پارامترهای ارزیابی در مسائل رگرسیون و طبقه بندی
در طراحی و تعیین پارامترهای یک مدل یادگیری ماشین، روشها و پارامترهای ارزیابی نقش بسیار مهمی دارند. چرا که به ما کمک میکنند دید درستی به مدل طراحی شده داشته باشیم و متوجه بشویم که مدل یادگیری ماشین underfit ،overfit شده است یا نه. در مسائل طبقه بندی و رگرسیون برای ارزیابی مدل یادگیری ماشین پارامترهای ارزیابی مختلفی وجود دارد، در این پست میخواهیم با چند تا از پارامترهای ارزیابی مهم آشنا شویم.
فرایند انجام یک پروژه یادگیری ماشین نظارت شده
در یادگیری ماشین، مسائل رگرسیون و طبقه بندی جزء دسته نظارت شده است. یعنی در پروسه آموزش، مدل ورودی و خروجی را دریافت میکند و بعدش سعی میکند رابطه بین ورودی و خروجی را به نحوی پیدا کند که خطا (اختلاف خروجی تخمین زده شده با خروجی واقعی) حداقل باشد.
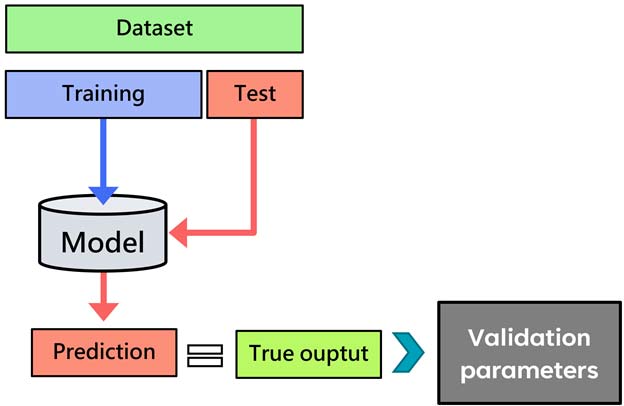
فرایند کار به این صورت هست که ما داده را طبق یکی از روشهای ارزیابی مثل the hold out method یا k-fold cross validation به دو بخش آموزش و تست تقسیم میکنیم.
سپس در پروسه آموزش مدل یادگیری ماشین، داده ورودی و خروجی (data_train, output_train) را به مدل ارائه میدهیم و مدل رابطه بین ورودی و خروجی (y= f(x)) را محاسبه میکند. به عبارتی مدل یاد میگیرد و متوجه می شود که چه ارتباطی بین ورودی و خروجی وجود دارد.
اما مسئله این است که نمیتوان به مدل به این راحتی اعتماد کرد! دلایل مختلفی دارد. برای مثال ممکن است مدل در مینیمم محلی (local minima) گیر کند و به اشتباه فکر کند که در مینیمم اصلی (global minima) همگرا شده است. یا ممکن است overfit شود!
برای همین ما همینطوری نمیتونیم مدل آموزش دیده را در عمل استفاده کنیم. چرا که ریسک بالایی دارد و ممکن است مدل درست عمل نکند و خسارت جبران ناپذیری ایجاد کند! مثلا تصمیم اشتباه در مورد بیماری یک فرد میتونه جان بیمار را به خطر بیاندازد. یا در یک کارخانه ای تصمیم اشتباه میتونه هزینه سنگینی به بار آورد!
پس چاره چیه!؟ خب راه حل اینه که مدل رو در شرایطی شبیه به شرایط واقعی قرار دهیم و عملکرد آن را بسنجیم. اگر مدل خوب عمل کرد میتونیم بهش امیدوار باشیم و اعتماد کنیم و در عمل استفاده کنیم.
شرایطی شبیه به شرایط واقعی یعنی عملکرد مدل را با داده ای بسنجیم که مدل تا الان آنرا مشاهده نکرده است! داده ای که در پروسه آموزش هیچ نقشی نداشته است! هیچ نقشی! چه در تخمین پارامترهای نرمالیزیشن یا تخمین مولفه های اساسی الگوریتم PCA یا استفاده در فرایند انتخاب ویژگی تا استفاده در پروسه آموزش الگوریتم یادگیری ماشین!
خلاصه کلام اینکه باید داده ای را برای تست مدل استفاده کنیم که در هیچ کدام از مراحل طراحی سیستم، اعم از انتخاب ویژگی، کاهش بعد، نرمالیزشین و آموزش الگوریتم یادگیری ماشین نقشی نداشته باشد.
