
چرا ماشین بردار پشتیبان (SVM) در بین طبقهبندها جزء بهترینا هست؟
ماشین بردار پشتیبان(svm) یکی از معروفترین الگوریتمها در مسائل طبقهبندی هست که برای اولین بار توسط آقای Vladimir Vapnik در سال 1995 با عنوان support vectors networks مطرح شد. SVM در ابتدا برای مسائل طبقهبندی دو کلاسه خطی مطرح شده بود که بعدا برای مسائل چندکلاسه، مسائل غیرخطی ، مسائل رگرسیون و حتی مسائل خوشهبندی تعمیم داده شد. از این رویکرد استقبال بی نظیری شده و جز مقالاتی هست citation خیلی بالایی دارد.
در این بخش میخواهیم علت محبوبیت الگوریتم ماشین بردار پشتیبان(SVM) را بررسی کنیم.در شکل زیر میزان سایتشن مقاله support vector networks که ما با عنوان support vector machine میشناسیم نشان داده شده است. تا به امروز 46392 این مقاله را cite کردهاند.

خب بریم سراغ الگوریتم svm و ببنیم که این الگوریتم چه رویکردی دارد که این همه مورد توجه محقیق قرار گرفته است.
مسئله خطی تفکیک پذیر دو کلاسه
فرض کنید یک مسئله دو کلاسه داریم و میخواهیم مرز تفکیک کنندهی بین دو کلاس را پیدا کنیم:
به نظر شما بهترین مرز خطی که میتوان برای تفکیک دادههای دو کلاس پیدا کرد چی هست؟ مطئمنا مرزهای زیادی میتوان برای تفکیک دادههای دو گروه پیدا کرد. ولی سوال اینه که کدام مرز بهترین مرز هست؟
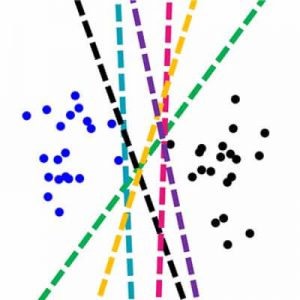
منظور از بهترین مرز این است که برای دادههای جدید هم خوب عمل کند. واقعیت اینه که ما در آموزش الگوریتمهای یادگیری ماشین به دادهی محدودی دسترسی داریم. مطمئنا اگر بی نهایت داده داشتیم راحتتر میتونستیم مرز تفکیک کننده بین دو گروه را پیدا کنیم. در این صورت دید بهتری به فضای ویژگی بدست می آوردیم و توزیع نمونههای هر گروه مشخص میشد، و راحت میتونسیتم مرزی انتخاب کمنیم که کمترین خطای طبقهبندی را داشته باشد.
ولی در عمل به دلایل مختلفی ما امکان ثبت داده زیادی نداریم و با یک دادهی محدودی سرو کار داریم و باید براساس دادهی محدودی که داریم مرز بهینه را بدست بیاوریم. و باید این مرز طوری بدست بیاد که در عمل بهتر کار کنه.
قدیمیا یه ضرب المثل خوبی دارند و میگن “مشت نمونه خروار است” . خب داده ای که ما در دسترسی داریم جزئی از دادهی جمعیت اصلی است و قرار نیست این داده در یک فضای ویژگی متفاوتی قرار بگیرد. پس ما اگر بتوانیم روی این داده محدود مرز مناسبی بدست بیاوریم در داده جمعیت هم خوب عمل خواهد کرد.
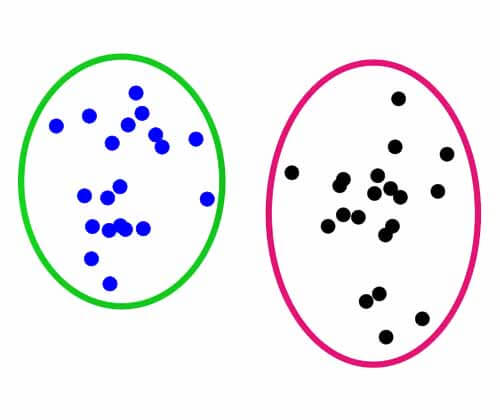
خب برای اینکه مرز تفکیک کننده در داده محدود، برای داده جمعیت هم خوب کار کند بهتر است جایی قرار بگیرد که بیشترین فاصله را با نمونههای دو گروه محدود داشته باشد. تا بعدا در داده جمعیت که حتما یه مقدار تغییرات خواهیم داشت خطای حداقل ایجاد شود. مثل شکل زیر :

