
چالش های آموزش شبکههای عمیق و راه حل آنها
- دسته:اخبار علمی
- هما کاشفی
یادگیری عمیق و شبکههای عصبی از پیشرفتهترین و پرکاربردترین فناوریهای امروزی هستند. علیرغم پیشرفت قابل توجه آنها، هنوز چالشهای زیادی در یادگیری عمیق وجود دارد که محققان و متخصصان در تلاشند تا بر این چالشها غلبه کنند و مدلهای بهتری را توسعه دهند و به نتایج بهبود یافته دست یابند.
یادگیری عمیق یک رویکرد قدرتمند و محبوب برای ساخت مدلهای یادگیری ماشین است به خصوص برای تشخیص تصویر و گفتار، پردازش زبان طبیعی و موارد دیگر. با این حال، آموزش یک مدل یادگیری عمیق میتواند فرآیندی پیچیده و زمانبر باشد و چالشها و مشکلاتی را به همراه داشته باشد. در این مقاله، برخی از مشکلات رایجی که ممکن است در طی فرآیند آموزش شبکههای عمیق با آنها روبرو شویم را مطرح میکنیم و نحوهی رفع این مسائل را بررسی خواهیم کرد.
فشردهسازی شبکه
تقاضای زیادی برای قدرت محاسباتی بالا و ذخیره سازی وجود دارد. بنابراین ساخت مدلهای با راندمان بالا و بهینه شده با محاسبات کمتر و عملکرد بهتر بسیار اهمیت دارد. اینجا جایی است که فشردهسازی وارد عمل میشود تا با توجه به نرخ محاسبات، عملکرد بهتری داشته باشد. چند روش برای فشردهسازی شبکه عبارتند از:
هرس کردن و اشتراک پارامتر: کاهش پارامترهای اضافی، عملکرد مدل را پایین نمیآورد بنابراین میتوان آنها را حذف کرد.
فاکتورگیری Low-Rank: تجزیه ماتریس برای بدست آوردن پارامترهای مهم شبکههای عمیقی چون CNN
فیلترهای کانولوشنی فشرده: یک کرنل ویژه با پارامترهای کاهش یافته برای صرفهجویی در فضای ذخیره سازی و محاسباتی
متد Knowledge Distillation: یک مدل فشرده را آموزش دهید تا بتوانید مدلی پیچیده را بازتولید کنید.
هرس کردن
هرس کردن روشی برای کاهش تعداد پارامترهاست و برای این منظور نورونهای اضافی یا غیرحساس حذف میشوند. دو روش برای هرس کردن وجود دارد
هرس کردن از طریق وزن
به معنی حذف تک وزنها از شبکه است البته وزنهایی که غیرضروری یا زائد تشخیص داده شدهاند. این کار را میتوان با روشهای مختلفی انجام داد مانند صفر کردن وزنهای کوچک، استفاده از روش هرس مبتنی بر مقدار یا هرس عملکردی. هرس کردن از طریق وزن به کاهش اندازهی شبکه کمک میکند و کارایی آن را بهبود میبخشد و همچنین میتواند ظرفیت شبکه را کاهش دهد اما ممکن است باعث کاهش عملکرد شود. این روش، معماری مدل را تغییر نمیدهد.
هرس کردن از طریق نورونها
شامل حذف کل نورونها یا گروههایی از نورونهای شبکه است که غیرضروری یا زائد هستند. این کار را میتوان با روشهای مختلفی انجام داد مانند استفاده از امتیاز اهمیت برای شناسایی و حذف نورونهای با اهمیت کمتر یا استفاده از الگوریتمهای تکاملی برای تکامل شبکههای کوچکتر.
