تکنیک آدابوست adaboost
آدابوست یکی از تکنیکهای یادگیری جمعی هست که در آن چندین مدل ضعیف(weak leaner) به صورت سازگار باهم ترکیب می شوند تا بتوانند یک مسئله پیچیده را حل کنند. از تکنیک آدابوست برای کاهش بایاس مدل استفاده میکنند. در این پست میخواهیم رویکرد آدابوست را توضیح داده و سپس بررسی کنیم که کجاها میتونیم از آدابوست استفاده کنیم و کجاها نمیتونیم از آدابوست کنیم.
آدابوست
آدابوست(ada-boost) اختصار کلمه adaptive boosting (تقویت سازگار) است و همانطور که از اسم این تکنیک مشخص است هدف این تکنیک تقویت سازگار توان مدل یادگیری ماشین در حل مسئله است.
در تکنیک آدابوست، چندین مدل یادگیری ماشینِ ضعیف که جنس همه هم یکی هست، به صورت سازگار با هم ترکیب می شوند تا یک مسئله پیچیده را حل کنند.
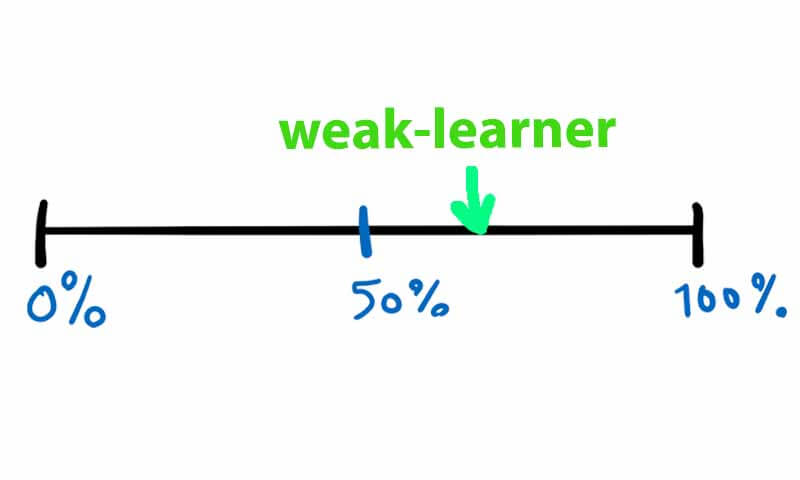
مدل ضعیف(weak leaner)
مدل ضعیف از دید یادگیری ماشین مدلی هست که از حالت شانسی بهتر عمل میکند ولی توان حل کامل یک مسئله را ندارد. برای مثال در یک مسئله طبقه بندی دو کلاسه که سطح شانسی 50 درصد است، مدلهایی که عملکردر رنج 55 تا 65 دارند به عنوان مدل ضعیف در نظر گرفته می شوند.
نحوه آموزش مدلهای یادگیری ماشین با آدابوست
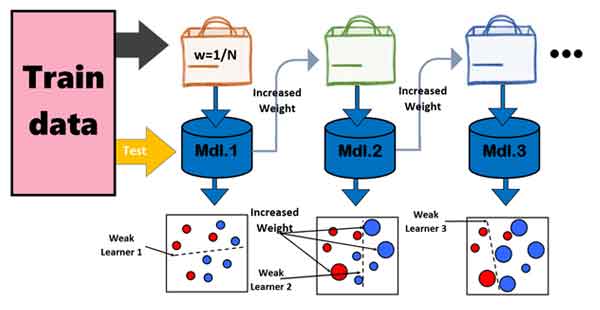
در این تکنیک مدلها به صورت سلسله مراتبی آموزش داده می شوند و نحوه آموزش مدلها به این صورت هست که هر مدل هدفش حل برطرف کردن ایرادات(خطای) مدلهای قبل تر از خودش هست و براساس میزان خطایی که هر مدل بدست می آورد یک وزنی به آن اختصاص می باید که از این وزنها در پروسه تست، به عنوان میزان اهمیت رای مدلها استفاده می شود.
