
18 سوال مهم شبکه عصبی مصنوعی در مصاحبه
شبکههای عصبی مصنوعی سیستم های محاسباتی هستند که از نحوه کارکرد نورونهای مغز الهام گرفته شده اند. شبکه عصبی اساس یادگیری عمیق است که منجر به دستیابی به نقاط عطف بزرگتر، تقریباً در همه زمینه ها میشود و در نتیجه تحولی ایجاد میکند که در آن به یک مشکل نزدیک می شویم. بنابراین موضوع شبکه عصبی برای هر فرد مشتاق به Data Scientist و مهندسی یادگیری ماشین ضروری است که شناخت خوبی از این شبکه های عصبی داشته باشد.
در این مقاله قصد داریم تا در رابطه با سوالات مهم در زمینه شبکه مصنوعی (ANN) بحث کنیم. این موضوع به شما کمک میکند تا درک روشنی از روشها داشته باشید و همچنین برای مصاحبههای علوم داده، که سطح بسیار اساسی آن را در مفاهیم پیچیده پوشش می دهد، بسیار مفید واقع می شود.
نویسنده: امیررضا جهانی
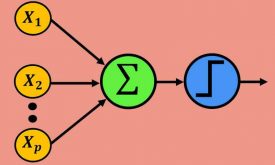
منظور از پرسپترون چیست؟
یک پرسپترون که یک نورون مصنوعی نیز نامیده می شود، یک واحد شبکه عصبی است که برای تشخیص ویژگیها، محاسبات خاصی را انجام می دهد.
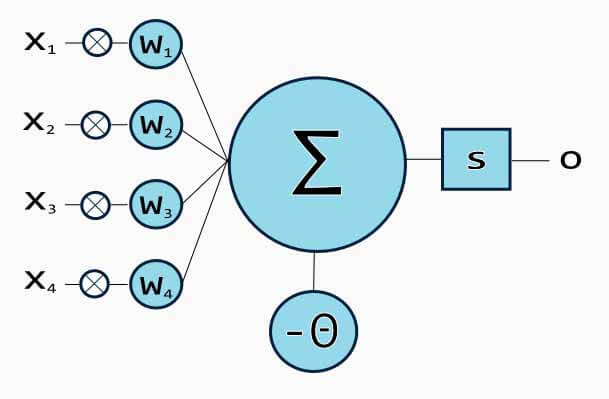
پرسپترون یک شبکه عصبی است که هنگام کار با مجموعهای از داده های ورودی، به عنوان یک طبقه بندی کننده خطی استفاده می شود. از آنجایی که پرسپترون از نقاط داده طبقه بندی شده که قبلاً برچسب گذاری شده اند استفاده می کند، یک الگوریتم یادگیری تحت نظارت نیز می باشد. این الگوریتم برای فعال کردن سلولهای عصبی جهت یادگیری و پردازش عناصر در مجموعه آموزش ها به طور همزمان استفاده میشود.
انواع مختلف شبکه عصبی پرسپترون کدامند؟
به طور کلی دو نوع شبکه عصبی پرسپترون داریم:
-
شبکه عصبی پرسپترون تک لایه
گیرنده های تک لایه فقط می توانند الگوهای قابل تفکیک خطی را یاد بگیرند.
-
شبکه عصبی پرسپترون چند لایه
شبکه عصبی پرسپترون چند لایه، همچنین به عنوان شبکه های عصبی پیشخور با دو یا چند لایه شناخته میشوند که قدرت پردازش بالاتری دارند. و میتوانند علاوه بر مسائل خطی، مسائل غیرخطی طبقه بندی و رگرسیون را حل کنند.
کاربرد توابع خطا (loss function) چیست؟
از تابع خطا به عنوان معیار سنجش دقت استفاده میشود تا مشخص شود که آیا شبکه عصبی ما الگوها را به کمک دادههای آموزش به طور دقیق یاد گرفته است یا خیر. این کار با مقایسه داده های آموزش، با داده های آزمایش تکمیل می شود.
بنابراین، تابع خطا به عنوان یک معیار اصلی برای عملکرد شبکه عصبی در نظر گرفته می شود. در یادگیری عمیق، یک شبکه عصبی با عملکرد خوب، در هر زمان که آموزش اتفاق میافتد، مقدار کمی از خطا را خواهد داشت.
