
چهار مرحله برای یافتن مدل یادگیری عمیق مناسب
- دسته:اخبار علمی
- هما کاشفی
چطور از اشتباهات مبتدیان یادگیری عمیق اجتناب کنیم؟
اگر به دنبال آن هستید که تسک خود را با مدلهای مبتنی بر یادگیری ماشین پیادهسازی کنید، احتمالاً متوجه شدهاید که مدلهای یادگیری ماشین و پیادهسازیهای زیادی وجود دارند که ممکن است مناسب با تسک شما نباشند. به خصوص اگر با مدلها آشنایی کافی نداشته باشید، پیدا کردن مدل مناسب برای پروژه میتواند کاری طاقت فرسا باشد. در این مقاله، چهار مرحله که باید هنگام انتخاب مدل خود در نظر داشته باشید را بررسی کردهایم.
1-حوزهی مسئلهی خود را به خوبی درک کنید

برای مثال ممکن است یک موقعیتیاب بسازید که هات داگ را در تصویر پیدا کند، اما آن مدلی که به دنبال آن بودهاید تنها وظیفهاش موقعیتیابی هات داگ در تصویر نباشد. مسئلهی موقعیتیابی هات داگ یک مسئلهی “Object Detection” است که زیرمجموعهای از حوزهی “Computer Vision” است. در واقع دیتاستهایی نیز موجود هستند که تک تک اشیا داخل تصاویر را شناسایی کردهاند و دور آن اشیا مستطیلهایی به نام “Bounding Box” رسم کردهاند، دیتاست COCO یکی از آنهاست.
زمانی که به مسئلهی خود فکر میکنید، سادهترین راه برای ترجمهی آن به اصطلاحات مناسب یادگیری ماشین آن است که در مورد ورودیهای خود فکر کنید. ورودی متن است یا تصویر؟ اگر ورودی شما متن باشد معمولاً به حوزهی پردازش زبان طبیعی (NLP) مربوط میشود و اگر تصویر باشد مربوط به حوزهی بینایی ماشین (CV) است. حال در این مرحله باید درک عمیقتری از مسئلهی خود پیدا کنید تا ببینید چه مسائل فرعی وجود دارند مثلاً طبقهبندی احساسات در NLP. علاوه بر این میتوانید دیتاستهایی که از قبل وجود دارند را بررسی کنید. گاهی اوقات ممکن است این روند برای شما طولانی شود، بنابراین استفاده از ابزار جستجوی مدل یادگیری ماشین کاربرپسند مانند ModelDepot میتواند به شما کمک کند تا مدل مناسب خود را سریع پیدا کرده و آن را استفاده کنید.
2-پیدا کردن دقت «مناسب»

ممکن است برای شما کاملاً بدیهی باشد که دقت، مولفهای است که باید به آن بسیار اهمیت دهید اما شما نباید به هر دقتی به سادگی اعتماد کنید و در اینصورت پایان بدی برای شما خواهد داشت. هنگام فکر کردن به دقت مسئله باید چندین نکته را در نظر داشت.
متریک دقت
بسته به این که مسئلهای که میخواهید حل کنید چیست، متریکهای مختلفی وجود دارند. هر حوزهی مسائل تخصصی در یادگیری ماشین دارای مجموعهای از متریکهای استاندارد مرتبط است. بسیار مهم است که بفهمید کدام معیارها برای شما مهم هستند!
برای مثال، اگر در حال ساختن یک سیستم تشخیص تقلب در کارتهای اعتباری هستید و فقط پیش بینیهای درست/همهی پیش بینیها را در نظر گرفته بودید، میتوانید به سادگی مدلی ایجاد کنید که همیشه «غیرتقلب» را با دقت 99 درصد برمیگرداند زیرا بیشتر تراکنشها تقلب نیستند! بنابراین مهم است که متریک مناسب را برای کار خود انتخاب کنید!
دقت گزارش شده
دقت گزارش شده، شروع خوبی برای درک آن است که آیا یک مدل الزامات کار شما را تأمین میکند یا خیر. تقریباً همیشه مقالهی اصلی مدل، متریکهای دقت را برای مدل شما گزارش خواهد کرد. مطمئن شوید که ارتباط معیار آن مقاله را با معیاری که خود استفاده کردهاید را درک کردهاید. اما همچنین باید درک کنید که دیتاست آنها ممکن است با تسکی که شما در دست دارید متفاوت باشد و بهبود دقت 2% شما ممکن است در نهایت اهمیت چندانی برای مسئله شما نداشته باشد.
