ساخت مدلهای یادگیری عمیق بهتر با Batch Normalization و Layer Normalization
- دسته:اخبار علمی
- هما کاشفی
دو رویکرد Batch Normalization و Layer Normalization دو استراتژی برای آموزش سریعتر شبکههای عصبی هستند بدون اینکه نیاز باشد برای مقدار دهی اولیهی وزنها و سایر تکنیکهای منظمسازی یا Regularization، احتیاط بیش از حد به خرج داد. در این آموزش، ابتدا بررسی میکنیم که چرا نیاز است ورودیهای یک شبکهی عصبی را منظم سازی کنیم و سپس به تکنیکهای Batch Normalization و Layer Normalization میپردازیم.
مقدمه
پیشرفتهای اخیر در پژوهشهای یادگیری عمیق، حوزههای مختلفی چون تصویربرداری پزشکی، بینایی ماشین و پردازش زبان طبیعی را متحول کرده است. با این حال، انتخاب معماری مدل بهینه هنوز برای محققان این حوزه چالش برانگیز است.
حتی با وجود معماری بهینه مدل، نحوهی آموزش مدل میتواند تفاوت قابل توجهی در موفقیت یا شکست آن ایجاد کند. برای مثال، مقداردهی اولیه وزنها را در نظر بگیرید. در فرآیند آموزش یک شبکه عصبی، ما وزنها را در وهلهی اول آموزش میدهیم که با ادامهی فرآیند آموزش، به روزرسانی میشوند. برای یک وزن دهی اولیه تصادفی، خروجیهای یک یا چند لایهی میانی ممکن است به طور قابل توجهی بزرگ باشند. این امر منجر به بی ثباتی روند آموزش میشود. در نهایت بدین معنی است که شبکه در طی آموزش، دانش مفیدی نخواهد آموخت.
چرا لازم است ورودیهای یک شبکه عصبی را منظم سازی کنیم؟
زمانیکه یک شبکهی عصبی را با یک دیتاست آموزش میدهید، ویژگیهای ورودی عددی ممکن است مقادیری داشته باشند که در محدودههای متفاوتی هستند. برای مثال، اگر با دادههای وامهای دانشجویی با ویژگیهای سن دانشجو و شهریه به عنوان دو ویژگی ورودی کار میکنید این دو مقدار در مقیاسهای کاملاً متفاوتی هستند. در حالیکه میانگین سنی یک دانشجو بین 18 تا 25 سال است. شهریه ممکن است در محدودهی 20 تا 50 هزار دلار برای یک سال تحصیلی معین باشد.
همین که شروع به آموزش مدل خود روی چنین مجموعه دادههایی با ویژگیهای ورودی مقیاس مختلف میکنید، متوجه خواهید شد که آموزش شبکه عصبی، زمان قابل توجهی نیاز دارد. زیرا در حالتی که ویژگیهای ورودی همه در یک مقیاس نباشند، الگوریتم گرادیان نزولی به زمان بیشتری برای همگرایی نیاز دارد. علاوه بر این، چنین مقادیر بالایی ممکن است در لایههای شبکه منتشر شوند و منجر به انباشتگی خطاهای بزرگی شوند. در نهایت فرآیند آموزش را ناپایدار میکند که به این مشکل exploding gradient میگویند.
برای غلبه بر مشکلات فوق مربوط به زمان طولانی آموزش و بی ثباتی آموزش، لازم است قبل از آموزش، دادههای خود را پیش پردازش کنید. تکنیکهای پیش پردازش مانند Normalization و standardization باعث میشوند که دادههای ورودی به یک مقیاس خاص تبدیل شوند.
Normalization در برابر Standardization
روند Normalization به این صورت کار میکند که تمام مقادیر یک ویژگی به محدودهی [0,1] انتقال داده میشود. برای این منظور لازم است که از تبدیل زیر استفاده شود:
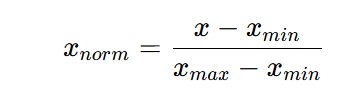
فرض کنید که یک مقدار ویژگی ورودی خاص x مقادیری در محدودهی [x_min, x_max] داشته باشد. زمانی که x برابر با x_min است، x_norm برابر با صفر است و زمانی که x برابر با x_max است، x_norm برابر با 1 است. بنابراین برای تمام مقادیر x بین x_min و x_max، مقدار x_norm به مقادیر بین 0 و 1 نگاشت میشود.
