
روشهای تشخیص دادههای پرت – Outliers
- دسته:اخبار علمی
- نسرین رفیعی
داده های پرت یا Outlier ها می توانند درکی از داده های مورد مطالعه به ما بدهند و بر نتایج آماری تاثیر بگذارند. شناسایی آن ها به ما کمک می کند تا ناهماهنگی را پیدا کنیم و هرگونه خطا در فرآیندهای آماری را تشخیص دهیم. در این مقاله ضمن تعریف داده های پرت، روش های شناسایی آن ها در مجموعه داده را شرح خواهیم داد.
داده های پرت یا Outliers در مجموعه داده چیست؟
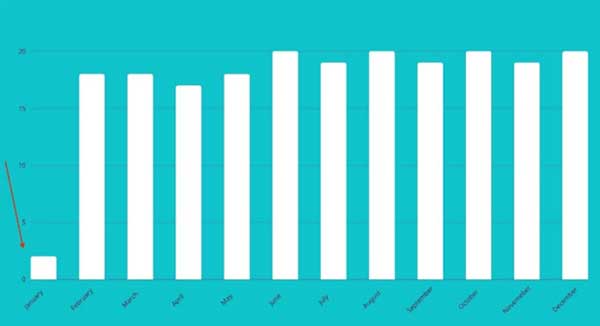
یک داده ی پرت، داده ای است که در فاصله ی غیرعادی از بقیه ی مقادیر داده در یک نمونه ی تصادفی از یک جمعیت مشاهده می شود. تا حدی فاصله ی این داده با بقیه ی داده ها غیرعادی است که آنالیزگر را به این وا می دارد که بررسی کند چه چیزی در داده ها به نظر غیرعادی می آید. به عبارتی، Outlier ها مقادیری هستند که در الگوی اصلی مجموعه داده یا گرافی از داده به صورت برجسته و متمایز قرار گرفته اند. برای مثال در سمت چپ شکل، یک Outlier وجود دارد. مقدار مشخص شده برای ماه ژانویه به طور قابل ملاحظه ای از مقدار بقیه ی ماه ها کمتر است بنابراین اطلاعات مربوط به ماه ژانویه جز داده های پرت محسوب می شود.
تفاوت Outlier و نویز
توجه داشته باشید که Outlier متفاوت از نویز است. Outlier مربوط به یک مجموعه داده، بطور معنی داری با بقیه داده ها، متمایز است. در حالی که نویز یک خطا یا واریانس تصادفی است. Outlier قسمتی از داده است اما نویز تنها یک خطای تصادفی است که می تواند به اشتباه برچسب گذاری شده باشد یا حتی می تواند داده را از بین ببرد.
چرا شناسایی Outlier ها مهم است؟
- یک داده ی پرت می تواند داده ی بدی باشد. مثلا ممکن است باعث شود داده به غلط کدگذاری شود یا یک آزمایش به درستی اجرا نشود. اگر مشخص شود که یک نقطه از داده ی پرت در واقع غلط است، آنگاه آن مقدار داده ی پرت باید از آنالیز حذف شود یا اگر امکان پذیر است؛ تصحیح گردد.
- در برخی از مواقع، تعیین داده ی پرت در صورتی که از نوع داده ی بد باشد، میسر نیست. با توجه به اینکه داده های پرت متغیرهای تصادفی هستند می توانند بطور قابل ملاحظه ای نتیجه ی جالبی را نشان دهند. در هر صورت، معمولا قصد ما این نیست که دادهی پرت را به راحتی حذف کنیم. اما اگر داده، حاوی داده های پرت معنادار باشد، باید از روش های آماری مقاوم برای حذف آن ها استفاده کنیم.
چگونه می توان Outlier ها را تشخیص داد؟
قبل از اینکه مشاهده های غیرعادی از بقیه ی داده ها جدا شوند، باید مشاهده های عادی مشخص شوند. دو راه اساسی برای مشخص کردن مجموعه داده به صورت زیر مطرح شده است:
- ارزیابی شکل کلی داده که فیچرهای اصلی آن بصورت گراف درآمده باشد.
- ارزیابی داده های مربوط به مشاهدات غیرعادی که از بقیه ی حجم داده جدا افتاده است.
4 روش برای شناسایی داده های پرت وجود دارد که می توانید با توجه به زمان و منابعی که دارید، یکی از آن ها را انتخاب کنید.
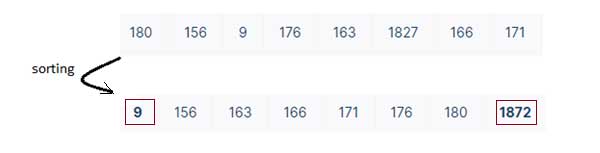
1-روش مرتب کردن برای تشخیص داده پرت
برای متغیرهای عددی، داده ها را از مقدار کم به زیاد مرتب کنید و بررسی کنید که مقدار کدام داده نسبت به بقیه نقاط داده، بسیار بالاتر یا بسیار پایین تر هستند. این روش، یکی از ساده ترین روش ها برای چک کردن داده های اصلی قبل از اعمال هر گونه متد حرفه ای برای تشخیص داده ی پرت است.