برای همین، داده به دو بخش آموزش و تست تقسیم میشود، با کمک داده آموزش (داده ورودی و خروجی) سیستم طراحی شده (نرمالیزیشن، کاهش بعد، انتخاب ویژگی ووو) و الگوریتم یادگیری ماشین آموزش می بیند.
بعد از اینکه مدل آموزش دید، داده تست (فقط ورودی)، داده ای که هیچ نقشی در فرایند آموزش سیستم نداشته است، به مدل یادگیری ماشین ارائه میشود و مدل هم براساس دانشی که در پروسه آموزش بدست آورده، برای داده تست، خروجیای تخمین می زند. این خروجی های تخمین زده شده با خروجی های واقعی داده تست مقایسه شده و پارامترهای ارزیابی محاسبه میشود. این پارامترها مشخص میکنند که مدل تا چه میزان خوب عمل میکند و آیا میتوان این مدل را در عمل استفاده کرد یا نه!
پارامترهای ارزیابی در مسائل طبقه بندی و رگرسیون
همانطور که میدانیم خروجی مسائل طبقه بندی و رگرسیون باهم تفاوت دارند. در گرسیون خروجی ها مقادیری پیوسته ولی در طبقه بندی مقادیری گسسته هستند. برای همین، برای هرکدام از مسائل، پارامترهای ارزیابی متفاوتی استفاده می شود. در ادامه با چند تا از پارامترهای رایج ارزیابی برای هر دو مسئله آشنا می شویم.
پارارمترهای ارزیابی در مسائل طبقه بندی
برای اینکه درک بهتری از مفاهیم داشته باشیم، با یک مثال ساده پارامترها را توضیح میدهیم. فرض کنید، خروجی واقعی و تست در یک مسئله ای به به شکل زیر بوده است. حال میخواهیم با مقایسه این دو متوجه بشویم که مدل چقدر خوب عمل کرده است.

همانطور که می بینیم، یک مسئله دو کلاسه است و در مجموع 12 نمونه تست وجود داشته که 6 تا از آنها برای کلاس یک و 6 تا برای کلاس دو بوده است. با مقایسه این دو خروجی متوجه میشویم که مدل از 12 نمونه 9 تا را درست تخمین زده است. 4 تا از گروه اول و 5 تا از گروه دوم را درست تخمین زده است.
اگر فرض کنیم، یک مسئله دو کلاسه (بیمار/positive – سالم/negative) بوده است. حال به سوالات زیر جواب بدهید؟
- چند نفر از گروه positive(0) را مدل به درستی positive(0) تخمین زده است؟ (True Positive)
- چند نفر از گروه negative(1) را مدل به درستی negative(1) تخمین زده است؟ (True Negative)
- چند نفر از گروه positive(0) را مدل به اشتباه negative(1) تخمین زده است؟ (False Negative)
- چند نفر از گروه negative(1) را مدل به درستی positive(0)تخمین زده است؟ (False Positive)
اینها اصطلاحاتی است که از پزشکی وارد مباحث یادگیری ماشین شده است. و مسئله اینه که ما همیشه مسائل بیمار-سالم نداریم ولی خب همچنان در مسائل دو کلاسه میبینیم که در مقالات عملکرد مدلها را به این شکل گزارش میدهند. پس بهتره ماهم دقیقا بدانیم چه معنایی دارند.
- TP مشخص میکند که چند نفر از گروه positive(0) را مدل به درستی positive(0) تخمین زده است.
- TN مشخص میکند چند نفر از گروه negative(1) را مدل به درستی negative(1) تخمین زده است.
- FN مشخص میکند چند نفر از گروه positive(0) را مدل به اشتباه negative(1) تخمین زده است.
- FP مشخص میکند چند نفر از گروه negative(1) را مدل به درستی positive(0)تخمین زده است.
تصویر فان زیر به خوبی تفاوت بین FN و FP را نشان میدهد.

ماتریس درهمریختگی/کانفیوژن (confusion matrix)
ماتریس کانفیوژن یک ماتریس مربعی هست که از روی خروجی واقعی و تخمین زده شده محاسبه می شود و تمامی اطلاعات مربوط به تعداد تخمین های درست یا اشتباه هر کلاس داخل آن وجود دارد.
