مفهوم آموزش خصمانه (Adversarial Training)
- دسته:اخبار علمی
- هما کاشفی
در بسیاری از مواقع شبکههای عصبی که روی دیتاستهای تست i.i.d ارزیابی میشوند، به عملکردی نزدیک به عملکرد انسانی دست پیدا میکنند. طبیعی است که تعجب کنیم آیا واقعاً این مدلها، درکی در سطح انسان از تسکها کسب کردهاند؟ به منظور بررسی میزان درک یک شبکه از تسک موردنظر، میتوانیم نمونه دادههایی را جستجو کنیم که مدل آنها را به درستی کلاسبندی نمیکند. این بار سعی میکنیم مدل را به طور خصمانهتری آموزش دهیم.
نمونه داده آموزشی خصمانه
می خواهیم بدانیم آموزش خصمانه چیست؟ Szegedy و همکاران (2014) دریافتند که حتی شبکه عصبیهایی که با دقت سطح انسانی عمل میکنند، روی نمونه دادههایی که عمداً با یک تابع بهینه سازی تغییر داده شدهاند که شبکه به دنبال نقطه دادهی x’ در نزدیکی نقطه دادهی x بگردد و خروجی مدل در نقطه ی x’ بسیار متفاوت از x است، نرخ خطای 100% خواهند داشت. در بسیاری از مواقع، x و x’ آنقدر به هم شبیه هستند که یک انسان نمیتواند تفاوت بین نمونه دادهی اصلی و نمونه دادهی خصمانه Adversarial را تشخیص دهد. اما شبکه، پیش بینیهای کاملاً متفاوتی روی این دو ورودی دارد.
نمونه دادههای خصمانه، پیامدهای زیادی دارد برای مثال در امنیت کامپیوتری. با این حال، این موضوع، موضوع جالبی در زمینه رویکردهای منظم سازی (regularization) است. میتوان با استفاده از آموزش خصمانه، نرخ خطا را روی مجموعه دادهی تست i.i.d تغییر داد. (Szegedy et al., 2014b; Goodfellow et al., 2014b).
علت عملکرد پایین مدل در مواجهه با نمونه های خصمانه
Goodfellow و همکارانش (2014b) نشان دادند یکی از علل این نمونههای خصمانه، خطی بودن بیش از حد است. شبکههای عصبی عمدتاً از بلوکهای ساختاری کاملاً خطی ایجاد شدهاند. در برخی از آزمایشها، تابعی که اجرا میکنند بسیار خطی میباشد. بهینهسازی این توابع خطی، ساده است. متأسفانه، اگر تابع خطی، ورودیهای متعددی داشته باشد. مقدار تابع به سرعت تغییر میکند. اگر هر ورودی را به اندازهی ε تغییر دهیم، سپس تابع خطی با وزنهای w به میزان
||ε||w تغییر خواهد کرد. اگر w ابعاد بالایی داشته باشد، این مقدار بسیار بزرگ خواهد شد. آموزش خصمانه، این رفتار خطی مدل را ضعیف میکند به این صورت که شبکه عصبی را تشویق میکند تا در همسایگی دادهی آموزشی، به صورت محلی ثابت عمل کند. با استفاده از آموزش خصمانه میتوان قدرت یک تابع بزرگ را در ترکیب با منظم سازی تهاجمی (aggressive regularization) نمایش داد. مدلهای صرفاً خطی مانند رگرسیون لجستیک نمیتوانند در برابر مدلهای خصمانه مقاومت کنند. زیرا آنها مجبور هستند که خطی باشند. شبکههای عصبی میتوانند توابع مختلفی از کاملاً خطی تا تقریباً ثابت محلی را نمایش دهند. بنابراین انعطاف پذیری لازم را دارند تا روند خطی را در مجموعهی آموزشی ثبت کنند. و در عین حال، مقاومت در برابر اختلال محلی را یاد بگیرند.
آموزش خصمانه و یادگیری نیمه نظارتی
نمونه دادههای خصمانه همچنین ابزاری برای یادگیری نیمه نظارتی (semi-supervised) فراهم میکنند. در نقطه x که در دیتاست آموزشی برای آن برچسبی تعریف نشده است، مدل خودش برچسب yˆ را به آن نمونه x اختصاص میدهد. برچسب مدل yˆ ممکن است برچسب درستی نباشد، اما اگر مدل کیفیت بالایی داشته باشد، yˆ به احتمال بالایی برچسب درست را نشان خواهد داد. ما میتوانیم به دنبال نمونه ی خصمانه x’ باشیم که باعث شود کلاسیفایر برچسب yˆ را برگرداند که yˆ ≠y است. نمونه دادههای خصمانه توسط برچسب اصلی تولید نمیشوند. بلکه با برچسبی که مدل آموزش دیده در اختیارما قرار میدهد. که نام آن نمونه دادهی خصمانه مجازی Virtual Adversarial example نام دارد.(Miyato و همکاران 2015)
سپس کلاسیفایر آموزش خواهد دید تا به نمونه دادههای x, x’ برچسبهایی را اختصاص دهد.
این روند کلاسیفایر را تشویق میکند تا تابعی را یاد بگیرد که در برابر تغییرات کوچکی در هر نقطهای از منیفولد که دادههای بدون برچسب قرار دارند، مقاوم باشد.
فرض بر این است که کلاسهای مختلف روی منیفولدهای جداگانه قرار میگیرند. و یک اختلال کوچک نباید باعث شود کلاس یک نمونه داده از یک منیفولد به منیفولد دیگر تغییر کند.
آموزش خصمانه و Robustness مدل
یکی از راههای درک و ارزیابی قابلیت اطمینان مدلها، کمی کردن استحکام (Robustness) و قدرت آنها است. یک مدل قوی تر نسبت به تغییرات، حساسیت کمتری دارد. پیش بینی های پایداری دارد. و در سناریوهای مختلف قابل اعتمادتر خواهد بود.
استحکام یک مدل به زبان ساده به معنی تغییر در خروجی یا پیش بینیهای مدل با توجه به تغییر در ورودیهای آن است. راههای مختلفی برای بررسی این مسئله وجود دارد. برای مثال، مدلی که برای تشخیص تصاویر سگ و گربه دنیای واقعی آموزش دیده است، آیا میتواند طرحها یا تصاویر کارتونی گربهها یا سگها را در زمان تست تشخیص دهد؟. یا با آموزش دیدن روی تصاویر گربه و سگ، آیا میتواند تصاویر گربهها و سگها را با میزان کمی نویز نامحسوس (که با چشم غیرمسلح قابل مشاهده نیست) را تشخیص دهد؟
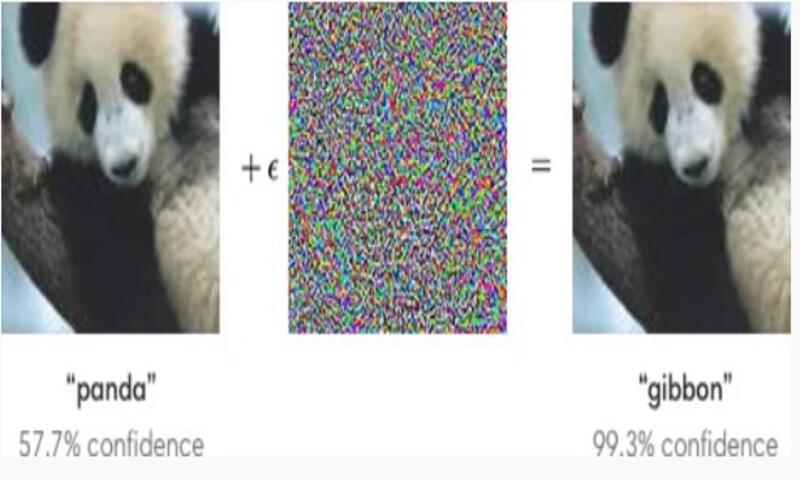
شکل زیر دو تصویر را نشان میدهد که اولی تصویری از دنیای واقعی است . و در تصویر دیگر مقدار کمی نویز نامحسوس به آن اضافه شده است. آیا میتوانید پس از نگاه کردن به تصاویر بگویید که کدامیک حاوی نویز است؟