نقش توابع فعال در شبکه های عصبی چیست؟
دلیل استفاده از توابع فعال در شبکه های عصبی به شرح زیر است:
- ایده تابع فعال این است که غیرخطی بودن را به شبکه عصبی وارد کنید تا بتواند توابع پیچیده تری را بیاموزد.
- بدون تابع فعال، شبکه عصبی به عنوان یک طبقه بند خطی رفتار می کند، تابعی را یاد می گیرد که ترکیبی خطی از داده های ورودی آن است.
- تابع فعال ورودی ها را به خروجی نگاشت میدهد.
- تابع فعال وظیفه تصمیم گیری در مورد اینکه آیا یک نورون باید فعال شود، یعنی fired یا خیر، را بر عهده دارد.
- برای تصمیم گیری، ابتدا جمع وزندار را محاسبه می کند و سپس بایاس را به آن اضافه میکند.
- بنابراین، هدف اصلی از تابع فعال این است که غیرخطی بودن را به خروجی یک نورون وارد کند.
نام برخی از توابع فعال محبوب مورد استفاده در شبکه های عصبی را لیست کنید.
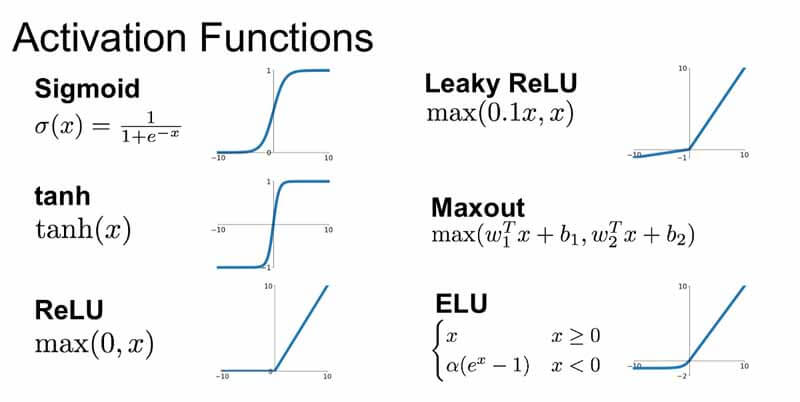
برخی از توابع فعال محبوب که هنگام ساخت مدل های یادگیری عمیق استفاده می شود به شرح زیر است:
- تابع سیگموئید
- تابع ملکرد مماس هذلولی
- تابع واحد خطی اصلاح شده (RELU)
- تابع Leaky RELU
- تابع حداکثر
- تابع واحد خطی نمایی (ELU)
تابع هزینه (Cost Function) چیست؟
در حالی که مدلهای یادگیری عمیق ایجاد می کنیم، هدف اصلی ما به حداقل رساندن تابع هزینه است. یک تابع هزینه توضیح می دهد که شبکه عصبی برای داده های آموزش داده شده و بازده مورد انتظار چقدر خوب عمل می کند. این ممکن است به پارامترهای شبکه عصبی مانند وزن و بایاس بستگی داشته باشد. به طور کلی، عملکرد یک شبکه عصبی را فراهم می کند.
Backpropagation (پس انتشار خطا) چیست؟
الگوریتم backpropagation برای آموزش شبکه های عصبی چند لایه استفاده میشود. اطلاعات خطا را از انتهای شبکه به تمام وزن های داخل شبکه منتقل میکند. این امکان را برای محاسبه کارآمد گرادیان یا مشتقات فراهم میکند.
پس انتشار خطا را می توان به مراحل زیر تقسیم کرد:
- می تواند انتشار داده های آموزش را از طریق شبکه برای تولید خروجی هدایت کند.
- از مقدار هدف و مقدار خروجی برای محاسبه مشتقات خطا با توجه به توابع فعال خروجی استفاده میکند.
- میتواند برای محاسبه مشتقات خطای مربوط به توابع فعال خروجی در لایه قبلی و برای همه لایه های پنهان ادامه یابد.
- از مشتقات قبلی محاسبه شده برای خروجی و تمام لایه های پنهان برای محاسبه مشتق خطا برای وزنهای سیناپسی استفاده میکند.