از سوی دیگر Standardization مقادیر ورودی را به گونهای تغییر میکند که از توزیعی با میانگین صفر و واریانس یک تبعیت میکند. از نظر ریاضیاتی، تبدیل روی نقاط داده در توزیعی با میانگین و انحراف معیار به صورت زیر است:
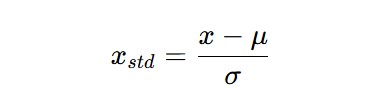
در عمل، این فرآیند standardization اغلب normalization هم نامیده میشود. به عنوان بخشی از فرآیند پیش پردازش، شما میتوانید لایهای را اضافه کنید. این تبدیل را روی ویژگیهای ورودی اعمال کند بنابراین همهی ویژگیهای ورودی، توزیع یکسانی خواهند داشت. در فریم ورک keras پایتون، میتوانید لایهی normalization را اضافه کنید که این تبدیل را روی ویژگیهای ورودی اعمال میکند.
نیاز به Batch Normalization
در بخش قبل، یاد گرفتیم که چگونه میتوانیم ورودی شبکه عصبی را نرمال کنیم تا روند آموزش را سرعت ببخشیم. اگر به معماری شبکه عصبی نگاهی بیندازید، لایهی ورودی تنها لایهی ورودی نیست. برای یک شبکه عصبی با لایههای پنهان، خروجی لایهی k-1 به عنوان ورودی لایهی k عمل میکند. اگر ورودیهای یک لایهی خاص، تغییرات شدیدی داشته باشند، با مشکل گرادیانهای ناپایدار روبرو خواهیم شد.
زمانی که با دیتاستهای بزرگ کار میکنیم، میتوان دیتاست را به چندین batch یا دسته تقسیم کنید و گرادیانهای نزولی را روی mini-batchها ببینید. الگوریتم گرادیان نزولی mini-batch، پارامترهای شبکه عصبی را به این صورت بهینه سازی میکند که مجموعه داده را به صورت دستهای پردازش میکند؛ یعنی هر بار یک دسته.
همچنین این امکان وجود دارد که توزیع ورودی در یک ورودی خاص همچنان در بین دستهها تغییر کند. مقالهی اصلی با نام Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift نوشتهی Sergey loffe و Christian Szegedy به این تغییر در توزیع ورودی برای یک لایهی خاص در بین دستهها اشاره دارد. به عنوان مثال اگر توزیع دادهها در ورودی لایهی K در بین دستهها تغییر کند، آموزش شبکه به زمان بیشتری نیاز دارد.
چرا این امر، روند آموزش را مختل میکند؟
برای هر batch در مجموعه دادهی ورودی، الگوریتم گرادیان نزولی mini-batch به روزرسانیهای خود را انجام میدهد. این الگوریتم، وزنها و بایاسها (پارامترهای) شبکه عصبی را به روزرسانی میکند. تا با توزیع ورودی لایهی خاص برای batch فعلی مطابقت داشته باشد.
اکنون که شبکه یاد گرفته است که با توزیع فعلی انطباق پیدا کند، اگر توزیع برای batch بعدی تغییر اساسی داشته باشد، اکنون باید پارامترها را برای تناسب با توزیع جدید به روزرسانی کند. این امر، روند آموزش را کند خواهد کرد.
با این حال، اگر ایدهی نرمال سازی ورودی را به لایههای پنهان شبکه منتقل کنیم، میتوانیم به طور بالقوه بر محدودیتهای فعالسازیهای انفجاری و توزیعهای نوسانی در ورودی لایه غلبه کنیم.
تکنیک Batch Normalization چیست؟
برای هر لایهی پنهان h، ورودیها را از یک تابع فعالسازی غیرخطی عبور میدهیم تا به خروجی برسیم. برای هر نورون (فعالسازی) در لایهی خاص، میتوانیم محدودیتی بر پیش فعالسازیها اعمال کنیم که همگی میانگین صفر و انحراف معیار یک داشته باشند. برای این منظور کافی است میانگین را از هر یک از ویژگیهای ورودی در mini-batch کسر کنیم و آن را بر انحراف معیار تقسیم کنیم.
به دنبال خروجی لایهی k-1، میتوانیم لایهای اضافه کنیم که این عملیات normalization را در mini-batch انجام دهد بنابراین پیش فعالسازیها در لایهی k، گاوسی واحد هستند. شکل زیر این موضوع را نشان میدهد.
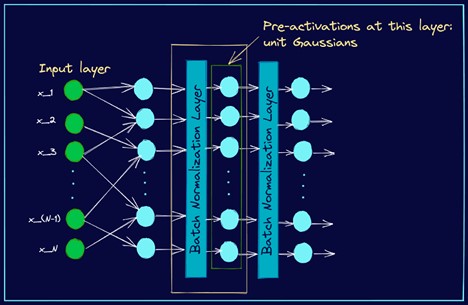
بخشی از یک شبکه عصبی به همراه لایهی Normalization
به عنوان مثال، یک mini-batch با سه نمونهی ورودی را در نظر بگیرید، که هر بردار ورودی دارای چهار ویژگی است. در ادامه تصویری آمده است که به سادگی نشان میدهد که چگونه میانگین و انحراف معیار در این حالت محاسبه میشوند.