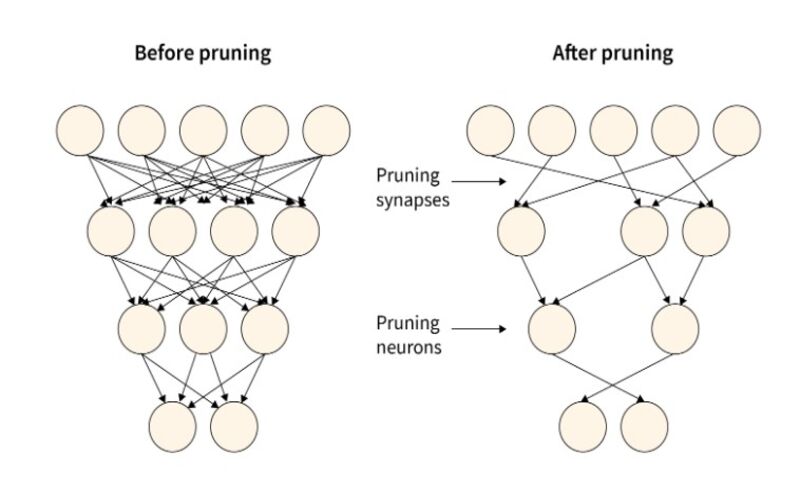
کاهش دامنه مقادیر داده
در یک شبکه عصبی، وزنها، بایاسها و سایر پارامترها به گونهای مقداردهی اولیه میشوند تا 32 بیت اطلاعات را در خود نگه دارند. متغیرهای 32 بیتی با افزودن مقادیر بیشتر باعث افزایش دقت مدل میشوند. اما در کاربردهای عملی، کاهش دقت ممیز شناور از 32 بیت به 16 بیت، خروجی مدل را تغییر نمیدهد.
فرض کنید یک شبکه عصبی ساده با یک ورودی، یک لایه پنهان با دو نورون و یک خروجی داریم. وزنها و بایاسهای شبکه با مقادیر ممیز شناور 32 بیتی مقداردهی اولیه میشوند. شبکه روی یک دیتاست آموزش میبیند و به سطح خاصی از دقت میرسد. اکنون میخواهیم با کاهش دقت وزنها و بایاس از مقادیر ممیز شناور 32 بیتی به 16 بیتی، کارایی شبکه را بهبود بخشیم. برای این منظور کافی است مقادیر 32 بیتی را به 16 بیتی تبدیل کنیم و از آنها برای مقداردهی اولیه شبکه استفاده کنیم.
در طی آموزش متوجه میشویم که شبکه میتواند با دقت ممیز شناور وزن و بایاس کاهش یافته به همان سطح دقت با وزن و بایاس کامل برسد. این بدان معناست که ما توانستیم کارایی شبکه را بدون کاهش عملکرد بهبود بخشیم.
به طور کلی کاهش دقت وزنها و بایاس در یک شبکه عصبی میتواند تکنیکی مفید برای بهبود کارایی مدل باشد بدون اینکه عملکرد آن را به خطر بیندازد اما مهم است که این تغییرات را با دقت انجام دهیم و تأثیر کاهش دقت را بر روی مدل نهایی آزمایش کنیم.
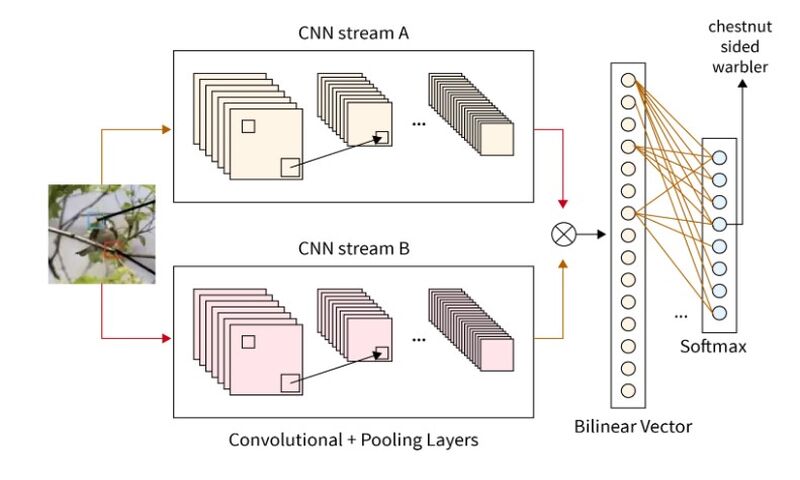
CNN دو خطی
معماری CNN دوخطی، مسئله تشخیص تصویر را در دیتاستهای تصویر fine-grained حل میکند.