- در هر تکرار آموزش، وزنهای سیناپسی را به روزرسانی میکند و تا زمانی که تابع هزینه به حداقل برسد این کار را تکرار میکند.
چه مقدار اولیه برای وزنهای سیناپسی و مقدار بایاس در شبکه های عصبی در نظر بگیریم؟
مقداردهی اولیه شبکه عصبی به معنای مقدار دهی اولیه مقادیر پارامترها یعنی وزن و بایاس است. برای بایاس می توان به صفر در نظر گرفت، اما نمی توانیم وزنهای سیناپسی را با مقدار صفر مقداردهی اولیه کنیم.
مقداردهی اولیه وزنهای سیناپسی یکی از فاکتورهای اساسی در شبکههای عصبی است زیرا بد بودن مقدار اولیه وزن میتواند از یادگیری الگوهای شبکه عصبی جلوگیری کند.
برعکس، یک مقداردهی اولیه مناسب در همگرایی سریع تر به global minima کمک می کند. به عنوان یک قاعده کلی، قانون مقدار دهی وزن ها این است که یک مقدار کوچک نزدیک به صفر به آنها اختصاص دهیم ولی نباید خیلی خیلی به صفر نزدیک باشد.
چرا مقدار دهی اولیه صفر برای وزنهای سیناپسی مقدار مناسبی نیست؟
اگر مجموعه ای از وزنهای سیناپسی را در شبکه عصبی صفر کنیم، در این صورت تمام سلول های عصبی در هر لایه شروع به تولید همان خروجی و شیب های یکسان می کنند. در نتیجه، شبکه عصبی به هیچ وجه نمی تواند چیزی یاد بگیرد زیرا هیچ منبع عدم تقارن بین نورونهای مختلف وجود ندارد. بنابراین، ما هنگام مقدار دهی اولیه وزنهای سیناپسی در شبکه های عصبی، تصادفی بودن را اضافه می کنیم.
گرادیان نزولی (Gradient Descent) و انواع آن را توضیح دهید
Gradient Descent یک الگوریتم بهینه سازی است که هدف آن به حداقل رساندن عملکرد هزینه یا به حداقل رساندن خطا است. هدف اصلی آن یافتن حداقل های محلی یا سراسری یک تابع براساس محدب بودن آن است. این موضوع مشخص میکند که مدل برای کاهش خطا باید به کدام سمت برود.
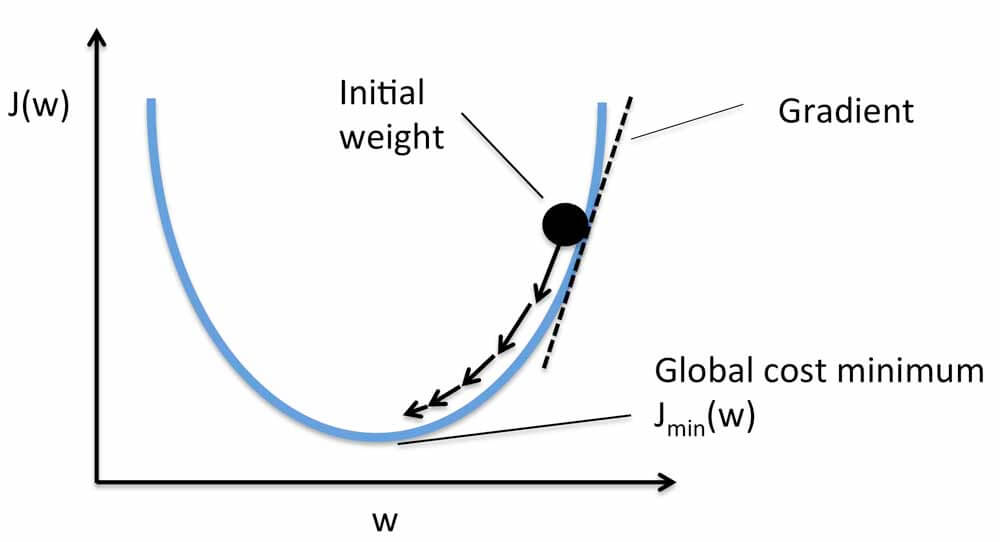
سه نوع گردایان نزولی وجود دارد:
- گرادیان نزولی مینی دسته ای(mini-batch)
- گرادیان نزولی تصادفی(stocastic)
- گرادیان نزولی دسته ای(batch)
مراحل مختلف استفاده شده در الگوریتم Gradient Descent را توضیح دهید.
