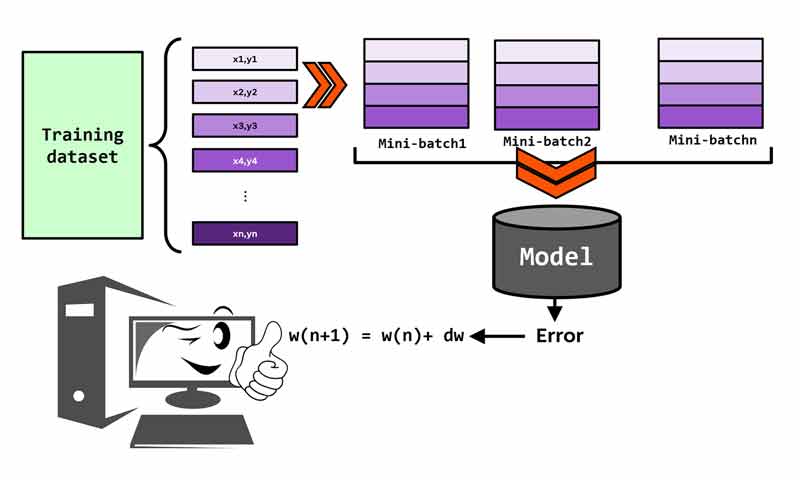
حالت های ارائه داده آموزشی به شبکه های عصبی (pattern, mini-batch, batch-mode)
در آموزش شبکه های عصبی، داده های آموزش را میتوان به سه شکل pattern mode, batch-mode و mini-batch به شبکه عصبی ارائه داد. هرکدام از این حالتها مزایا و معایب خودشون را دارند. در این پست میخواهیم با هر سه حالت آموزش شبکه عصبی و مزایا و معایب آنها آشنا شویم و در آخر هم بررسی میکنیم که batch-size را چند در نظر بگیریم بهتر است و داستان عدد جادویی 32 چیه؟
شبکه عصبی
شبکه های عصبی از مجموعه ای نورونهای عصبی مصنوعی تشکیل شده اند که این نوورنها از طریق گرههای سیناپسی بهم وصل شده اند تا یک مسئله خاصی را حل کنند. هر کدام از این گره های سیناپسی یک وزنی دارند که مناسب با مسئله مورد نظر تنظیم میشوند. دانش شبکه عصبی در بین این وزنهای سیناپسی نهفته است و شبکه این دانش را در پروسه آموزش از روی داده آموزش بدست می آورد.
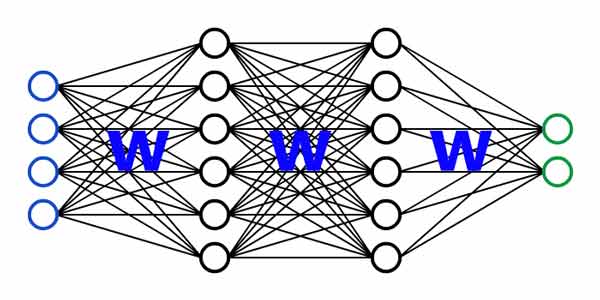
آموزش شبکه عصبی
برای اینکه شبکه عصبی بتواند مسئله ای را حل کند، اول باید وزنهای سیناپسی خود را با کمک داده آموزشی تنظیم کند. روال کار به این صورت است که شبکه عصبی با یک وزن اولیه ی تصادفی شروع میکند و در طول زمان وزنهای خود در جهت کاهش خطای تصمیم گیری تغییر میدهد تا به وزنهای بهینه ای برسد که حداقل خطای ممکن حاصل شود.