- همانطور که اشاره کردیم مدلها به صورت سلسله مراتبی آموزش می بیننند، یعنی اول مدل 1 آموزش می بیند، سپس مدل 2، مدل 3 و به همین ترتیب تا آخرین مدل.
- هر مدل هدفش این است که خطای مدلهای قبلی را جبران کند، یعنی اینکه بیاید نمونه هایی که مدل قبلی نتوانسته به درستی طبقه بندی کند را درست طبقه بندی کند، یا اینطور بگیم که تمرکزش روی نمونه هایی هست که مدلهایی قبلی نتوانسته اند به درستی دسته بندی کنند.
- و اینم داشته باشیم که تمام نمونه هایی آموزشی در پروسه آموزش یک وزنی خواهند داشت و این وزن براساس خطای مدلهای یادگیری ماشین بدست می آید.
- وزن نمونه های آموزشی اهمیت آنها را مشخص میکند و مدلهای یادگیری ماشین با کمک این وزن متوجه می شوند که کدام نمونه ها اهمیت بیشتری دارند، یا به عبارتی کدام نمونه ها در مراحل قبلی توسط مدلهای یادگیری ماشین قبلی به درستی طبقه بندی نشده اند تا تمرکز خود را روی این نمونه های با اهمیت زوم بکنند و سعی کنند آنها و یا بخشی از آنها را به درستی طبقه بندی کنند.
- با این رویکرد ساده ، آدابوست با کمک مدلهای ضعیف یک مسئله پیچیده را حل میکند و یا به عبارتی توان مدلهای ضعیف را تقویت میکند تا بتوانند یک مسئله پیچیده را به راحتی حل کنند.
جزئیات آموزش آدابوست
- تعداد مدلهای یادگیری ماشین توسط کاربر(بسته به نیاز) تعیین می شود
- در ابتدای پروسه آموزش به تمام نمونه های آموزشی وزن یکسانی اختصاص می یابد
- سپس از بین داده های آموزشی یک تعداد به صورت تصادفی انتخاب می شوند تا از آنها برای آموزش مدل یادگیری ماشین اول استفاده شود.
- بعد از آموزش مدل اول، با کل داده های تست، تست می شود تا خطای مدل بدست بیاید و از طرفی متوجه شویم که کدام نمونه ها را به اشتباه دسته بندی کرده است.
- براساس میزان خطایی که دارد یک وزنی به خود مدل اختصاص می یابد تا در پروسه تست اهمیت رای آنرا مشخص کند.
- سپس وزن نمونه هایی که درست طبقه بندی شده اند کمتر شده و وزن نمونه هایی که اشتباه دسته بندی شده بیشتر می شود. با اینکار مدل بعدی متوجه می شود که کجا باید تمرکز کند و سعی کند چه نمونه هایی را درست دسته بندی کند.
- این پروسه به ازای تمام مدلهای یادگیری ماشین تکرار می شود.
نحوه تخمین لیبل خروجی با مدلهای یادگیری ماشین در آدابوست
در پروسه آموزش ما تعدادی مدل یادگیری ماشین آموزش داده ایم که هر کدام یک وزنی هم دارند که میزان اهمیت رای آنها را مشخص میکند. برای تخمین لیبل داده جدید، در ابتدا داده جدید را به همه مدلهای یادگیری ماشین ارائه می دهیم تا براساس دانشی که در پروسه آموزش بدست آوردند لیبل داده جدید را تخمین بزنند. امکان اینکه مدلها نظر متفاوتی داشته باشند زیاد است، برای اینکه متوجه شویم لیبل نهایی داده جدید چی هست، رای گیری انجام میدهیم، اما رای گیری وزندار!!! در پروسه آموزش به هر مدل یک وزنی براساس خطایی که داشت، اختصاص یافته است، از آن به عنوان میزان اهمیت رای مدل استفاده میکنیم و رای گیری را به صورت وزندار انجام میدهیم.