پنج مرحله اصلی که برای شروع و استفاده از الگوریتم گرادیان نزولی استفاده می شود به شرح زیر است:
- بایاس و وزن های سیناپسی شبکه عصبی را مقداردهی اولیه کنید.
- داده های ورودی را از طریق شبکه یعنی لایه ورودی عبور دهید.
- تفاوت یا خطای بین مقادیر پیش بینی شده و مورد انتظار را محاسبه کنید.
- وزنهای سیناپسی را طوری تنظیم کنید که تابع خطا حداقل شود.
- تکرار مراحل 1 تا 4 تا زمانی که بوزنهای سیناپسی به مقدار بهینه ای همگرا شوند و خطا حداقل شود.
اصطلاح “نرمال سازی داده” را توضیح دهید
نرمال سازی داده ها یک مرحله پیش پردازش اساسی است، که برای جابجایی مقادیر اولیه در یک محدوده خاص استفاده میشود. این موضوع همگرایی بهتر در پس انتشار خطا را تضمین میکند.
به طور کلی، نرمال سازی داده ها به این شکل است که مقدار هر ویژگی را از میانگین کم کرده و تقسیم بر انحراف معیار بکنیم. از آنجا که ورودی های موجود در هر لایه را نرمال می کنیم، این روش عملکرد و پایداری شبکه های عصبی را بهبود می بخشد.
تفاوت بین انتشار رو به جلو و انتشار رو به عقب در شبکه های عصبی چیست؟
انتشار رو به جلو: ورودی به شبکه وارد می شود. در هر لایه، یک تابع فعال خاص وجود دارد و بین لایه ها، وزن هایی وجود دارد که قدرت اتصال نورون ها را نشان می دهد. ورودی از طریق لایه های جداگانه شبکه عبور می کند که در نهایت یک خروجی ایجاد می کند.
انتشار رو به عقب: یک تابع خطا میزان دقیق خروجی شبکه را اندازه گیری می کند. برای بهبود خروجی، وزن ها باید بهینه شوند. از الگوریتم backpropagation برای تعیین چگونگی تنظیم وزن های سیناپسی استفاده می شود. وزن ها در طول آموزش با کمک گرادیان نزولی تنظیم می شوند.
انواع مختلف گرادیان نزولی را با جزئیات توضیح دهید.
Stochastic Gradient Descent : در گرادیان نزولی تصادفی، از اندازه دسته ای 1 استفاده می شود. در نتیجه، ما n دسته می گیریم. بنابراین، وزن شبکه های عصبی پس از هر نمونه آموزش به روز می شود.
Mini-batch Gradient Descent : در Mini-batch Gradient Descent، اندازه Batch باید بین 1 و اندازه مجموعه داده آموزش باشد. در نتیجه، k دسته بدست می آوریم. بنابراین، وزن شبکه های عصبی پس از هر تکرار Mini-Batch به روز می شود.
منظور از ماشین بولتزمن چیست؟
یکی از اساسی ترین مدل های یادگیری عمیق، ماشین بولتزمن است که شبیه نسخه ساده پرسپترون چند لایه است. این مدل دارای یک لایه ورودی قابل مشاهده و یک لایه پنهان است – تنها یک شبکه عصبی دو لایه است که تصمیمات تصادفی را در مورد اینکه آیا یک نورون باید فعال شود یا خیر، می گیرد. در ماشین بولتزمن، گره ها از طریق لایه ها به هم متصل می شوند، اما هیچ دو گره از همان لایه به هم متصل نیستند.