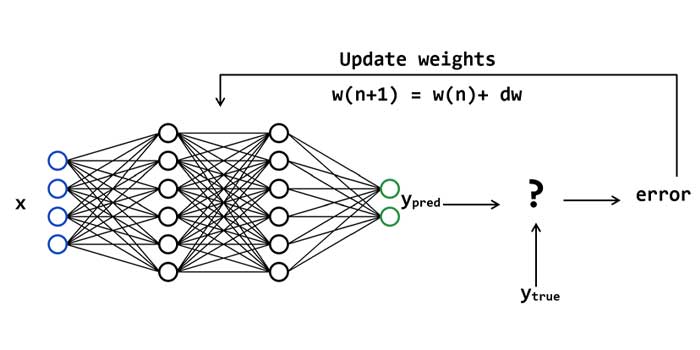
در پروسه آموزش شبکه های عصبی نظارت شده، داده وارد شبکه عصبی شده و ضربدر وزنهای سیناپسی لایه ها شده و بعد از عبور از همه لایه ها، خروجی هر داده محاسبه میشود، این خروجی تخمین زده شده توسط شبکه عصبی با خروجی واقعی مقایسه میشود و خطا محاسبه می شود. شبکه وزنهای خود را در جهت کاهش خطا تنظیم میکند. این پروسه تا زمانی که شبکه عصبی به وزنهای سیناپسی بهینه ای نرسیده است ادامه میابد.
بعد از اینکه شبکه عصبی آموزش دید، وزنهای سیناپسی فیکس می شوند و دیگر تنظیم نمی شوند. و از این به بعد میتوان از شبکه عصبی برای تخمین خروجی داده های جدید استفاده کرد. به این تریتب که داده جدید وارد شبکه عصبی میشه، و شبکه عصبی طبق دانشی که در پروسه آموزش بدست آورده (وزنهای سیناپسی نهایی) خروجی داده را تخمین میزند.
حلقه آموزش
فرض کنید ما در یک مسئله ای n تا نمونه ی آموزشی داریم و قرار است با این نمونه های شبکه عصبی را آموزش دهیم. هدف این است که شبکه عصبی رابطه ی بین ورودی و خروجی (y= f(x) ) را محاسبه کند.
خب مسئله این است که آیا با یکبار ارائه این نمونه ها به شبکه عصبی، شبکه عصبی یاد میگیرد؟؟ یا به عبارتی رابطه بین ورودی و خروجی را به درستی محاسبه میکند؟؟
البته که نه! شبکه عصبی برای اینکه دانش کافی بدست بیاورد، باید نمونه های آموزشی را چندین بار مشاهده کند. برای همین نیاز به حلقه آموزش داریم.
به هر تکرار ارائه نمونه های آموزشی به شبکه عصبی یک epoch گفته می شود. و به این فرایند ارائه نمونه ها به شبکه عصبی حلقه آموزش گفته می شود.
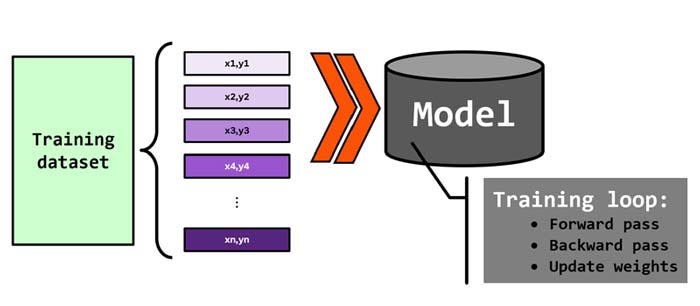
در هر تکرار حلقه آموزش، تمام نمونه ها هر کدام یکبار به شبکه عصبی ارائه میشوند و شبکه عصبی با وزنهای اون لحظه خروجی آنها را تخمین میزند و به یک خطایی میرسد. وزنهای شبکه عصبی طبق خطا تنظیم می شوند و مجددا در تکرار بعدی، داده های آموزش به شبکه عصبی ارائه میشوند و این پروسه چندین بار تکرار میشود تا شبکه عصبی بتواند به وزنهای سیناپسی بهینه جهت حل مسئله دست یابد.
اما مسئله این است که در هر تکرار آموزش، داده های آموزش به چه صورت به شبکه عصبی ارائه شوند. سه حالت برای ارائه نمونه های آموزش به شبکه عصبی وجود دارد که در ادامه با هر کدام از آنها آشنا می شویم.