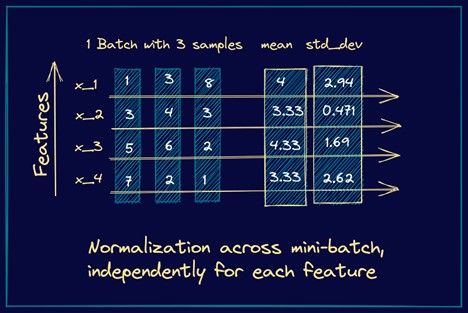
نحوهی کار Batch Normalization
با این حال، اینکه محدودیتی به شبکه اعمال کنیم که پیش فعالسازیها یا pre-activationها در همه ی batchها میانگین صفر و انحراف معیار یک داشته باشند ممکن است بسیار محدود کننده باشد. ممکن است حالتی پیش بیاید که توزیعهای نوسانی برای شبکه ضروری باشد تا کلاسهای خاص را بهتر یاد بگیرند.
برای رفع این مسئله، batch normalization دو پارامتر معرفی میکند. گاما ضریب مقیاس پذیری (scaling factor) و آفست beta . اینها پارامترهای قابل یادگیری هستند. بنابراین اگر به نوسانی در توزیع ورودی نیاز باشد تا شبک عصبی یک کلاس خاص را بهتر یاد بگیرد، سپس شبکه مقادیر بهینه گاما و بتا را برای هر mini-batch بهتر خواهد آموخت. پارامترهای گاما و بتا قابل یادگیری هستند. به طوریکه امکان بازگشت از پیش فعالسازیهای نرمال شده به توزیعهای واقعی وجود دارد.
با در نظر گرفتن تمام مواردی که ذکر شد، مراحل زیر را برای batch normalization در اختیار داریم. اگر x(k) پیش فعالسازیهای مربوط به نورون kام در یک لایه داشته باشد، آن را با x نشان میدهیم تا نمادگذاری را ساده کرده باشیم.

محدودیتهای Batch Normalization
دو محدودیت Batch Normalization ممکن است ایجاد شود:
در batch normalization، از آمارههای batch استفاده میکنیم: میانگین و انحراف معیار مربوط به mini-batch فعلی. با این حال، زمانیکه سایز batch کوچک است، میانگین نمونه و انحراف معیار نمونه به اندازهی کافی نماینده ی توزیع واقعی نیستند. در نهایت شبکه نمیتواند اطلاعات معنی داری را بیاموزد.
از آنجاییکه batch Normalization به آمارههای batch برای نرمال سازی بستگی دارد، برای مدلهای توالی یا sequence چندان مناسب نیست. این به این دلیل است که در مدلهای توالی ممکن است توالیهایی با طولهای متفاوت داشته باشیم. و یا سایز batch کوچکتر برای توالیهای طولانیتر داشته باشیم.
در ادامه Layer Normalization را بررسی میکنیم تکنیک دیگری که میتوان آن را برای مدلهای sequence استفاده کرد. برای شبکههای عصبی کانولوشنی (ConvNets)، batch normalization همچنان برای آموزش سریعتر توصیه میشود.

درک نحوهی عملکرد Batch Normalization در زمان آموزش و تست بسیار مهم است. در زمان آموزشBatch Normalization میانگین و انحراف معیار مربوط به mini-batch را محاسبه میکند.
با این حال، در زمان تست (استنتاج)، ممکن است لزوماً batchای برای محاسبهی میانگین و واریانس در اختیار نداشته باشیم. برای غلبه بر این محدودیت، مدل با نگهداری moving average میانگین و واریانس در زمان آموزش کار میکند که moving mean و moving variance نامیده میشود. این مقادیر در تمام batchها در زمان آموزش جمع میشوند. و به عنوان میانگین و واریانس در زمان استنتاج استفاده میشوند.
مفهوم Layer Normalization چیست؟
مفهوم Layer Normalization توسط محققانی چون Jimmy Lei Ba، Jamie Ryan Kiros و Geoffrey E.Hinton پیشنهاد شد. در Layer Normalization، تمامی نورونها در یک لایهی خاص به طور موثر، توزیع یکسانی در همهی ویژگیهای یک ورودی دارند.
برای مثال، اگر هر ورودی دارای d ویژگی باشد، آن یک بردار d بعدی است. اگر B عنصر در یک batch وجود داشته باشند، نرمال سازی در طول بردار d بعدی انجام میشود و نه در طول batch با سایز B.