نرخ یادگیری چه تاثیری بر آموزش شبکه عصبی دارد؟
هنگام انتخاب نرخ یادگیری برای آموزش شبکه عصبی، به دلایل زیر باید مقدار را بسیار دقیق انتخاب کنیم:
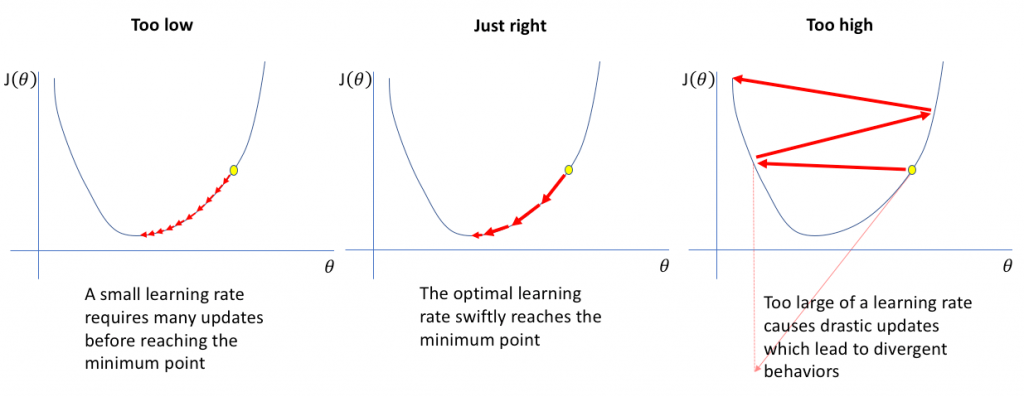
- اگر نرخ یادگیری خیلی پایین تنظیم شود، آموزش مدل بسیار آهسته ادامه خواهد یافت زیرا ما در وزن ها تغییرات بسیار کوچکی ایجاد می کنیم ، زیرا اندازه گام ما که تحت معادله گرادیان نزولی کنترل می شود کم می باشد. ممکن است قبل از رسیدن به حداقل خطا، تکرارهای زیادی طول بکشد. و همچنین ریسک همگرایی در میینمم محلی بالا میرود.
- اگر نرخ یادگیری بیش از حد بالا تنظیم شود، این امر باعث عملکرد واگرایی نامطلوب در تابع خطا به دلیل تغییرات زیاد در وزن ها و همچنین به دلیل مقدار بزرگتر اندازه گام می شود. ممکن است همگرا نشود (مدل می تواند خروجی خوبی بدهد) یا حتی واگرایی کند (داده ها برای آموزش شبکه بسیار آشفته هستند).
منظور از Hyperparameters چیست؟
هنگامی که داده ها به درستی قالب بندی می شوند، ما معمولاً با hyperparameters در شبکه های عصبی کار می کنیم. hyperparameters نوعی پارامتر است که مقادیر آن قبل از شروع فرآیند یادگیری ثابت می شود. hyperparameters تصمیم می گیرند که چگونه یک شبکه عصبی آموزش داده شود و همچنین ساختار شبکه شامل موارد زیر است:
- نرخ یادگیری
- تعداد لایههای پنهان
- تعداد نورونها
- تعداد epoch و غیره
چرا شبکه های عصبی عمیق بر شبکه های عصبی کم عمق ترجیح داده می شوند؟
شبکه های عصبی جدا از لایه های ورودی و خروجی حاوی لایه های مخفی هستند. برای شبکه های عصبی کم عمق فقط یک لایه مخفی بین لایه های ورودی و خروجی وجود دارد در حالی که برای شبکه های عصبی عمیق، چندین لایه استفاده شده است. برای تقریب هر عملکردی، هر دو شبکه کم عمق و عمیق به اندازه کافی خوب و توانمند هستند، اما هنگامی که یک شبکه عصبی کم عمق در هر عملکردی قرار می گیرد، برای یادگیری به پارامترهای زیادی نیاز دارد. برعکس، شبکه های عمیق با تعداد محدودی پارامتر می توانند عملکردها را حتی بهتر تطبیق دهند، زیرا آنها دارای چندین لایه پنهان هستند.
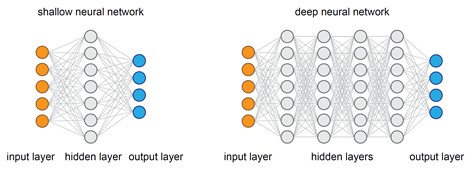
بنابراین، برای همان سطح دقت، شبکه های عمیق تر از نظر محاسبات و تعداد پارامترهای یادگیری می توانند بسیار قدرتمندتر و کارآمدتر باشند.یک نکته مهم دیگر در مورد شبکه های عمیقتر این است که آنها می توانند نمایش های عمیقی ایجاد کنند و در هر لایه، شبکه یک نمایش جدید و انتزاعی از ورودی را می آموزد. بنابراین، در دوران مدرن، شبکه های عصبی عمیق، به دلیل توانایی کار در هر نوع مدل سازی داده، ترجیح داده شده اند.