ارائه داده های آموزشی به شبکه عصبی به صورت pattern mode
در حالت pattern mode، در هر تکرار آموزش، داده های یکی یکی وارد شبکه عصبی می شوند و شبکه عصبی خروجی هر داده را محاسبه میکند، سپس به ازای هر نمونه ی آموزشی خطای شبکه محاسبه می شود و وزنهای سیناپسی شبکه طبق خطا محاسبه می شود. یعنی در هر تکرار آموزش، وزنهای سناپسی nبار تنظیم می شوند (چرا که n تا نمونه ی آموزشی داریم)
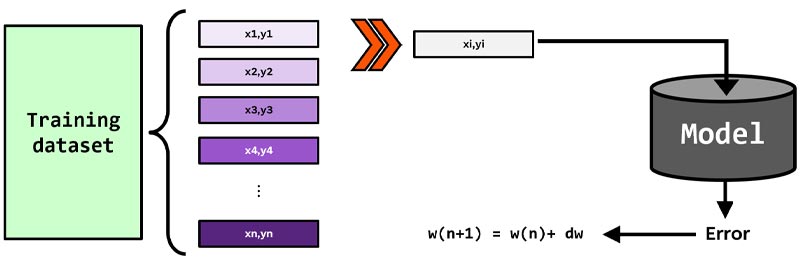
Python
epoch=50 for iter in range(epoch): for i in range(datatrain.size(0)): xi,di= datatrain[[i]],ytrain[i] # predict output ypred=NeuralNetwor(w,xi) # calculate error ei= di-ypred # update weights w= w+dw
هر داده ی آموزشی میتواند در بین نمونه ها، یک تعدادی نمونه های نویزی داشته باشد. این نمونه های در طول تکرارهای آموزش همانند یک ترم رگوله سازی عمل کرده و احتمال overfitting شبکه را کاهش می دهند و این باعث افزایش خاصیت generalization شبکه عصبی می شود.
عیب pattern mode
عیب این روش این است که اگر تعداد داده آموزشی زیاد باشه، پروسه آموزش بسیار زمانبر خواهد بود و برای کارهای research اصلا چنین رویکردی نمیتواند بهینه باشد. چرا که در ابتدای کار ما ساختار و پارامترهای مناسب شبکه عصبی برای حل مسئله را نمیدانیم و لازم است به ازای ساختارهای و پارامترهای مختلف عملکرد شبکه عصبی را بررسی کنیم تا مقادیر مناسب را انتخاب کنیم. درسته که پروسه آموزش شبکه عصبی به صورت offline است ولی اگر پروسه آموزش زمانبر باشه فرصت مناسب برای بررسی حالتهای مختلف نخواهیم داشت!
ارائه داده های آموزشی به شبکه عصبی به صورت batch mode
برای حل مشکل زمانبر بودن pattern mode، batch mode ارائه شده است. در هر تکرار آموزش این رویکرد ، کل داده های آموزشی یکجاب به شبکه ارائه میشوند و شبکه خروجی همه آنها را براساس وزنی که در اون تکرار آموزش دارد تخمین میزند. سپس خطا محاسبه شده و وزنهای شبکه عصبی یکجا تنظیم می شوند. یعنی در هر تکرار آموزش، وزنها فقط یکبار تنظیم می شوند.
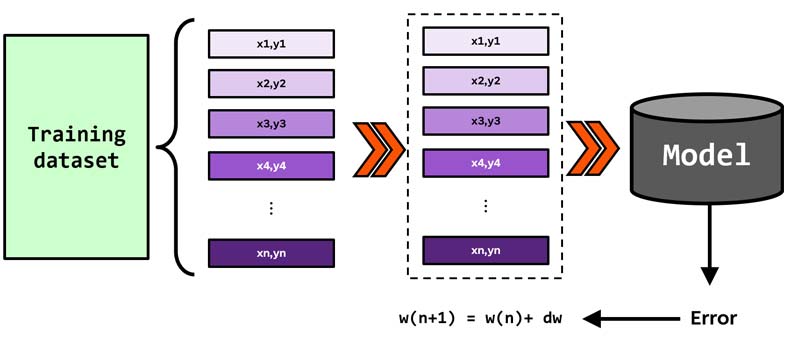
Python
epoch=50 for iter in range(epoch): X,Ytrue= datatain,ytrain # predict outputs Ypred=NeuralNetwor(w,X) # calculate errors e= Ytrue-Ypred # update weights w= w+dw
مزیت batch mode
مزیت این روش اینه که سرعت محاسبات بسیار بالا میره و به ما این امکان را میدهد که ساختارها و پارامترهای مختلفی در طول تحقیق بررسی کنیم. چرا که سرعت اجرا بسیار بالا رفته است. اما همین مسئله باعث ایجاد دو مشکل دیگه میشود که در ادامه بررسی خواهیم کرد.