دقت خودتان
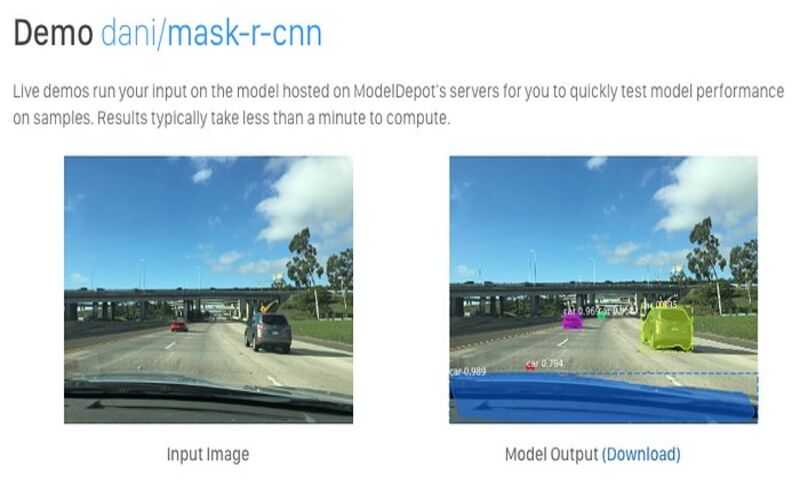
اگر مدلی را پیدا کردید که به نظر میرسد متریکهای دقت گزارش شدهی معقولی دارد، بهتر است خودتان هم آن مدل را آزمایش کنید تا ببینید مدل چقدر برای شما خوب عمل میکند. در حالت ایدهآل، یک مجموعه داده تست از ورودیها دارید که انتظار دارید مدلتان روی این دیتاست خوب عمل کند و خروجی شبیه به خروجیهای از قبل تعیین شده بدهد. آزمایش مدل بر روی دادههای خودتان، بهترین راه برای اطمینان یافتن از عملکرد مناسب مدل است، اگرچه پرزحمتترین راه نیز هست!
راههای خاصی برای بررسی سریع مدلهای دمو “Demo” یا نمایشی وجود دارد برای مثال استفاده از ویژگی دمو آنلاین ModelDepot. میتوانید به سرعت ورودیها را به مدل بدهید و نتیجه را کمتر از یک دقیقه ببینید. همچنین میتوانید این مدل را در محیطهای آنلاین مانند Google Colab امتحان کنید تا دیگر نیاز نباشد که یک محیط جدید نصب کنید.
3-دیتای خود را بشناسید
بسته به میزان دادهای که در اختیار دارید یا میخواهید جمع آوری کنید، رویکرد شما برای یافتن مدلها بسیار متفاوت خواهد بود! ساختن مدل از ابتدا تنها رویکرد نیست و در واقع بسته به دادههای شما ممکن است بدترین رویکرد نیز باشد! بیایید چند مورد را با هم بررسی کنیم.
دادههای زیادی دارم
اگر دادههای آموزشی زیادی در دست دارید، میتوانید به دنبال مدلهایی باشید که اسکریپتهای آموزشی آنها به راحتی در دسترس هستند و به این ترتیب میتوانید مدل خود را از ابتدا آموزش دهید. همگرا کردن مدلهای یادگیری عمیق ممکن است بسیار دشوار باشد برای آنکه کار را برای خودتان راحتتر کنید بهتر است به دنبال پروژههایی در Github باشید. داشتن یک جامعهی حامی برای یک مدل میتواند کمک زیادی به شما کند.
مقداری داده در اختیار دارم
اگر فقط مقداری داده در اختیار دارید، ممکن است بتوانید از تکنیک آموزشی به نام «یادگیری انتقالی» یا “Transfer Learning” استفاده کنید. یادگیری انتقالی به شما این امکان را میدهد تا یک مدل پیش آموزش دیده را در یک دامنهی مشابه انتخاب کنید و مدل را تنظیم کنید تا این مدل حتی برای میزان دادهی اندکی که در اختیار دارید مناسب باشد. اگر به دنبال مدلهای پیش آموزش دیده هستید که به راحتی قابل تشریح و آموزش مجدد هستند، میتوانید برخی از آنها را در Tensorflow Hub یا Keras Applications پیدا کنید.
