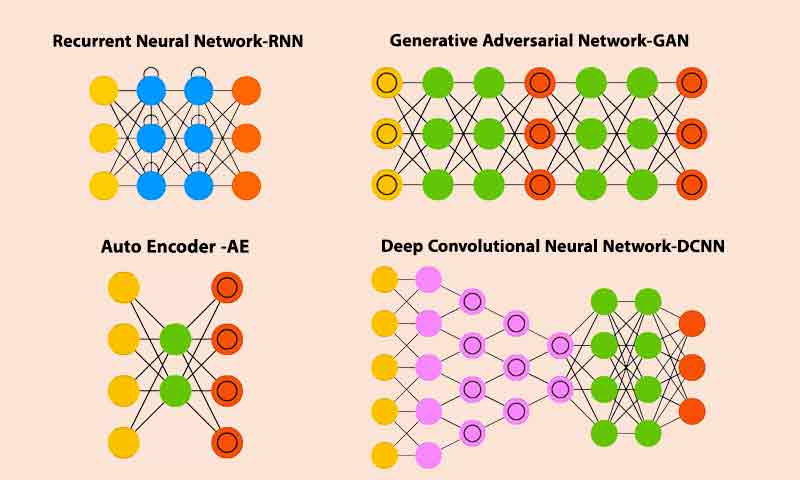
چهار تا از معروفترین شبکه های عمیق
- دسته:اخبار علمی
- هما کاشفی
در این مقاله به بررسی چهار مدل از الگوریتمهای عمیقی میپردازیم که عملکرد قابل توجهی در حل مسائل پیچیده داشتهاند. ابتدا هر نوع از این شبکههای عمیق را معرفی میکنیم، ساختار آنها را به طور مختصر شرح میدهیم و در نهایت مورد کاربرد آنها را برای حل مسائل متنوع بررسی میکنیم.
الگوریتمهای یادگیری عمیق در سالهای اخیر برای حل مسائل پیچیده بسیار موفق عمل کردهاند. هر نوع شبکهی عصبی عمیق برای تسک یا تسکهای خاصی مناسب است. البته میتوان یک نوع شبکه را برای تسکهایی دیگر نیز استفاده کرد و در این رابطه محدودیتی وجود ندارد.
الگوریتمهای یادگیری عمیق چطور کار میکنند؟
به طور کلی شبکههای عصبی مصنوعی (ANNs) از روشی که مغز اطلاعات را محاسبه میکند، استفاده میکنند. در طی فرآیند آموزش، الگوریتمها از المانهای ناشناخته در توزیع دادهی ورودی استفاده میکنند تا ویژگیها را استخراج کنند، اشیا را گروهبندی کنند و الگوهای مفید دادهای را کشف کنند. این فرآیند در چندین سطح رخ میدهد و در انتها، مدل نهایی ساخته میشود.
الگوریتمهای یادگیری عمیق که در این مقاله به آنها میپردازیم عبارتند از:
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Generative Adversarial Networks (GANs)
- Autoencoders (AEs)
1-Convolutional Neural Networks (CNNs)
شبکههای عصبی کانولوشنی که با نام اختصاری CNNها یا ConvNetها شناخته میشوند متشکل از چندین لایه هستند و بیشتر برای پردازش تصویر و تشخیص اشیا استفاده میشوند. آقای Yann LeCun اولین شبکه CNN را در سال 1988 با نام LeNet توسعه داد. این شبکه برای تشخیص ارقام دست نویس استفاده شد. CNNها به طور گستردهای برای شناسایی تصاویر ماهوارهای، پردازش تصاویر پزشکی، پیش بینی سریهای زمانی و تشخیص ناهنجاری استفاده میشوند. شبکههای CNN چندین لایه دارند که وظیفهی آنها پردازش و استخراج مهمترین و تفکیک کنندهترین ویژگیها از داده است. اولین لایهی مهم این شبکهها Convolution Layer است که چندین فیلتر برای انجام عملیات کانولوشن دارد. لایهی مهم بعدی Pooling Layer است. وظیفهی اصلی این لایه کاهش ابعاد ویژگیهای استخراج شده از داده است و در واقع نوعی down-sampling روی داده انجام میشود. لایهی نهایی Fully Connected Layer است که دادههای کلاسهای مختلف را شناسایی و کلاسبندی میکند.