2-روش رسم برای تشخیص داده پرت
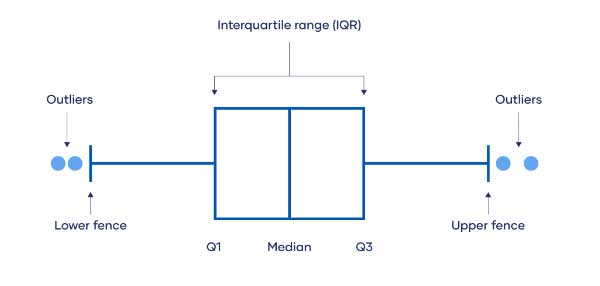
می توانید با استفاده از نرم افزار، داده های خود را با box plot, box-and-whisker plot رسم کنید تا در یک نگاه، توزیع کلی دیتا دستتان بیاید. در این نوع چارت ها، مقادیر ماکزیمم، مینیمم، میانه و بازه ی چارک ها مشخص می شود.
3-تست های آماری برای تشخیص داده پرت
با استفاده از تست ها و فرآیندهای آماری می توانید مقادیر بسیار زیاد یا بسیار کم را شناسایی کنید. می توانید این مقادیر اکستریم را به z scores تبدیل کنید. z scores به شما می گوید که انحراف معیار آن ها از میانگین چقدر است. اگر این مقدار به اندازه ی کافی از z scores بزرگتر یا کوچکتر باشد، یک Outlier به حساب می آید. با یک حساب سرانگشتی، z score بزرگتر از 3 یا 3- ، Outlier در نظر گرفته میشود.

4-روش بازه ی چارک اول تا سوم برای تشخیص داده پرت
بازه ی چارک اول تا سوم (IQR) گستره ی نیمه میانه مجموعه دیتا را به شما می گوید. می توانید از IQR به عنوان حصاری در حوالی داده استفاده کنید و هر مقداری که در خارج از این حصار قرار گرفت را داده ی پرت در نظر بگیرید.
بازه ی چارک اول تا سوم
این روش زمانی به کار می رود که داده های پرت در انتهای مجموعه داده قرار گرفته اند اما نمی دانید که کدام یک از آن ها، داده ی پرت محسوب می شود. برای اعمال این روش، لازم است که مراحل زیر را به ترتیب پیش ببرید.
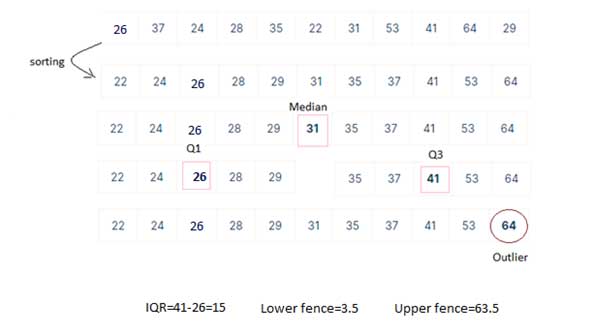
- داده ها را از کم به زیاد مرتب کنید.
- چارک اول (Q1)، میانه و چارک سوم(Q3) را مشخص کنید.
- IQR=Q3-Q1 را محاسبه کنید.
- حصار بالایی =Q3+(1.5*IQR) را محاسبه کنید.
- حصار پایینی = Q1-(1.5*IQR)را محاسبه کنید.
- هر داده ای که خارج از این حصارها بود را به عنوان داده ی پرت در نظر بگیرید.
داده های پرت، مقادیری هستند که از حصار بالایی بزرگتر و از حصار پایینی کوچک تر هستند.
آیا داده های پرت می توانند حاوی اطلاعات مهمی باشند؟
بعضی از داده های پرت، مقادیر صحیحی از تغییرات طبیعی را نشان می دهند. برخی دیگر ممکن است ناشی از داده های ورودی غیرصحیح، نقص تجهیزات یا خطای اندازه گیری باشند. غالبا Outlier ها، اطلاعات مهمی در مورد فرآیند در دست بررسی، جمع آوری اطلاعات یا روند ثبت داده دارند. بنابراین باید به دقت مورد بررسی قرار بگیرند. قبل از اینکه روش های ممکن برای حذف این نقاط از داده را اعمال کنیم، می بایست بفهمیم چرا اصلا آن ها ظاهر شده اند و اینکه آیا امکان دارد که مقادیر مشابه آن ها باز هم در داده ظاهر شوند یا نه؟ البته که آن ها اغلب نقاط بد در داده هستند.
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)
دیدگاه ها