فقط تعداد انگشت شماری داده در اختیار دارم
جای نگرانی نیست! در اختیار داشتن تعداد انگشت شماری نمونه، شروع خوبی است. به دنبال مدلهایی بگردید که منحصراً از قبل آموزش داده شدهاند و از نمونههای خود به عنوان «مجموعه داده تست» استفاده کنید تا عملکرد مدلها را روی دادههای خود ارزیابی کنید. خوشبختانه ابزارهای زیادی هستند که میتوانید برای بررسی مدلهای پیش آموزش دیده از آنها استفاده کنید مانند Model Zoo برای فریم ورکهای مختلف: Tensorflow, Caffe, ONNX, PyTorch. همچنین ModelDepot واسط جستجوی کلی برای مدلهای از پیش آموزش دیده ارائه میدهد تا به انتخاب مدل مناسب کمک کند.
4-معماری مدل را انتخاب کنید
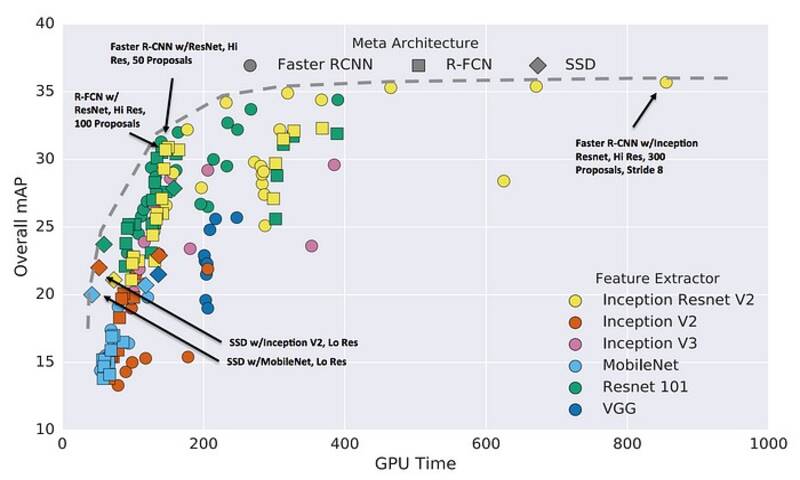
حال میتوانیم معماری مدلها را بررسی کنیم اگر 1)مدلها دقت قابل قبولی روی دیتای شما داشته باشند و 2)به راحتی قابل آموزش مجدد باشند یا بتوان از مدلهای پیش آموزش دیده استفاده کرد.
دقت، سرعت و اندازه
یکی از بزرگترین ملاحظات عملی، میزان سرعت در مقابل دقت است. محققان طیف وسیعی از معماریها را توسعه دادهاند تا کاربرد اپلیکیشنها را در دنیای واقعی بررسی کنند. برای مثال، شاید مدل شما قرار است روی یک تلفن همراه با محدودیت محاسباتی اجرا شود، بنابراین ممکن است به دنبال معماری MobileNet سبک و سریع باشید. در غیر اینصورت، اگر محدودیت محاسباتی ندارید اما میخواهید بهترین دقت را داشته باشید، میتوانید به دنبال جدیدترین معماریها باشید که بهترین دقتها را به شما میدهند و صرفنظر از اینکه مدل چقدر کند یا بزرگ است پیش بروید.
ممکن است برخی از مدلها، نسخههای سبکوزن تری هم داشته باشند مانند PSPNet50 در مقابل PSPNET که تعداد لایهها را کاهش داده است تا سریعتر شود. در مواقع دیگر میتوانید از تکنیکهایی چون هرس یا کوانتیزاسیون استفاده کنید که مدل را کوچکتر و سریعتر میکند.
انجام شد!
با این چهار مرحله میتوانید مسئلهی خودتان را حل کنید یا تعداد اندکی مدل انتخاب کنید که به بهترین وجه و در سریعترین زمان مسئلهی شما را حل کنند. ملاحظات دیگری چون فریم ورک یادگیری ماشین، کیفیت کد یا شهرت سازندهی مدل نیز میتوانند به شما کمک کنند.
شما برای انتخاب مدل مناسب چه راهکار دیگری پیشنهاد میکنید؟
دوره های مرتبط
دوره جامع و پروژه محور شبکه عصبی کانولوشنی (Convolutional Neural Network)

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین
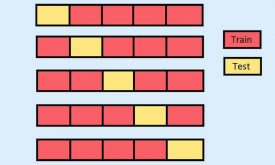
شناسایی الگو: روشها و پارامترهای ارزیابی مدلهای یادگیری ماشین(فصل سوم)

دیدگاه ها