نرمال سازی در طول تمام ویژگیها برای هر ورودی به یک لایهی خاص، وابستگی به batchها را حذف میکند. این امر باعث میشود که layer normalization برای مدلهای توالی مانندtransformerها و RNNها که در دورهی قبل از ترانسفورمرها محبوب بودند مناسب باشند.
در اینجا مثالی وجود دارد محاسبهی میانگین و واریانس را برای layer normalization نشان میدهد. ما مثالی از mini-batch را در نظر میگیریم که سه نمونهی ورودی دارد که هر یک چهار ویژگی دارند.
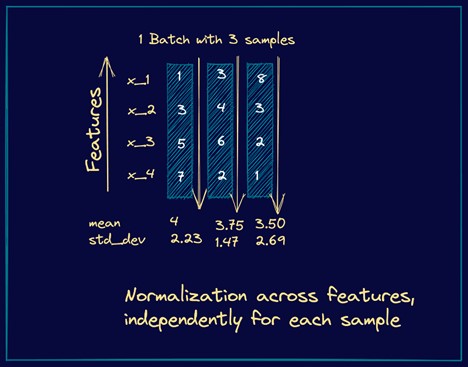

با توجه به روابط فوق، مشاهده میکنیم که این مراحل شبیه به مراحلی هستند که در batch normalization داشتیم. با این حال، به جای batch statistics، از میانگین و واریانس مربوط به یک ورودی خاص یک نورون در لایهی خاص مثلاً k استفاده میکنیم. این روند، معادل با نرمال سازی بردار ورودی از لایهی k-1 است.
چطور Layer Normalization را در فریم ورک Keras اضافه کنیم؟
مشابه با batch normalization، فریم ورک کراس یک کلاس LayerNormalization ارائه کرده است. میتوانید آن را استفاده کنید و layer normalization را به ورودیهای یک لایهی خاص اضافه کنید. کد زیر نشان میدهد که چطور میتوانید layer normalization را به یک مدل توالی ساده اضافه کنید. محور پارامتر، محوری که در امتداد آن نرمال سازی باید انجام شود را مشخص میکند.

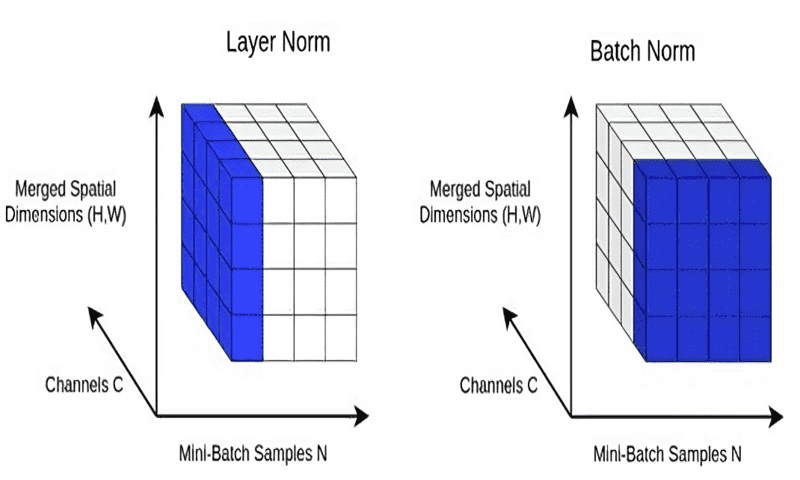
Batch Normalization در برابر Layer Normalization
تا به این جا، آموختیم که batch normalization و layer normalization چطور کار میکنند. حال میخواهیم تفاوتهای اصلی این دو تکنیک را خلاصهسازی کنیم.
رویکرد Batch Normalization هر ویژگی را به طور مستقل در هر mini-batch نرمال سازی میکند. Layer Normalization هر ورودی را در batch مستقل از تمام ویژگیهای دیگر، نرمال سازی میکند.
از آنجاییکه batch normalization به سایز batch بستگی دارد، برای اندازههای batch کوچکتر مناسب نیست. Layer normalization مستقل از سایز batch است. بنابراین میتوان را به batchهای با اندازههای کوچکتر نیز اعمال کرد.
رویکرد batch normalization به پردازشهای متفاوتی در زمان آموزش و استنتاج نیاز دارد. از آنجاییکه layer normalization در طول ورودی یک لایهی خاص انجام میشود، در زمان آموزش و استنتاج، مجموعه عملیات یکسانی صورت خواهد گرفت.
منابع:
[1] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift [2] Layer Normalization [3] ?How Does Batch Normalization Help Optimization [4] PowerNorm: Rethinking Batch Normalization in Transformers [5] Batch Normalization Layer in Keras [6] Layer Normalization Layer in Keras
دوره های مرتبط
پیاده سازی شبکه عصبی پرسپترون تک لایه (جلسه دوم)

دیدگاه ها