Overfitting یکی از رایج ترین مشکلاتی است که هر یک از متخصصین یادگیری ماشین با آن روبرو هستند. برخی از روش ها را برای جلوگیری از Overfitting در شبکه های عصبی توضیح دهید.
dropout: این یک روش منظم سازی است که از overfitting شبکه عصبی جلوگیری می کند. در حین آموزش به طور تصادفی سلول های عصبی را از شبکه عصبی رها می کند که معادل آموزش شبکه های مختلف عصبی است. شبکه های مختلف به طور متفاوتی برتری خواهند داشت، بنابراین اثر خالص روش تنظیم قاعده گذاری برای کاهش اتصالات اضافی خواهد بود به طوری که مدل ما برای تجزیه و تحلیل پیش بینی خوب خواهد بود.
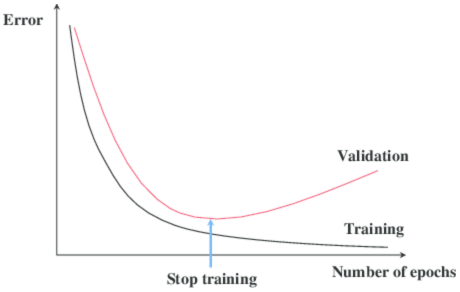
توقف زودرس: این روش منظم سازی، مدل را به روز می کند تا با داده های آموزش با هر تکرار بهتر سازگار شود. بعد از تعداد مشخصی تکرار، تکرارهای جدید مدل را بهبود می بخشند. با این حال، پس از آن مرحله، مدل شروع به انطباق با داده های آموزش می کند. توقف زودرس به توقف روند آموزش قبل از آن مرحله اشاره دارد.
چه تفاوتی بین Epoch ، Batch و Iteration در شبکه های عصبی وجود دارد؟
Epoch ، Batch و Iteration انواع مختلفی هستند که برای پردازش مجموعه داده ها و الگوریتم های گرادیان نزولی استفاده می شوند. همه این سه روش اساساً در گرادیان نزولی بسته به اندازه مجموعه داده استفاده میشوند.
Epoch: تعداد تکرار در کل مجموعه داده های آموزشی نشان می دهد (منظور از کل مجموعه، هر آنچه در مدل آموزش قرار می گیرد می باشد).
Batch: این به مواردی اطلاق می شود که ما به دلیل مشکل محاسبات زیاد قادر به انتقال یکباره مجموعه داده به شبکه عصبی نیستیم، بنابراین مجموعه داده را به چند دسته تقسیم می کنیم.
iteration: بیایید 10،000 تصویر را به عنوان مجموعه داده های آموزشی خود داشته باشیم و برای اندازه batch 200 را انتخاب می کنیم. سپس یک دوره باید (10000/200) تکرار اجرا شود، یعنی شامل 50 تکرار می باشد.
اگر به دنبال یادگیری تخصصی شبکه عصبی هستید پیشنهاد میکنیم دوره جامع شبکه عصبی رو مطالعه کنید. محتوای آموزشی این دوره بر پایه کتاب مرجع Simon & heykins آماده شده است. در دوره شبکه عصبی علاوه بر یادگیری مباحث تئوری و ریاضی چندین پروژه عملی هم انجام شده است. این دوره یک دوره تخصصی هست و به علاقه مندان کمک میکند تا مباحث را از پایه و به صورت تخصصی یاد بگیرند.
دوره های مرتبط

پکیج کامل پیادهسازی گام به گام شبکههای عصبی
پیاده سازی شبکه عصبی پرسپترون تک لایه (جلسه دوم)

شبکه عصبی پرسپترون چندلایه (جلسه چهارم)
شبکه عصبی RBF(جلسه هشتم)
شبکه عصبی ELM (جلسه نهم)
دیدگاه ها