اگر تصویر اول را از مدل عبور دهیم، پاندا را به عنوان کلاس صحیح پیشبینی میکند. اگر همین کار را برای تصویر دوم انجام دهیم، گورکن را به عنوان کلاس صحیح پیشبینی میکند. توجه داشته باشید که حتی اگر تصاویر با چشم غیر مسلح یکسان به نظر می رسند، پیش بینی مدل تغییر می کند. میتوانیم این واقعیت را اینطور تفسیر کنیم: مدل ما در برابر این تغییر نامحسوس یا نویز که به تصویر خود اضافه کردهایم مقاوم نیست.
ویژگی های نمونه دادهی خصمانه
متوجه می شویم که هر نمونه داده ی خصمانه باید دو ویژگی داشته باشد:
1)باید کاملاً مشابه نمونه دادهی اصلی باشد
2)باید مدل ما را «گول بزند» و پیشبینی آن را تغییر دهد.
با استفاده از این روش آموزش میتوانید قدرت و قابلیت انعطاف مدلهای خود را بالا ببرید و شکاف بین عملکرد مدل هایتان در شرایط قابل پیش بینی و پیش بینی نشده را کاهش دهید.
دوره های مرتبط

پردازش سیگنال مغزی با کتابخانه MNE پایتون

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)
دیدگاه ها