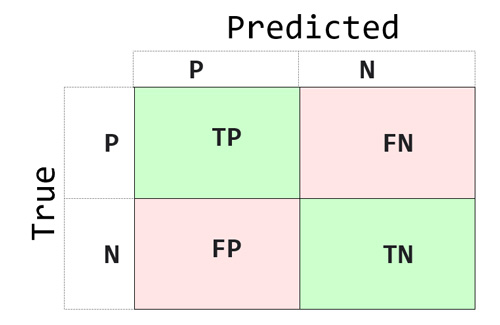
از این روی این ماتریسی میتوان متوجه شده که مدل از هر گروه چه تعداد رو اشتباه و چه تعداد را درست تخمین زده است. برای مثال در مثال ما ماتریس کانفیوژین به شکل زیر خواهد بود.
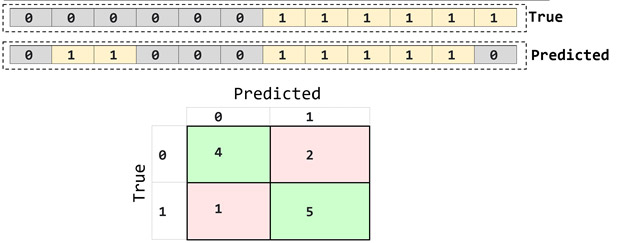
میتوان با بررسی ماتریس کانفیوژن متوجه شد که مدل ما از 6 داده تست گروه 0، 4 تا نمونه را به درستی گروه 0 تخمین زده و 2 تا نمونه را به اشتباه گروه 1 تخمین زده است. و از 6 داده تست گروه 1، 5 تا نمونه را به درستی گروه 1 تخمین زده و 1 تا نمونه را به اشتباه گروه 0 تخمین زده است.
ما از روی این مقادیر میتوان پارمترهای ارزیابی مثل accuracy، sensitivity، specificity و سایر پارامترهای ارزیابی ار محاسبه کرد.
Accuracy مشخص میکند که مدل خروجی چند درصد از کل داده های تست را به درستی تخمین زده است. این معیار ارزیابی به شکل زیر محاسبه میشود.

که در مثال ما برابر است با:
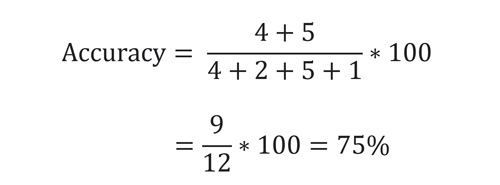
Sensitivity مشخص میکند که مدل خروجی چند درصد از کل داده های تست کلاس یک را به درستی تخمین زده است. به عبارتی مشخص میکند که مدل چند درصد از افراد بیمار (positive) را به درستی بیمار(positive) تشخیص داده است. این معیار ارزیابی به شکل زیر محاسبه میشود.

که در مثال ما برابر است با:
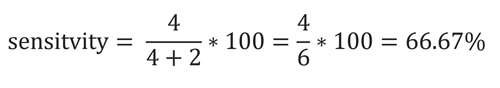
specificity مشخص میکند که مدل خروجی چند درصد از کل داده های تست کلاس 2 را به درستی تخمین زده است. به عبارتی مشخص میکند که مدل چند درصد از افراد سالم (negative) را به درستی بیمار تشخیص نداده است یا به عبارتی به درستی سالم(negative) تشخیص داده است. این معیار ارزیابی به شکل زیر محاسبه میشود.

که در مثال ما برابر است با:
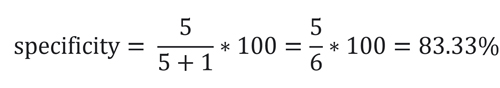
پارامترهای زیادی وجود دارد که میتوان به راحتی آنها را هم از روی ماتریس کانفیوژن محاسبه کرد. کافیه که رابطه آنها را داشته باشیم تا طبق رابطه از روی ماتریس کانفیوژن محاسبه کنیم.
در پایتون میتونید این پارامترها را با کمک کتابخانه sklearn به راحتی محاسبه کنید. برای مثال طبق روال زیر به راحتی میتوان محاسبه ماتریس کانفیوژن را محاسبه کرد.
Python
from sklearn.metrics import confusion_matrix C= confusion_matrix(ytrue,ypred)
پارارمترهای ارزیابی در مسائل رگرسیون
در مسائل رگرسیون پارامترهای زیادی مطرح شده است که چند تا از آنها را در ادامه معرفی میکنیم. به طور کلی در مسائل رگرسیون میتوان به شکل ارزیابی را انجام داد.
- ارزیابی شهودی-کیفی: با رسم شکل خروجی تخمین زده شده همراه با خروجی واقعی، میزان شباهت دو خروجی را به تصویر میکشیم.