عیب batch mode
در pattern mode نمونه های نویزی مثل یک ترم رگوله سازی عمل میکنند و باعث افزایش خاصیت generalization شبکه عصبی می شوند. ولی در batch mode چون وزنها به ازای همه نمونه های تخمین زده می شوند، تاثیر نمونه های نویزی از بین میره و این باعث افزایش احتمال overfitting شبکه عصبی می شود.
از طرف دیگه دیگه، وقتی تعداد نمونه های آموزش زیاد شود، هزینه محاسبات بالا میره و ممکن است کامپیوتر به دلایل مختلفی مثل (حافظه و پردازنده ها) نتواند هندل کند.
ارائه داده های آموزشی به شبکه عصبی به صورت mini-batch
برای حل مشکل هر دو رویکرد، mini-batch mode مطرح شده است. در این رویکرد، به جای اینکه کل نمونه ها یکجا و یا یکی یکی وارد شبکه عصبی شوند، به صورت تکه تکه (تکه های کوچک –mini-batches) وارد شبکه عصبی می شوند. با اینکار هم سرعت محاسبات افزایش می یابد و هم مشکلات مرتبط با batch-mode تا حدودی حل میشود.
Python
epoch=50 for iter in range(epoch): for xbatch,ybatch in train_loader: X,Ytrue= xbatch,ybatch # predict outputs Ypred=NeuralNetwor(w,X) # calculate errors e= Ytrue-Ypred # update weights w= w+dw
مزیت mini-batch mode
همانند pattern mode باعث میشه نمونه های نویزی همانند ترم رگوله سازی عمل کنند و این احتمال overfitting شبکه عصبی را کاهش میده و باعث میشه شبکه عصبی خاصیت generalization بالایی داشته باشد.
از طرفی هزینه محاسبات در این تاحدودی کاهش یافته و کامپیوتر میتواند به راحتی محاسبات لازم روی تکه ها را انجام دهد.
عیب mini-batch mode
تعداد تکه ی مشخصی وجود ندارد که در همه مسائل استفاده کرد و برای همین باید برای هر مسئله تعداد تکه های مناسب را تعیین کرد.
تعداد نمونه ها در هر تکه چقدر باشد؟
واقعیت این است که جواب مشخصی برای این وجود ندارد. و این کاملا به داده ای که با آن کار میکنید و یا حتی سیستمی که با آن پردازش ها را انجام میدهید دارد. در زیر چندین مورد را مطرح کرده ایم که در زمان انتخاب تعداد نمونه ها در هر تکه باید بررسی کرد:
اندازه پایگاه داده
- وقتی تعداد داده های ما زیاد هست میتوانیم batch-size های بیشتری هم امتحان کنیم. چرا که حجم داده خیلی زیاد هست و انتخاب batch-size بزرگ تعداد تکه ها خیلی کمک نخواهد شد و شبکه همچنان تکه های متنوعی رو در هر تکرار آموزش مشاهده خواهد کرد و احتمال overfitting بالا نخواهد رفت.
به خاطر داشته باشیم که در هر تکرار آموزش تنوع نمونه ها چقدر بیشتر باشد، شبکه بهتر یاد خواهد گرفت و خاصیت generalization بالایی خواهد داشت.
- اگر تعداد داده های آموزشی کم باشد، خب قاعدتا انتخاب batch-size بزرگ از این مسئله (متنوع بودن تکه ها) جلوگیری میکند و باعث افزایش احتمال overfitting شبکه عصبی شود. پس در چنین مواردی بهتر است batch-size های کوچکتری را امتحان کنیم.
میزان پیچیدگی شبکه عصبی
- شبکه هایی که تعداد لایه ها و نورونهای زیادی دارند، قاعدتا تعداد پارامترهایی بهینه سازی بسیار زیادی خواهند داشت. و همین باعث میشه این شبکه ها به خودی خود هم احتمال overfitting بالایی داشته باشند. حالا ما هم بیاییم batch-size بزرگی استفاده کنیم دیگه احتمال overfitting شبکه عصبی بسیار بالا خواهد بود! پس بهتر است در چنین مواردی batch-size کوچکتری امتحان کنیم تا نمونه های نویزی نقش ترم رگوله سازی را بازی کنند و احتمال overfitting را کاهش دهند.