2-Recurrent Neural Networks (RNN)
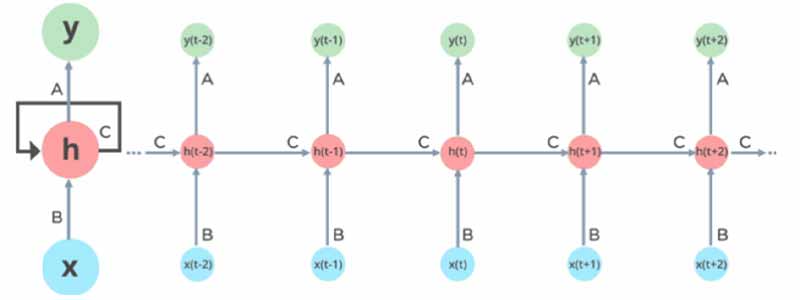
شبکههای عصبی بازگشتی یا RNNها برای دادههایی به کار میروند که نوعی توالی در دادهی ورودی وجود دارد و دادهی ورودی در زمان t به دادههای زمانهای t-1, t-2, … بستگی دارد. این شبکهها بر اساس این اصل کار میکنند که خروجی یک لایه را ذخیره میکنند و آن را به عنوان بخشی از ورودی به لایهی بعدی میدهند.
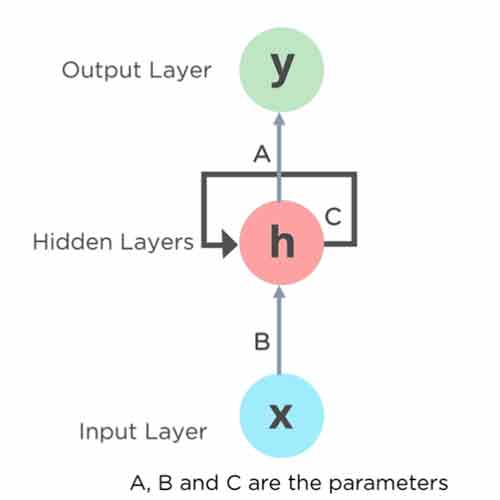
در این شبکهها x لایهی ورودی است، h لایهی پنهان است و y هم لایهی خروجی است. در زمان t، ورودی جاری ترکیبی از ورودی در x(t) و x(t-1) است. لایهی ورودی ‘x’ ورودی شبکه عصبی را میگیرد و آن را پردازش میکند و به لایهی پنهان h میدهد. لایهی پنهان ‘h’ ممکن است متشکل از چندین لایه پنهان باشد که هر کدام توابع فعالسازی و وزن و بایاس خود را دارند. در واقع در این شبکهها پارامترهای متنوع لایههای پنهان تحت تأثیر لایهی قبلی قرار میگیرند و به این ترتیب میتوان گفت که شبکه دارای حافظه است.
