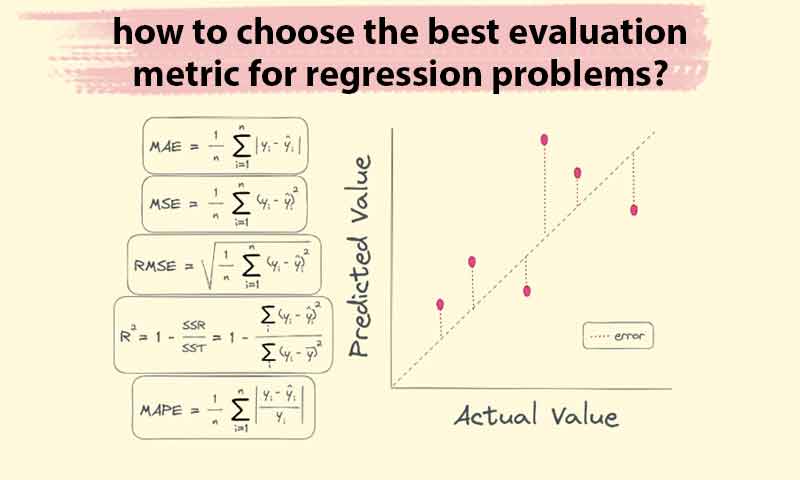
نحوه ی انتخاب بهترین معیار ارزیابی برای مسائل رگرسیون
- دسته:اخبار علمی
- نسرین رفیعی
قبل از اینکه یک مدل رگرسیون را بسازیم، باید چند دقیقه ای به نحوه ی ارزیابی آن با دقت فکر کنیم. عواملی مختلفی درتصمیم گیری برای نحوه ی ارزیابی رگرسیون نقش دارند. مثلا این که آیا خطاهای بزرگ نسبت به خطاهای کوچک، باید بیشتر جریمه شوند؟ یا اینکه این معیار چقدر باید برای کاربر شهودی و قابل درک باشد؟ در این مقاله رایج ترین معیارهای ارزیابی برای مسائل رگرسیون عنوان شده است. برای هر معیار، مثالی آورده ایم تا به شما کمک کند بهترین معیار را با توجه به مساله خودتان انتخاب کنید.
یک راهنمای جامع بررسی رایج ترین معیارهای ارزیابی مورد استفاده در رگرسیون و کاربرد آن در سناریوهای مختلف
رگرسیون
یک مساله رگرسیون در واقع یک مساله یادگیری ماشین با نظارت است که با پیش بینی خروجی، عددی پیوسته براساس یک یا چند ورودی محاسبه می شود.
فرض کنید یک مدل رگرسیون داریم که می خواهد قیمت مسکن بر اساس ویژگی های مختلف مثل تعداد اتاق خواب ها، حمام، متراژ، موقعیت مکانی و غیره پیش بینی کند. درست است که معیارهای ارزیابی مختلفی را در اختیار داریم اما مساله اینست که بهترین معیاری که با هدف ما هماهنگی بیشتری را دارد انتخاب کنیم.
برای مثال، اگر معیاری را انتخاب کنیم که به طور قابل ملاحظه ای خطاهای بزرگ- و به دنبال آن تلفات- را تقویت کند، به این معنی است که حتی این یک خطای بزرگ می تواند اندازه ی خطای کل مدلمان را تا حد زیادی افزایش بدهد و آن را تبدیل به مدلی کند که ضعیف عمل می کند. با این حال، اهمیت یک خطای بزرگ به اندازه ی خطاهای کوچک نیست. بنابراین، اگر هدف پیش بینی دقیق قیمت مسکن است نه مینیمم کردن خطای کل، معیاری مناسب انتخاب است که وزن دهی مساوی برای همه ی خطاها داشته باشد.
بیایید چند معیاری که عموما استفاده می شود را بررسی کنیم و در مورد کاربرد آن در سناریوهای مختلف بحث کنیم.
معیارهای ارزیابی
میانگین خطای مطلق (MAE)Mean Absolute Error
میانگین خطای مطلق یا MAE یک معیار معروف برای مسائل رگرسیون است. و واحدهای خطا با واحدهای متغیر هدف مطابق هستند. مثلا اگر متغیر هدف بر حسب دلار امریکا باشد، خطای آن نیز بر حسب دلار امریکا است.
میانگین خطای مطلق، قدر مطلق تفاوت بین مقادیر پیش بینی شده و واقعی را اندازه می گیرد.