حافظه سیستم
- batch-size های بزرگ را راحت میتوان برای پردازشهای موازی استفاده کرد و این باعث افزایش سرعت محاسبات میشود، ولی باید به این مسئله هم توجه کنیم که اگر batch-size خیلی بزرگ باشه ممکنه از ظرفیت حافظه GPU بیشتر باشه!
نرخ یادگیری
- همانطور که می دانیم، در زمان تنظیم وزنهای سیناپسی تغییرات طبق یک نرخ یادگیری اعمال می شوند. همانطور که گفتیم، در batch-size های کوچک، نمونه های نویزی وجود دارد، بهتر است نرخ یادگیری هم کوچک باشد تا از Overshooting مقدار پارامتر بهینه سازی جلوگیری کند. به عبارتی از ناپایداری شبکه جلوگیری کند. برای batch-size بزرگ هم عکس این صادق است.
بهترین راه برای انتخاب batch-size تجربه هست! بهتره برای پروژه ای که دارید، تعداد مختلف برای batch-size در نظر بگیرید و ببینید با کدام حالت در کمترین زمان به بیشترین عملکرد میرسید و آنرا انتخاب کنید.
چرا برخی جاها برای batch-size عدد 32 را پیشنهاد میکنند؟
واقعیت اینه که این عدد، عدد جادویی نیست که بگیم همیشه و هر جا همین عدد در نظر بگیریم به نتیجه بهتری خواهیم رسید. ولی خب به دلایل مختلف این عدد در میان محققین یادگیری عمیق خیلی مطرح شده و مقدار رایجی است و یابهتره بگیم مقدار پیش فرضی هست برای batch-size. اینجا چند تا از دلایل رو مطرح میکنیم.
اول اینکه توصیه میشه که batch-size رو عددی از میان 32-64-128,…,512 در نظر بگیریم [ref]. چرا که پردازش چنین batch ی برای GPU ها (کارتهای گرافیک) راحت است. فریم ورکهای deep learning مثل PyTorch برای پردازش های موازی بهینه شده اند. و GPU هایی که برای Deep learning حافظه محدودی دارند. برای همین batch-size که برحسب 2 به توان n تعیین می شوند، با معماری حافظه GPUها هماهنگی خوبی دارند و این باعث استفاده بهتر و موثر از حافظه می شود.
برای همین دلیل اول انتخاب 32 همین بوده است. دلیل دوم هم اینه که این تعداد، یک تعادل مناسبی بین پیچیدگی محاسباتی و عملکرد مدل ایجاد میکند. یک تعادل مناسب بین اثر batch-size بزرگ و کوچک ایجاد میکند. یعنی یجورایی هم از خاصیت stability تکه های بزرگ بهره میبره و هم از ترم رگوله سازی تکه های کوچک!
همچنین تعداد مطالعات موفق زیادی این عدد رو گزارش داده اند و همین باعث شده که به مرور زمان بین محققین این عدد یک مقدار پیش فرض برای batch-size در نظر گرفته شود.
توصیه من اینه که ابتدا با همین عدد شروع کنید، بعدش اگر مناسب نبود، مقادیر مختلف برای batch-size امتحان کنید تا به مقدار مناسب برای پروژه خودتون برسید. هیچ عددی جادویی وجود نداره و باید در عمل بررسی بشوند!
در دوره تخصصی پایتورچ به صورت تخصصی به این مباحث می پردازیم!
ما در دوره پایتورچ سه هدف اصلی داریم:
- یادگیری تئوری و ریاضیات شبکه های عصبی و روشهای بهینه سازی
- یادگیری کار با ابزار پایتورچ به صورت تخصصی
- ساخت dataloader ها اختصاصی برای داده های خودمان
- پیادهسازی شبکه های عصبی با ابزار پایتورچ
- انجام پروژه های عملی
دوره های مرتبط

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
دیدگاه ها