
مطالعات فرسایشی یا Ablation studies در هوش مصنوعی
- دسته:اخبار علمی
- هما کاشفی
مطالعات فرسایشی به طور سیستماتیکی سعی میکنند که بخشهایی از یک سیستم را حذف کنند، تا شناسایی کنند که عملکرد اصلی مدل دقیقاً از کجا میآید. اگر شما بدانید که X+Y+Z نتایج خوبی میدهد، X, Y, Z, X+Y, X+Z و Y+Z را هم امتحان کنید تا ببینید چه رخ میدهد. اگر محقق یادگیری عمیق شدید، مطالعات فرسایشی برای مدلهای خود انجام دهید. همیشه بپرسید، آیا ممکن است توضیح سادهتری وجود داشته باشد؟ آیا این پیچیدگی که اضافه شده است، واقعا نیاز است؟ چرا؟ در این پست، در مورد مطالعات فرسایشی در هوش مصنوعی، مطالعات یادگیری ماشین و یادگیری عمیق صحبت میکنیم و لزوم آن را مورد بررسی قرار میدهیم.
معنی اصلی “Ablation” برداشتن بافت بدن با جراحی است. اصطلاح «Ablation study» ریشه در زمینه عصب روانشناسی تجربی در دهههای 1960 و 1970 دارد که بخشهایی از مغز حیوانات برداشته میشد تا تأثیر این امر بر رفتار آنها بررسی شود.
در حوزهی یادگیری ماشین و به ویژه شبکههای عصبی عمیق پیچیده، «مطالعه فرسایشی» برای توصیف روشی استفاده میشود که در آن بخشهایی از شبکه حذف میشود تا درک بهتری از رفتار شبکه حاصل شود.
این اصطلاح پس از توئیت Francois Chollet نویسنده اصلی فریم ورک یادگیری عمیق در ژوئن 2018 مورد توجه قرار گرفت:

«مطالعات فرسایشی برای پژوهشهای یادگیری عمیق بسیار مهم هستند. سرراست ترین روش برای تولید دانش قابل اعتماد، درک روابط علت و معلول در سیستم شماست (که هدف پژوهش همین است). و مطالعهی فرسایشی روشی است که با تلاش بسیار کم به روابط علت و معلولی دست یافت. اگر با مدل آزمایشی یادگیری عمیق کار میکنید، به احتمال زیاد میتوانید چند ماژول را حذف کنید (یا برخی از ویژگیهای آموزش دیده را با ویژگیهای تصادفی جایگزین کنید) بدون اینکه تغییری در عملکرد مدل ببینید.
برای آنکه از شر نویزهای زیاد در فرآیند پژوهش خلاص شوید: مطالعات فرسایشی انجام دهید.
نمیتوانید سیستم خود را به طور کامل درک کنید؟ آیا میخواهید مطمئن شوید که کارکرد مدل واقعاً با فرضیه شما مرتبط است؟ سعی کنید بخشهایی را حذف کنید. حداقل 10% از زمان آزمایش خود را صرف تلاش صادقانه برای رد تز خود کنید!»
به عنوان مثال Girshick و همکارانش (2014) سیستم object detectionای را توصیف میکنند که از سه ماژول تشکیل شده است: ماژول اول، regionهایی از تصویر را پیشنهاد میکند که با استفاده از الگوریتم جستجوی انتخابی میتوان در آنها دنبال آبجکت بود و آبجکتهای بدست آمده را میتوان وارد یک شبکه عصبی کانولوشنی بزرگ کرد (با 5 لایهی کانولوشنی و 2 لایهی Fully Connected) که استخراج ویژگی را انجام میدهد و در نهایت به مجموعهای از ماشینهای بردار پشتیبان داده میشود تا کلاسبندی انجام دهد. برای درک بهتر سیستم، نویسندگان مطالعهی فرسایشی انجام دادند که در آن بخشهای مختلف سیستم حذف شده است-برای مثال یک یا دو لایهی fully connected از CNN حذف کردند و متوجه شدند که عملکرد به طرز شگفت انگیزی بدون تغییر باقی ماند

و باعث شد که نویسندگان اینطور نتیجه گیری کنند که بخش اعظمی از قدرت بازنمایی CNN از لایههای کانولوشنی ناشی میشود نه از لایههای fully connected
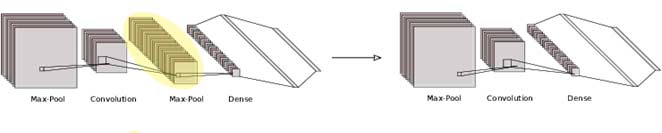
اگر میخواهید بدانید که چطور باید یک مطالعهی فرسایشی انجام داد، خیالتان راحت باشد «روش کلی که مناسب همهی مسائل باشد، وجود ندارد». بسته به کاربرد و انواع مدل، معیارها با هم متفاوت هستند. اگر مسئله را صرفاً به یک شبکه عصبی عمیق محدود کنیم، روش نسبتاً ساده آن است که لایهها را به شیوهای اصولی حذف کنیم و تغییر عملکرد شبکه را بررسی کنیم. اما فراتر از این مسائل، در عمل، مطالعهی فرسایشی در هر موقعیتی متفاوت است و در دنیای برنامههای پیچیده یادگیری ماشین، این بدان معناست که احتمالاً برای هر موقعیتی یک رویکرد منحصر به فرد نیاز است.
حال مسئلهای دیگر مثلا رگرسیون خطی را در نظر بگیرید-مطالعهی فرسایشی معنایی ندارد؛ زیرا تمام آن چیزی که میتوان از یک مدل رگرسیون خطی حذف کرد، تعدادی پیش بینی کننده است. انجام این کار به روش «اصولی» صرفاً یک روش انتخاب گام به گام معکوس است که عموماً مورد تردید قرار میگیرد. اما یک روش منظم سازی مانند Lasso، گزینهی بسیار بهتری برای رگرسیون خطی است.
Francois Chollet در کتاب “Deep Learning with Python” خود مینویسد:
«معماریهای یادگیری عمیق بیشتر به جای آنکه طراحی شده باشند، تکامل یافته هستند-آنها با آزمون و خطاهای تکراری ایجاد شدهاند و بررسی آنکه واقعاً چه چیزی به کار میآید. مشابه سیستمهای بیولوژیکی، اگر بخشی از مدلهای یادگیری عمیق تجربی پیچیده را حذف کنید، این شانس وجود دارد که هیچ تغییری در عملکرد مدل نبینید.
این مسئله زمانی بدتر میشود که محققان باانگیزهی یادگیری عمیق با آن روبرو میشوند: با ایجاد سیستمی پیچیدهتر از حد لزوم، شبکه آنها جالب و جدیدتر به نظر برسد و بنابراین شانس چاپ مقاله آنها بالا رود. اگر تعداد زیادی مقالات یادگیری عمیق را مطالعه کرده باشید، متوجه شده اید که آنها از نظر سبک و محتوا بهینه سازی شده اند به گونهای که به وضوح توضیحات و قابلیت اطمینان نتایج صدمه میزند. برای مثال در مقالات یادگیری عمیق، ریاضیات به ندرت استفاده میشود تا مفاهیم را به وضوح بیان کنند و یا نتایج غیرواضح را مشخص کنند، در حالیکه همین نبود ریاضیات میتواند علامت آن باشد که شاید فرضیهی مقاله، چندان هم جدی نیست.»
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دیدگاه ها