3- Generative Adversarial Networks (GANs)
شبکههای مولد تخاصمی (😐!) یا GANها از الگوریتمهای یادگیری عمیقی هستند که نمونه دادههای جدید شبیه به دادهی آموزشی تولید میکنند. GANها دو جز مهم دارند: یک مولد (Generator) که یاد میگیرد دادههای جعلی تولید کند و یک تفکیک کننده (Discriminator) که از اطلاعات نادرست یاد میگیرد که چطور دادهی اصلی را از دادهی جعلی تفکیک کند. تولید دادههای جعلی که بسیار شبیه به دادههای اصلی هستند که شاید در مواقعی تشخیص آنها برای ما به عنوان انسان نیز دشوار است، این شبکهها را به نوعی شبکههای رمزآلود تبدیل کرده است! 😊
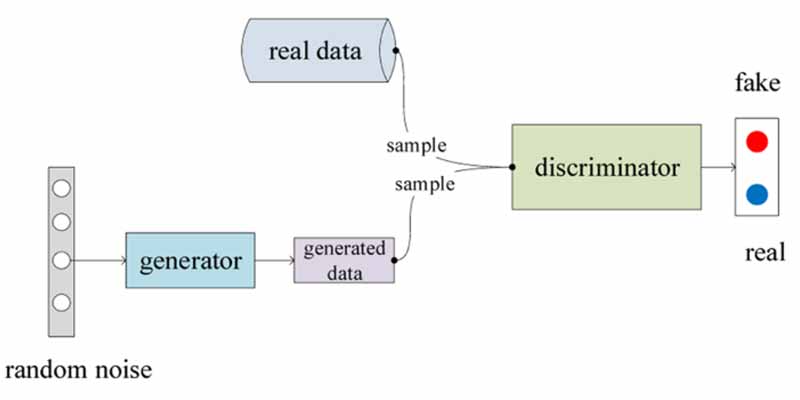
تصاویر زیر چهرههایی هستند که وجود خارجی ندارند و توسط شبکههای GAN تولید شدهاند 😊

4-Autoencoders (AEs)
شبکههای خودرمزنگار یا AEها نوعی از شبکههای عصبی feedforward هستند که در آنها ورودی و خروجی یکسان است. اولین بار این شبکه توسط جفری هینتون در دهه 1980 برای حل مسائل یادگیری بدون نظارت ارائه شد. AEها برای مسائلی چون پیش بینی محبوبیت و یا پردازش تصویر استفاده میشوند.
یک شبکهی خودرمزنگار از سه جز اصلی تشکیل شده است:
- رمزگذار (encoder)
- کد (code)
- رمزگشا (decoder)
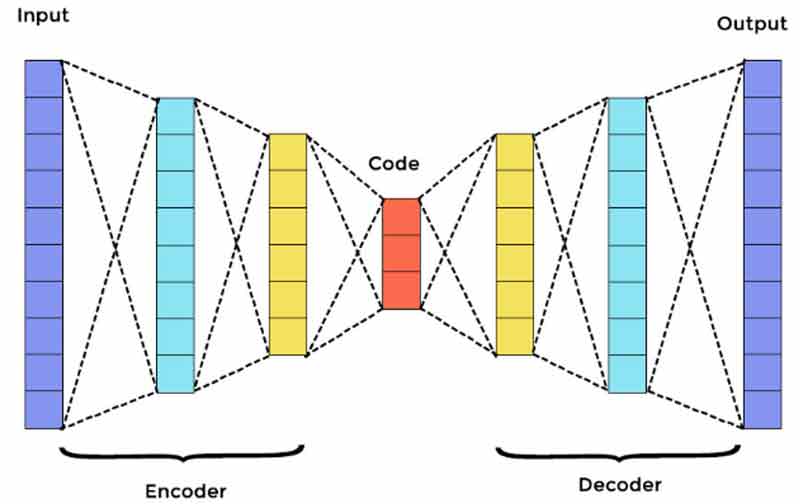
این شبکهها ورودی را میگیرند و بازنمایی دیگری از آن تولید میکنند. این شبکهها سعی میکنند که دادهی ورودی اصلی را تا حد ممکن با دقت بالا بازسازی کنند. زمانی که یک رقم به وضوح قابل مشاهده نیست میتوان آن را به یک شبکه عصبی AE تزریق کرد. AE ابتدا تصویر را رمزگذاری میکند و سپس سایز ورودی را کمی کاهش میدهد. در نهایت رمزگشا، تصویر را رمزگشایی میکند تا تصویر بازسازی شده را تولید کند.
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

عالی، متشکر بابت پست خوب
برای مباحث مربوط به پردازش سیگنال مغزی کدوم شبکه از شبکه های دیپ معرفی شده بهتره؟
اکثر شبکه ها رو میشه استفاده کرد. مهم اینه که به چه شکل از اون شبکه برای حل مسئله کمک بگیرید. برای این موضوع به زودی دوره تخصصی خواهیم داشت و مفصل این مسئله رو بررسی خواهیم کرد