MAE به صورت زیر محاسبه می شود:
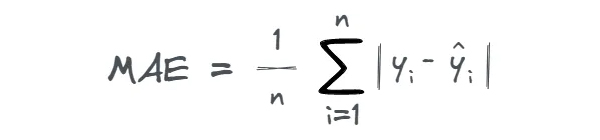
y مقدار واقعی، yh مقدار پیش بینی شده و n تعداد مشاهدات در داده را مشخص می کند.
زمانی که هدف، ارزیابی عملکرد یک مدل رگرسیون باشد به طوری که وزن های مساوی برای همه ی خطاها و صرف نظراز دامنه ی آن ها باشد، MAE یک معیار مفید است.
برای نشان دادن این موضوع، به جدول زیر نگاه کنید که داده ی ساختگی از مقادیر واقعی و پیش بینی شده و MAE مربوطه را نشان می دهد. توجه داشته باشید صرف نظراز اینکه مقادیر پیش بینی شده از مقادیر واقعی بزرگ تر یا کوچک تر باشد؛ خطای مطلق همیشه مثبت است. علاوه بر این به منظور تاکید بر رشد خطی خطای مطلق، مقدار واقعی روی 200 ثابت کردیم و به طور خطی، خطای پیش بینی ها را افزایش دادیم.
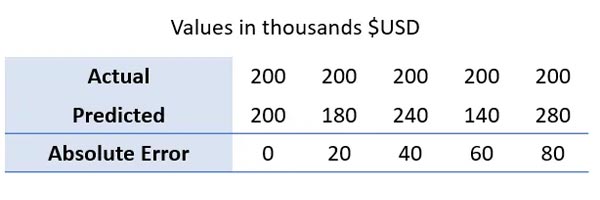
بر اساس این داده ها، می توانیم با استفاده از فرمول بالا، MAE را محاسبه و 40$ را بدست بیاوریم.
MAE برای درک این که چقدر پیش بینی ها از مقادیر واقعی دور هستند یک معیار کاملا قابل تفسیر است. علاوه بر این، نسبت به داده های پرت مقاوم است زیرا خطاهای بزرگ را با مربع کردنشان، بزرگ نمی کند. به طور خاص برای جاهایی که خطاهای بزرگ به طور قابل ملاحظه ای از خطاهای کوچک مهم تر نیستند، MAE یک معیار مفید است.
مثال: همانطور که گفته شد MAE یک معیار شهودی برای پیش بینی قیمت مسکن است. با اندازه گیری متوسط تفاوت مطلق بین مقادیر واقعی و پیش بینی شده، یک معیار مرتبط تر داریم که به ما کمک می کند که بفهمیم چقدر پیش بینی ها نسبت به میانگین، پراگندگی دارد. از جمله مثال های دیگر آن می توان به این موارد اشاره کرد: پیش بینی نمره ی امتحانات دانش آموزان، پیش بینی تقاضا برای محصولات یا پیش بینی تعداد روزهایی است که بیماران در بیمارستان بستری می شوند.
میانگین مربع خطا (MSE) Mean Squared Error
میانگین مربع خطا یا MSE اغلب زمانی استفاده می شود که هدف جریمه بیشتر خطاهای بزرگتر نسبت به خطاهای کوچکتر باشد. متوسط مربع خطا، متوسط مربع تفاوت میان مقادیر واقعی و پیش بینی شده را اندازه می گیرد و مانند زیر محاسبه می شود:
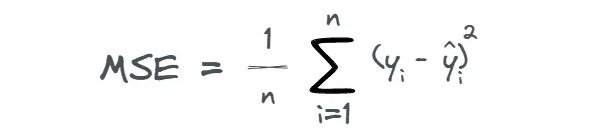
معمولا MSE زمانی به کار می رود که هدف، تاکید داشتن بر خطاهای بزرگ تر است چرا که تفاوت مقادیر واقعی و پیش بینی شده به توان 2 می رسد. برای روشن تر شدن موضوع، به مقادیر واقعی و پیش بینی شده در زیر نگاه کنید و رشد سریع مربع خطا با افزایش انحراف پیش بینی ها را ببینید.
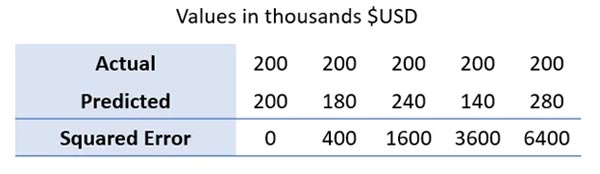
در اینجا MSE مربع 2400$ می شود که یک واحد نسبتا غیر شهودی است که اغلب می تواند کاربر را گیج کند.