مرز تصمیمگیری
هدف الگوریتمهای یادگیری ماشین پیدا کردن مرز تفکیک کننده بین دو گروه هست. مثلا شبکه ی عصبی پرسپترون تک لایه با قانون یادگیری پرسپترون تنها دغدغه اش اینه که مرزی پیدا کند تا دو گروه را با دقت 100 درصد تفکیک کند. حالا کاری ندارد که این مرز برای داده جمعیت هم مناسب است یا نه!
که البته این قانون یادگیری مشکلات خاص خودش را دارد و ازش استفاده نمیکنند. و به جاش از قانون یادگیری lms یا همان حداقل مربعات خطا استفاده میکنند که توسط آقای وینر مطرح شده است. این قانون تا حدودی خوب هست و سعی میکنه مرز بهینه ای پیدا کند که حداقل خطا را داشته باشه و در عین حال در داده جمعیت هم خوب عمل کند.
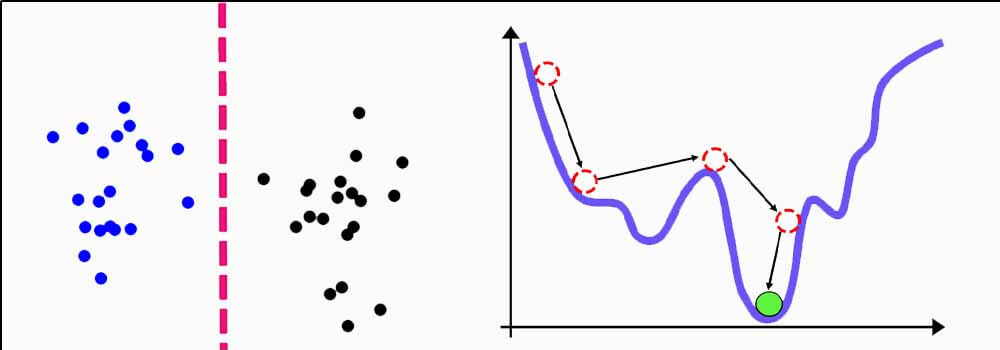
برای حل مسئله lms از گرادیان نزولی استفاده میکنند. این روش در طول تکرارهای مختلف مرز بهینه را پیدا میکند. به این صورت از یک جا شروع کرده و در جهت شیب منفی خطا حرکت میکند، و زمانی که شیب خطا صفر شد (خطای حداقل) پروسه آموزش متوقف شده و ادامه نمی یابد.
البته اگر خوششانش باشیم و الگوریتم در مینممهای محلی گیر نکند!
مرز تصمیمگیری ماشین بردار پشتیبان (svm )
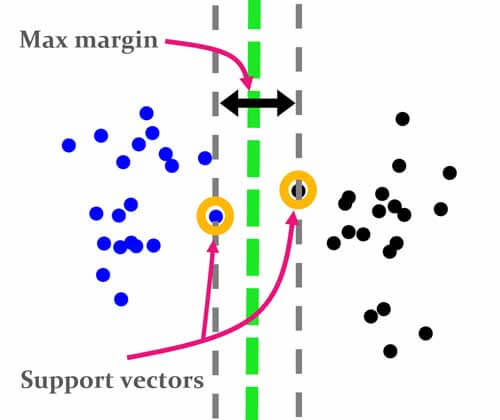
ماشین بردار پشتیبان ایدهای همانند رویکردی که صحبت کردیم دارد. هدفش اینه که مرزی پیدا کند که بیشتر فاصله را با نمونههای هر دو گروه داشته باشد. اساس این ایده همین هست و به طور واضح مشخص میکند که دنبال چه مرزی هست و روابط بهینه سازی را براین مبنا مینویسد.
در رویکرد وینر هم همین هدف هست منتهی در روابط بهینهسازی به این موضوع به طور مستقیم نمیپردازد. بهتر است بگوییم که LMS هم هدفش رسیدن به مرزی هست که از مرکز دو گروه عبور کند و بیشترین فاصله را با دادههای دو گروه داشته باشد ولی در برای اینکار هیچ جای روابط شرطی برای تابع هزینه در نظر نمیگیرد.
ولی Vapnik همان ابتدا شرط میگذاره که اگر قرار است مرزی بدست بیاید باید چنین شرطی رو قبول کنه.شرطش چی هست؟ شرطش اینه که اولا باید مرزی بدست بیاری که کمترین خطای طبقهبندی را داشته باشد، دوما اینکه این مرز باید جایی قرار بگیرد که بیشترین فاصله را با نمونههای هر گروه داشته باشد.