یک شبکه CNN دو خطی یا binlinear شامل دو (یا گاهی اوقات تعداد بیشتری) استخراج کنندهی ویژگی است که ویژگیهای مختلف را شناسایی میکند. استخراج کنندههای مختلف ویژگی به عنوان یک بردار دو خطی با هم ترکیب میشوند تا رابطه بین ویژگیهای مختلف را پیدا کند. برای مثال اگر تسک اصلی تشخیص پرنده باشد، یک استخراجگر ویژگی، دم پرنده را شناسایی میکند در حالیکه دیگری منقار را شناسایی میکند. در نهایت این دو استخراجگر ویژگی با هم استنباط کنند که آیا تصویر ارائه شده، تصویر پرنده است یا خیر.
مشکلات Vanishing Gradient و Exploding Gradient
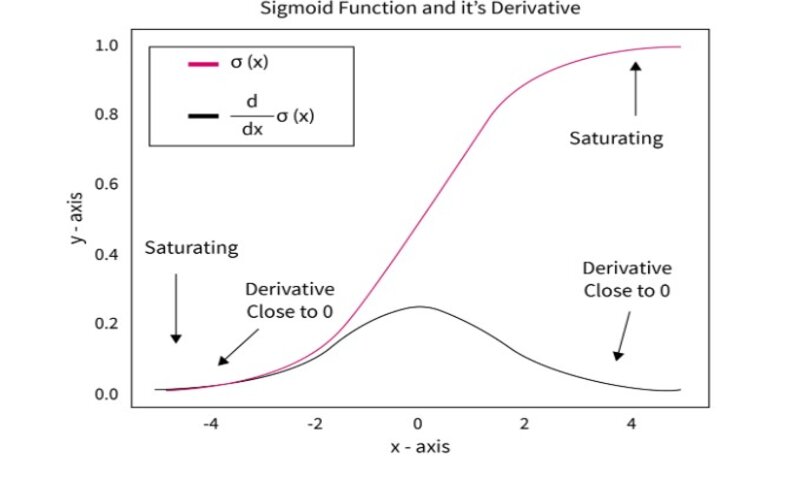
مشکلاتی چون vanishing gradient و exploding gradient در زمان پس انتشار خطا (backpropagation) رخ میدهد. در پس انتشار خطا، سعی میکنیم تا گرادیانهای تابع خطای وزنها را پیدا کنیم. در طی اجرای الگوریتم پس انتشار، بسته به تعداد لایهها، مقادیر چندین بار در هم ضرب میشوند. اگر مقدار وزنها کوچک باشد (کمتر از 1)، روش پس انتشار کاری میکند که مقدار وزنها کوچک و کوچکتر شوند تا در نهایت صفر شوند. این مسئله Vanishing Gradient است.
مسئلهی Exploding gradient نیز مشابه است اما با مقادیر وزنی بسیار بزرگ. اگر مقادیر وزنها بیش از حد بزرگ شوند، الگوریتم پس انتشار خطا مقادیر را بزرگ و بزرگتر میکند و در نهایت محاسبه و آموزش را گاهی اوقات غیرممکن میکند.
علت Vanishing gradient تابع فعالسازی Tanh و Sigmoid است. تابع فعالسازی Tanh شامل مقادیری بین -1 و 1 است. در عین حال، تابع فعالسازی Sigmoid حاوی مقادیری بین 0 و 1 است. این دو تابع فعالسازی، هر مقدار را بین مقادیر کوچک نگاشت میکند و بنابراین مشکل vanishing gradient بوجود میآید.
تابع فعالسازی اشباع نشده
یکی از مشکلات توابع فعالسازی، عدم اشباع است که باعث میشود تابع فعالسازی اشباع نشود. این اتفاق ممکن است باعث ایجاد چندین مشکل شود مانند ناتوانی شبکه در یادگیری، قابلیت تعمیم ضعیف و همگرایی آهسته.