- ارزیابی کمی: پارامترهایی را از مقایسه دو خروجی محاسبه میکنیم و به صورت عددی عملکرد مدل یادگیری ماشین را مشخص میکنیم.
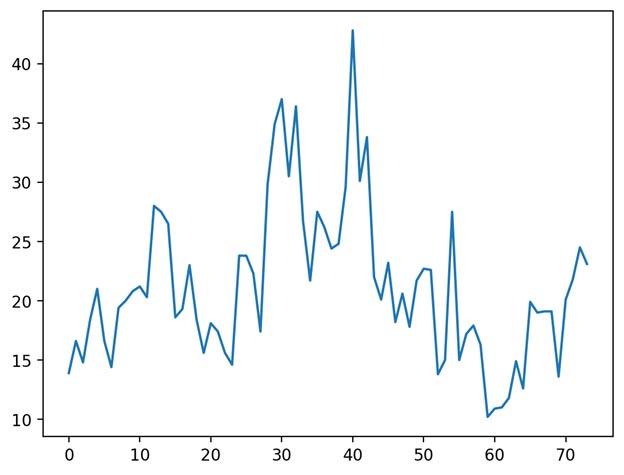
باز برای اینکه درک بهتری از پارامترها داشته باشیم، فرض کنید خروجی واقعی به شکل زیر است:
معیار ارزیابی MSE
همانطور که از اسم میانگین مربعات خطا مشخص است، اختلاف دو خروجی را محاسبه کرده و سپس این اختلاف را به توان دو رسانده و میانگین میگیرد. دلیل به توان دو رساندن این است که خطاهای مثبت یا منفی اثر همدیگر را خنثی نکنند. MSE طبق رابطه زیر محاسبه میشود:
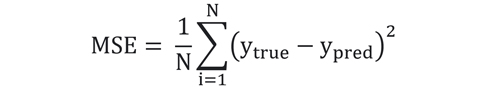
N تعداد نمونه های تست را مشخص میکند.
هرچقدر MSE به صفر نزدیک باشد، به این معنی است که خوب عمل کرده و اختلاف بین خروجی تخمین زده شده و خروجی واقعی بسیار کم است. و هرچقدر بیشتر یعنی بدتر. حداکثر MSE برابر است با توان 2 ماکزیمم رنج تغییرات در خروجی واقعی.
Python
from sklearn.metrics import mean_squared_error MSE = mean_squared_error(ytrue, ypred)
MAE: میانگین قدرمطلق خطا، همانطور که از اسمش مشخص است، اختلاف دو خروجی را محاسبه کرده و سپس از این اختلاف قدرمطلق گرفته و سپس میانگین میگیرد. دلیل به توان قدرمطلق این است که خطاهای مثبت یا منفی اثر همدیگر را خنثی نکنند. MAE طبق رابطه زیر محاسبه میشود:
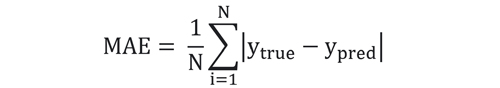
هرچقدر MAE به صفر نزدیک باشد، به این معنی است که خوب عمل کرده و اختلاف بین خروجی تخمین زده شده و خروجی واقعی بسیار کم است. و هرچقدر بیشتر یعنی بدتر. حداکثر MAE برابر است با ماکزیمم رنج تغییرات در خروجی واقعی.
Python
from sklearn.metrics import mean_absolute_error MAE = mean_absolute_error(ytrue, ypred)
معیار ارزیابی R Square
مسئله ای که دو پارامتر MSE, MAE دارند اینه که علارغم اینکه دید بهتری به ما نسبت عملکرد مدل ارائه میدهند، اما رنج مشخصی ندارند و بسته به هر مسئله ای متفاوت خواهند بود. برای مثال اگر در یک مسئله ای MAE=10 و در مسئله دیگه ای MAE=5 باشد، میتوان همینطوری گفت که در مسئله دوم مدل بهتر عمل کرده است؟؟
خب نمیتوان گفت. باید رنج تغییرات در هر دو مسئله را بررسی کرد. بعد اگر در هر دو مسئله رنج تغییرات یکسان بود، اونوقت میتوان گفت که مدل در مسئله دوم بهتر عمل کرده است. اما اگر رنج تغییرات در مسئله اول مثلا 100 بود، و دومی 10 بوده، میتوان به وضوع گفت که مدل در مسئله اول خیلی بهتر از دومی عمل کرده است، علارغم اینکه MAE در مسئله دوم کم است.