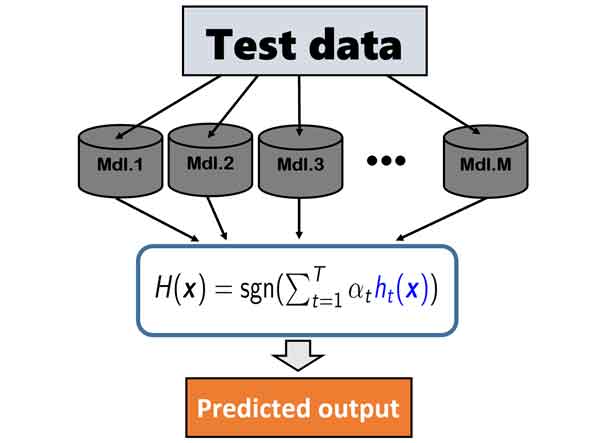
اهمیت رای مدلی که وزن بیشتری دارد نسبت به مدلی که وزن کمتری دارد، بیشتر است.
در چه زمانی بهتر است از آدابوست استفاده کنیم و در چه زمانی بهتر است از آدابوست نکنیم؟
توجه داشته باشیم که هدف آدابوست حل مسئله بایاس مدل هست. یعنی یک مدل به تنهایی توان حل مسئله را ندارد و بایاسش زیاد هست و یا به عبارتی دقت و عملکرد مدل پایین هست. در چنین مسائلی میتوانیم از تکنیک آدابوست استفاده کنیم تا بایاس را کاهش داده و دقت را افزایش دهیم.
اگر دقت یک مدل یادگیری ماشین در یک مسئله ای بیشتر است، مثلا بیشتر از 80 درصد هست، از آدابوست نمی توانیم برای برای تقویت چنین مدلی استفاده کنیم.
تکنیک آدابوست زمانی خوب عمل میکنه که مدل پایه، یک مدل ضعیف در مقابل مسئله باشه. یعنی دقتی یه مقدار بیشتر از حالت شانسی داشته باشه.
- ایرادی که آدابوست داره اینه که احتمال overfitting بالایی دارد! پس باید احتیاط کرد.
- یکی از کارهایی که برای جلوگیری از overfitting میتواند کرد اینه که تعداد مدلهای پایه را کم در نظر گرفت.
- در آدابوست محدودیتی برای انتخاب نوع مدل پایه نداریم، ولی بهتر است مدلهای خطی برای اینکار استفاده شود تا خود مدل هم به تنهایی پتانسیل overfitting کمی داشته باشد.
- یا اگر مجبور هستیم از مدلهای غیرخطی به عنوان مدل پایه در آدابوست استفاده کنیم، بهتر است که خود مدل را محدود کنیم تا تقریبا حالت خطی عمل کنه. مثلا اگر من قرار باشه از طبقه بند درختی به عنوان مدل پایه در آدابوست استفاده کنم، تعداد شاخه های طبقه بند درختی را کم در نظر میگیرم.
- مدل هر چقدر ساده تر باشه بهتره.
- یک نکته مهم دیگه اینکه سعی کنید در پروژه هایی که تعداد داده ها کم هست سمت آدابوست نروید. چون در داده های تعداد پایین احتمال overfitting زیاد هست.
- حتما قبل از استفاده در عمل از یک روش مناسب برای ارزیابی آن استفاده کنید.
اگر علاقه مند به یادگیری تخصصی مباحث یادگیری جمعی هستید پیشنهاد میکنیم که فصل یادگیری جمعی دوره جامع و تخصصی شناسایی الگو-یادگیری ماشین را تهیه کنید. مباحث این فصل براساس چندین مرجع تخصصی آماده شده است. در این دوره تئوری و رویکرد تکنیکهای یادگیری جمعی از پایه آموزش داده شده و سپس مرحله به مرحله پیاده سازی شده و در پروژه های عملی طبقه بندی و رگرسیون استفاده شده اند.
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)
[…] باشید که در زمانی که تعداد نمونه های شما کم هست به سمت تکنیک آدابوست نروید! دلیلش رو شما […]