چندین تابع فعالسازی رایج وجود دارند که ممکن است اشباع نشوند مانند تابع فعالسازی خطی و تابع فعالسازی سیگوئید. این توابع فعالسازی زمانی اشباع میشوند که ورودی تابع فعالسازی خیلی کوچک یا خیلی بزرگ شود، اما ممکن است با وجود مقادیر متوسط اشباع نشوند. این مسئله ممکن است یادگیری شبکع را دشوار شود و همگرایی شبکه کند شود.
فرض کنید یک شبکه عصبی ساده با یک لایه ورودی، یک لایه پنهان با دو نورون و یک خروجی داریم. لایه پنهان از تابع فعالسازی سیگوئید استفاده میکند که به صورت زیر تعریف میشود:
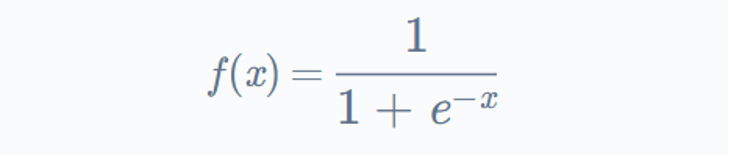
که x ورودی تابع فعالسازی است.
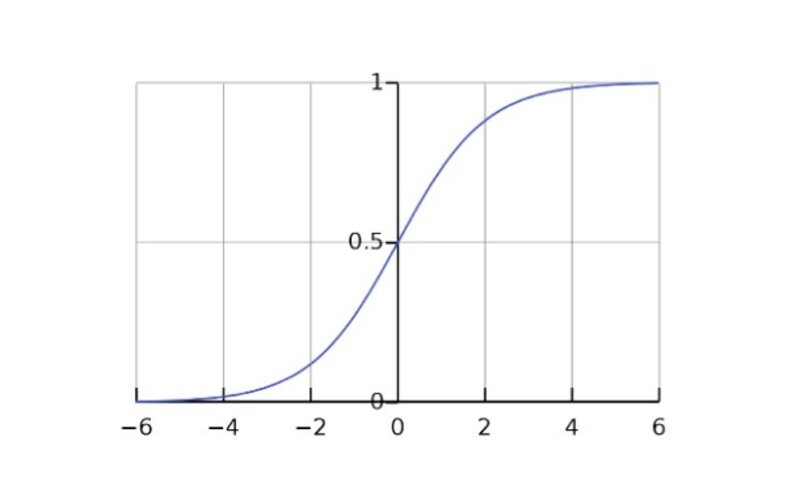
ورودی اولین نورون پنهان مقدار -5 است، ورودی نورون پنهان دوم 5 است. خروجی نورون پنهان اول نزدیک به صفر خواهد شد (زیرا مقدار نمایی بسیار کوچک است) و خروجی نورون پنهان دوم نزدیک به 1 خواهد بود (زیرا مقدار نمایی بسیار بزرگ خواهد شد).
این بدان معنی است که تابع فعالسازی سیگوئید برای هر دوی این مقادیر ورودی اشباع شده است و شبکه عصبی قادر به یادگیری موثر نخواهد بود زیرا گرادیان تابع فعالسازی برای این ورودی بسیار نزدیک به 0 خواهد بود. این مسئله ممکن است به همگرایی کند و قابلیت تعمیم ضعیف منجر شود.
استفاده از تابع فعالسازی که در روند اشباع موثرتر است مانند RelU میتواند از این مشکل جلوگیری کند و بهبود عملکرد شبکه عصبی کمک کند.