چیزی که در تلاشم بگم اینه که این پارامترها رنج مشخصی ندارند که راحت با نگاه اول متوجه شد که مدل خوب عمل کرده یا نه. اما پارامتری به اسم R2 هست که این بین صفر و یک است. این پارامتر طبق رابطه زیر محاسبه میشود:
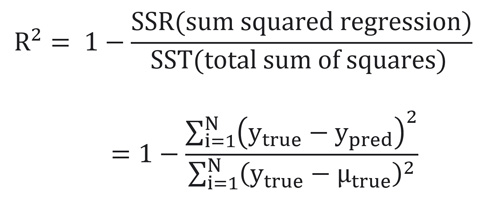
Python
from sklearn.metrics import r2_score r2= r2_score (ytrue, ypred)
اگر اختلاف بین خروجی تخمین زده شده حداقل باشد، در نتیجه R2 نزدیک به یک خواهد بود. و اگر دو خروجی هیچ ربطی به هم نداشته باشند R2 صفر خواهد بود! در شکل زیر به خوبی این مفهوم را میرساند.
با این معیار در هر مسئله میتوانیم راحت تر نتایج را بررسی کنیم. با این حال هر معیاری مزایا و معایب خودش را دارد و وقت به یک معیار نمیتوان اکتفا کرد.
حال بیایید در مثال خودمون این معیارها را محاسبه کنیم:
مقایسه شهودی(حالت اول): رسم خروجی واقعی و خروجی تخمین زده شده کنار هم
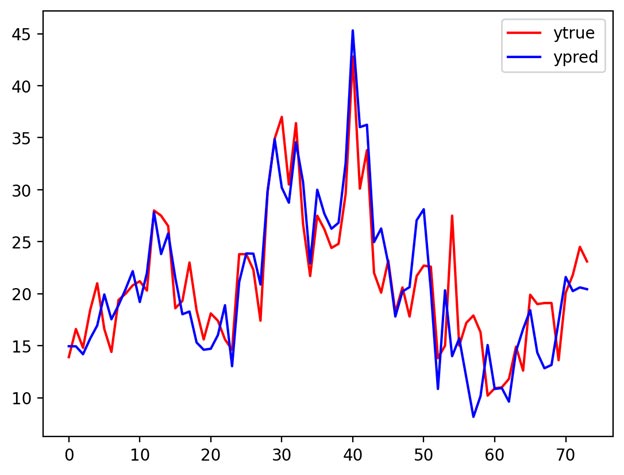
مقایسه شهودی(حالت دوم): رسم مقادیر خروجی واقعی نسبت به مقادیر خروجی تخمین زده شده
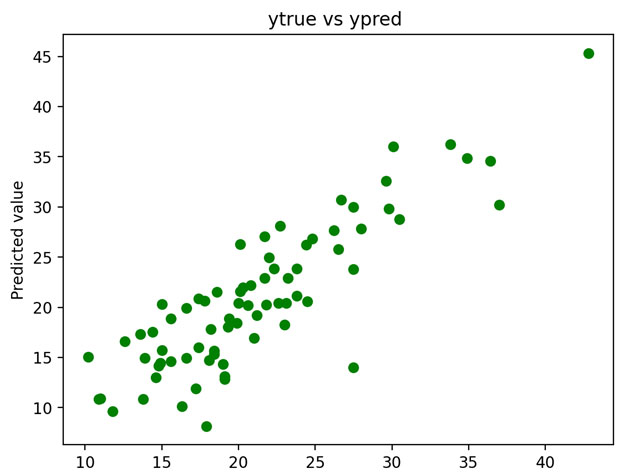
پارارمترهای کمی
MSE : 13.368 MAE : 2.810 R Squared : 0.680
R2 نشان میدهد که حدودا 68 درصد مقادیر تخمین زده شده همانند مقادیر واقعی هستند.
در دوره تخصصی پایتورچ به صورت تخصصی به این مباحث می پردازیم!
ما در دوره پایتورچ سه هدف اصلی داریم:
- یادگیری تئوری ریاضیات شبکه های عصبی و روشهای بهینه سازی
- یادگیری کار با ابزار پایتورچ به صورت تخصصی
- ساخت dataloader ها اختصاصی برای داده های خودمان
- پیادهسازی شبکه های عصبی با ابزار پایتورچ
- انجام پروژه های عملی
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
بسیار مختصر و مفید ممنون از سایت خوبتون
ممنون از توجه شما