای سه بعدی به نام feature map انجام میشود که دو محور مکانی (ارتفاع و عرض) و محوری به نام عمق دارد (که کانال نیز نامیده میشود). برای یک تصویر RGB، بعد محور عمق 3 است زیرا تصویر سه کانال رنگی دارد: قرمز، سبز و آبی. برای یک تصویر سیاه و سفید مانند تصاویر دیتاست MNIST، عمق یک است (سطوح خاکستری). عملیات کانولوشن، پچهایی را از feature mapهای ورودی خود استخراج میکند و عملیات مشابهی را روی تمام این پچها اجرا میکند و feature map خروجی را تولید میکند. این خروجی همچنان یک تنسور سه بعدی است: آن دارای عرض و ارتفاع است. عمق آن میتواند دلخواه باشد، زیرا عمق خروجی پارامتری از لایه است و کانالهای مختلف در محور عمق برای رنگهای خاص در ورودی RGB به کار نمیروند بلکه آنها فیلتر هستند. فیلترها، جنبههای خاصی از دادهی ورودی را انکد میکنند: در سطح بالا، یک فیلتر میتواند مفهوم «وجود یک چهره در ورودی» را انکد کند.
در دیتاست MNIST، لایه کانولوشن اول یک feature map به سایز (28,28,1) را به عنوان ورودی میگیرد و feature map خروجی به سایز (26,26,32) را میدهد: این لایه 32 فیلتر را روی ورودی محاسبه میکند. هر یک از این 32 کانال خروجی متشکل از یک شبکه 26*26 از مقادیر هستند که response map فیلتر روی ورودی نامیده میشوند و نشان میدهند که پاسخ الگوی فیلتر در موقعیتهای مختلف ورودی چه است.

مفهوم response map: نگاشت دو بعدی از وجود الگو در موقعیتهای مختلف ورودی
این معنای عبارت feature map است: هر بعد درمحور عمق یک ویژگی (یا فیلتر) است و خروجی یک نگاشت دو بعدی از پاسخ فیلتر به ورودی است.
کانولوشنها را میتوان با دو پارامتر اصلی تعریف کرد:
-سایز پچهای استخراج شده از ورودیها: معمولاً اینها 3*3 یا 5*5 هستند.
-عمق feature map خروجی: این تعداد فیلترهای محاسبه شده توسط کانولوشن است. مثال با عمق 32 آغاز میشود و با عمق 64 به انتها میرسد.
عملیات کانولوشن با لغزش این پنجرههای سایز 3*3 یا 5*5 روی یک feature map ورودی سه بعدی انجام میشود و در هر موقعیت ممکن توقف میکند و پچهای سه بعدی را استخراج میکند. هر پچ سه بعدی به یک بردار یک بعدی تبدیل میشود که با ضرب تنسوری با یک ماتریس وزن آموخته شده انجام میشود و این کرنل برای سراسر پچ استفاده میشود. تمام این بردارها (یک بردار برای هر پچ) سپس به یک خروجی سه بعدی تبدیل میشوند. در شکل زیر نحوهی عملکرد کانولوشن نشان داده شده است.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دیدگاه ها