روش Batch Normalization
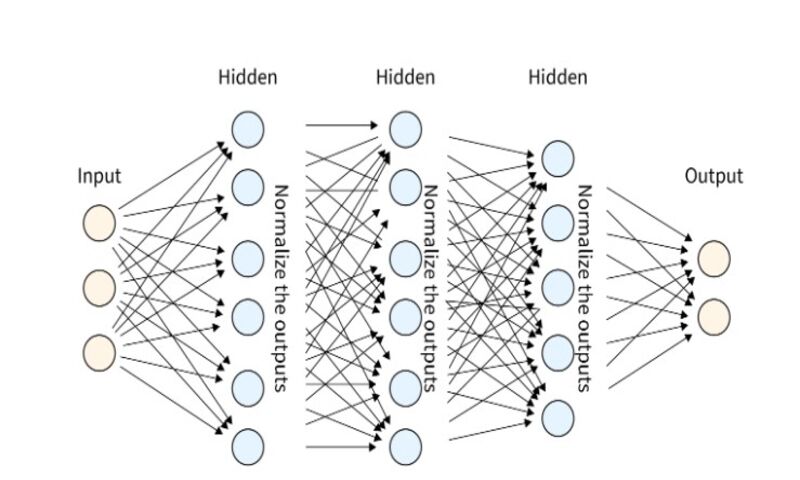
روش Batch Normalization روشی برای نرمال سازی داده پس از استفاده از هر تابع فعالسازی است. نرمال سازی یعنی اینکه مقادیر داده را در یک محدودهی خاص بیاورد. کوچک نگه داشتن دامنه داده باعث میشود زمان آموزش سریعتر شود. همچنین به مشکل تغییر متغیر داخلی کمک میکند و به این معنی است که در طول پس انتشار هر نورون سعی میکند خطا را کاهش دهد. نتیجه لایه قبلی ممکن است در تکرار بعدی تغییر کند و این مشکل با لایههای عمیقتر تقویت شود. این مشکل با نام internal covariate shift شناخته میشود. روش Batch Normalization به حداقل رساندن این مشکل نیز کمک میکند.
مسئله Gradient Clipping
برش گرادیان یا Gradient clipping یک تکنیک بسیار مفید برای غلبه بر مشکل exploding gradient است. در این روش، گرادیانها به یک آستانه محدود میشوند و از آن مقدار فراتر نمیروند. کنترل گرادیانها به رفع مشکل exploding gradient کمک میکند. این روند به ویژه در LSTM مفید است که در آن Exploding Gradient ممکن است به دلیل توابع فعالساز Tanh و Sigmoid رخ دهند. دو روش برای پیادهسازی gradient clipping وجود دارد.
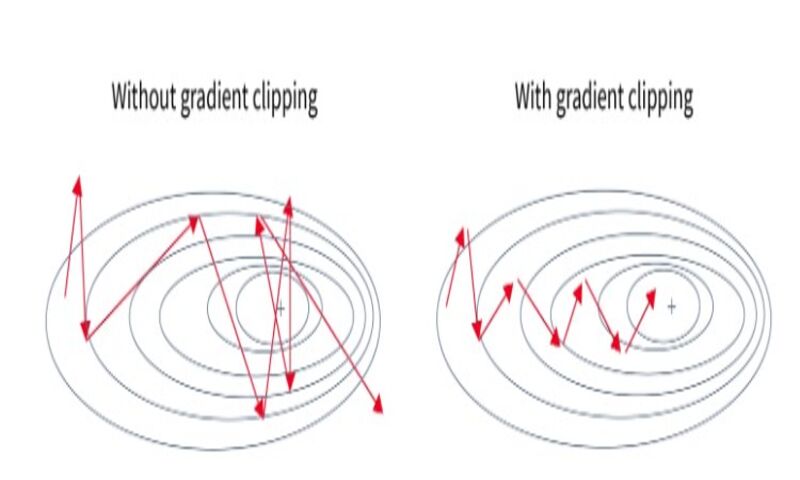
Clipping by value: گرادیانها مقادیر حداکثر و حداقل دارند. مقادیر کران حداکثر یا حداقل در صورتی گرفته میشود که گرادیانها از کرانها بیشتر شوند.
Norm Clipping: همهی گرادیانها با یک مقدار مشخص بریده میشوند تا همیشه زیر مقدار نرمال باقی بمانند.
نتیجهگیری
حل چالشها و محدودیتها در یادگیری عمیق به مدلها و نتایج بهتر منجر میشود.
-هرس کردن و فشرده سازی به کاهش پارامترهای اضافی کمک میکند.
–CNN دوخطی به تشخیص تصاویر finely-grained کمک میکند.
-روش Gradient Clipping به حل مسائل Exploding gradient و Vanishing gradient کمک میکند.
-روش Batch Normalization به زمان آموزش سریعتر منجر میشود و مشکل covariate shift را به حداقل میرساند.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دیدگاه ها