بردارهای پشتیبان (support vectors)
البته همه نمونهها مدنظر نیست، نزدیکترین نمونهها به مرز تفکیک کننده مدنظر است و مرز باید بیشترین فاصله را با این نمونهها داشته باشد. به این نمونهها بردارهای پشتیبان گفته می شود و از الگوریتم حمایت میکنند تا مرز تفکیک کننده را در جای بهتری قرار بدهد.
ویژگیهای شگفت انگیز ماشین بردار پشتیبان(svm)
- مهمترین ویژگی این الگوریتم اینه که بهترین مرز تفکیک کننده بین داده ها را پیدا میکند. و همین باعث میشود که الگوریتم خاصیت generalization خیلی خوبی داشته باشد و در داده های جدید هم خوب عمل کند!
- ویژگی دوم این الگوریتم که باعث شده خیلی از آن استقبال شود اینه که در ابعاد بالا هم خوب عمل میکند. در دنیای مدرن دادهها ابعاد بسیار بالایی دارند… و بزرگترین دغدغه اینه که الگوریتمها بتوانند در ابعاد بالا هم خوب عمل کنند ولی متاسفانه خیلی از روش ها مرسوم در ابعاد بالا دچار overfitting شده و اصلا خوب عمل نمیکنند. و از آنجا که svm برای پیدا کردن مرز تصمیمگیری از بردارهای پشتیبان استفاده میکند، باعث میشود که در ابعاد بالا هم خیلی خوب کار کند. و همین باعث شده که این همه svm مورد توجه محققین قرار بگیرد.
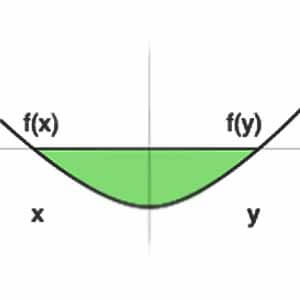
- ویژگی سوم svm اینه که رابطه بهینه سازی آن محدب (convex) هست! در مسائل بهینه سازی محدب مینیمم محلی وجود نداره و اگر مسئله جوابی داشته باشه، بهنیه ترین جواب مسئله است. به عبارتی در مسئله طبقه بندی، اگر مرزی برای تفکیک داده ها وجود داشته باشد، svm بهینه ترین مرز ممکن را پیدا میکند!
ولی در شبکههای عصبی از آنجا که مسئله بهینهسازی محدب نیست، تضیمنی بر رسیدن به بهینهترین جواب وجود ندارد! الگوریتمها تمام سعیشون اینه که به بهترین جواب برسند، ولی ضمانت نمیکنند چون ممکن است در مسیر همگرایی، در مینیممهای محلی گیر بکنند!
دوره های مرتبط

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

پکیج کامل پیادهسازی گام به گام شبکههای عصبی
شبکه عصبی آدالاین و قانون یادگیری lms (جلسه سوم)
پیاده سازی شبکه عصبی پرسپترون تک لایه (جلسه دوم)

دیدگاه ها