در مقایسه با خطای مطلق که با افزایش انحراف به طور خطی افزایش می یافت، مربع خطا به طور خیر خطی و خیلی سریع تر افزایش می یابد. زیرا وزن بیشتری بر خطاهای بزرگ تر اعمال می کند.
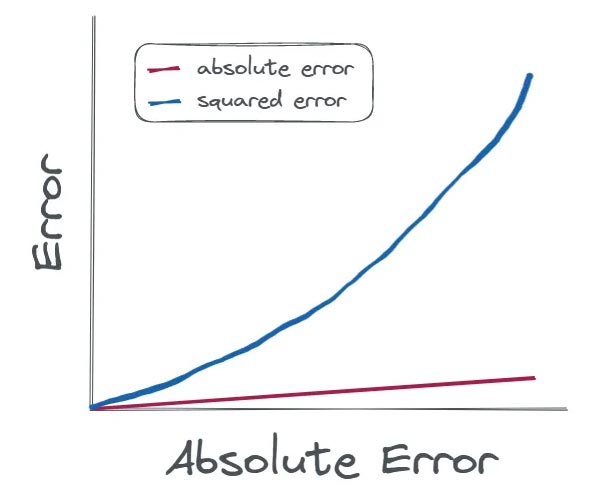
مثال: از MSE می توان برای پیش بینی بورس با هدف حداقل کردن خطای کل پیش بینی استفاده کرد. در این مواقع، اهمیت قابل تفسیربودن به اندازه ی صحت(accuracy) نیست. علاوه بر این، در اینجا جبران خطاهای بزرگ تر بحرانی تر است چرا که غالبا می تواند منجر به تلفات مالی قابل ملاحظه ای شود.
معیار Root Mean Squared Error (RMSE)
متوسط ریشه ی مربع خطا یا RMSE مانند MSE یک معیار معروف برای زمانی است که هدف جریمه خطای بزرگ تر نسبت به خطای کوچکتر است. علاوه بر این، یک معیار شهودی تر هم هست زیرا واحد آن همانند واحد متغیر هدف است. به عبارت دیگر، اگر متغیر هدف دلار آمریکا باشد، واحد RMSE هم دلار آمریکاست.
متوسط ریشه ی مربع خطا ، مربع ریشه ی متوسط مربع تفاوت بین مقادیر واقعی و پیش بینی شده را اندازه می گیرد. به زبان سادهتر مربع ریشه ی MSE است.
RMSE مانند زیر محاسبه می شود:
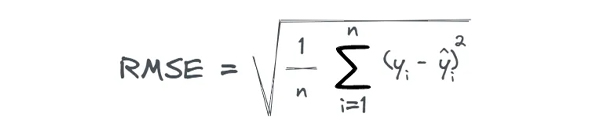
بر اساس قسمت قبل، می دانیم که MSE نمونه داده مربع 2400$ است. بنابراین RMSE به راحتی ریشه ی مربع آن می شود که 49.99$ است.
مثال: RMSE اکثرا برای پیش بینی آب و هوا مورد استفاده قرار می گیرد که متغیر هدف معمولا برخی اندازه گیری های دمایی و بارش باران است. در این سناریو، وزن دهی بیشتر بر خطاهای بزرگتر بهتر است زیرا بر اهمیت پیش بینی دقیق رخدادهای حاد آب و هوایی تاکید می کند که این وقایع نه تنها می تواند ما را مردد کند که آیا چتر با خودمان ببریم یا نه بلکه تاثیر زیادی بر زیرساخت ها، حمل و نقل و کشاورزی می گذارد. همچنین به دست آوردن یک اندازه غلط در همان واحد به عنوان متغیر هدف، درک شهوی تری از صحت مدل ارائه می دهد.
R-Squared
معیار مربع R یا R2 نشان می دهد که چقدر یک مدل رگرسیون با داده مطابقت دارد. مربع R به ضریب معین نیز معروف است و میزان واریانس در متغیر هدف که با پیش گو توضیح داده می شود را نشان می دهد. مربع R به صورت زیر محاسبه می شود:
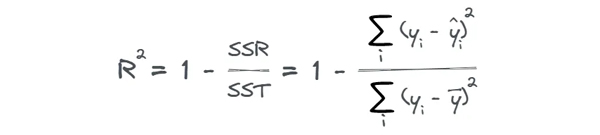
SSR مجموع مربع ماقی مانده، SST مجموع کل مربعات و ȳ مقدار متوسط نمونه است.
بازه ی این معیار از 0 تا 1 است که 0 نشان می دهد مدل، هیچ واریانسی در متغیر(وابسته) هدف ندارد و 1 نشان می دهد که مدل تمام واریانسش را توضیح می دهد. پس می توانیم نتیجه بگیریم که هرچه معیار R2 بزرگتر باشد مدل با داده ی تحت بررسی مطابقت بیشتری دارد. با استفاده از نمونه داده بالا، نمره ی R2 در واقع مقدار NaN می شود زیرا مقادیر واقعی مان ثابت هستند و SST را صفر می کند.
ناگفته نماند که در عمل، ممکن است R2 منفی شود. این اتفاق زمانی می افتد که مدل بدتر از یک خط افقی ساده (میانگین متغیر هدف) عمل کند. به عبارت دیگر یعنی پیش بینی های مدل حتی بدتر از میانگین متغیر هدف به عنوان یک پیش بینی برای همه ی مشاهدات باشد.
مثال: R2 غالبا به عنوان معیار ارزیابی در کمپین های بازاریابی به کار برده می شود. با استفاده از آن، کمپانی ها می توانند ارتباط میان میزان سرمایه گذاری روی تبلیغات و نتیجه ی آن روی افزایش فروش خود را تحلیل کنند و اثربخشی شان را اندازه گیری کنند. R2 بیشتر نشان می دهد که ارتباطی قوی میان سرمایه گذاری روی تبلیغات و میزان فروش وجود دارد یعنی کمپین بازاریابی در میزان فروش کاملا موثر بوده است.
میانگین درصد خطای مطلق Mean Absolute Percentage Error (MAPE)
متوسط درصد خطای مطلق یا MAPE اغلب برای اندازه گیری صحت یک مدل پیش گو مورد استفاده قرار می گیرد. متوسط درصد خطای مطلق، متوسط درصد مطلق تفاوت میان مقادیر واقعی و مقادیر پیش بنی شده را اندازه می گیرد. MAPE به صورت زیر محاسبه می شود:
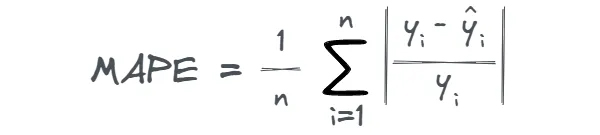
خروجی MAPE غیر منفی است. 0 بهترین مقدار ممکن است و نشان می دهد که مدل بهترین پیش بینی را بدون هیچ خطایی انجام می دهد.
با توجه به نمونه داده ی بالا، MAPE ، 0.2 می شود که نشان می دهد به طور متوسط پیش بینی ها تا 20% اشتباه است.
مثال: اغلب از معیار MAPE در حوزه ی مالی استفاده می کنند. در این حوزه درصد تغییر پیش بینی از مقدار مطلق پیش بینی مهم تر است. برای مثال، پیش بینی قیمت سهام یا نرخ ارز شامل تغییر درصد پیش بینی است تا مقادیر مطلق؛ در این شرایط، MAPE می تواند به عنوان یک معیار ارزیابی مناسب به کار رود.
نتیجهگیری
برای ارزیابی مدل رگرسیونی خود از چند معیار استفاده کنید زیرا هر معیار نقاط ضعف و قوت خود را دارد. با این رویکرد، نمای کلی تری از عملکرد مدل از نظر دقت، مقاوم بودن و ثبات خواهید داشت.
اگر واحد معیار خطا با متغیر هدف یکسان باشد، نمره ی MAE و RMSE را باید مد نظر قرار دهید. اما RMSE و MSE در مقایسه با MAE نسبت به داده های پرت حساس تر هستند. معیار R2 برای ارزیابی مطابقت کلی مدل با داده های تحت بررسی مناسب است اما هیچ اطلاعاتی در مورد پیش بینی های تکی در اختیار ما قرار نمی دهد. در آخر، MATE معیاری است که به راحتی قابل تفسیر است و بیشتر برای مسائل پیش بینی استفاده می شود زیرا شاخصی است که نشان می دهد چند درصد از پیش بینی ها اشتباه است.
تصمیم گیری در مورد اینکه کدام معیار(ها) برای ارزیابی یک مساله رگرسیون باید انتخاب شوند به فاکتورهای زیادی بستگی دارند. باید ببینیم آیا جریمه خطای بزرگتر نسبت به خطای کوچکتر مساله ی ماست یا موضوع قابل تفسیر بودن معیار برای کاربر و مدیر.
دوره های مرتبط

شناسایی الگو (فصل پنجم): یادگیری جمعی (Ensemble learning)

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
دیدگاه ها