
چطور ویژگی استخراج کنیم؟
در این بخش میخواهیم مسئله اطلاعات مشترک رو بررسی کنیم. اطلاعات مشترک اطلاعاتی هستند که در پروژههای شناسایی الگو برای الگوریتمهای یادگیری ماشین گمراه کننده هستند و کار تصمیم گیری را برای این الگوریتمها دشوار میکنند. میخواهیم در این جلسه نگاهی به این اطلاعات مشترک داشته باشیم و با یک مثال ساده توضیح دهیم که این اطلاعات چی هستند و چطور میتوان تاثیر آنها را در پروسه استخراج ویژگی و تصمیم گیری حداقل کرد.
استخراج ویژگی هدفمند،حذف اطلاعات مشترک درد ساز!
اجازه بدهید با یک مثال ساده بحث رو شروع کنیم… در شکل زیر تفاوت دو تصویر را پیدا کنید!
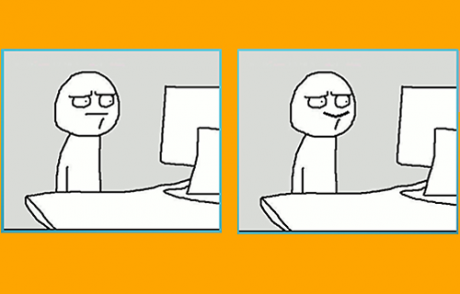
خب می بینیم که پیدا کردن تفاوت این دو تصویر چندان هم برای ما سخت نبود و خیلی ساده تفاوت دو تصویر را پیدا کردیم!
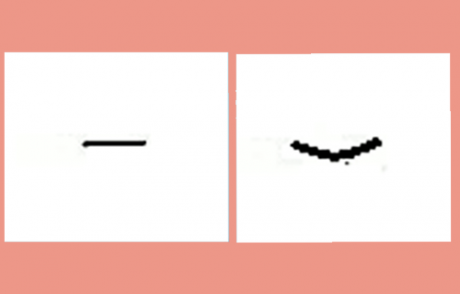
حالا مسئله رو پیچیده تر کنیم! حال در دو تصویر زیر اختلافها را پیدا کنید.

میبینیم که داره سخت میشه و باید کلی بگردیم تا این تفاوتها را پیدا کنیم و دو تصویر رو براساس همین تفاوت ها از هم تفکیک کنیم! حالا فرض کنید این کار رو بخواهیم با الگوریتمهای یادگیری ماشین انجام بدیم!
پیدا کردن این تفاوتها به قدری که برای ما ساده هست برای مدلهای یادگیری ماشین ساده نخواهد بود و الگوریتم با یک چالش بسیار سختی روبرو خواهد شد! حالا وظیفه ما این وسط چیه؟ چه کمکی میتونیم به الگورتیمها بکنیم تا کار تصمیم گیری براشون سخت نباشه؟
حذف اطلاعات گمراه کننده
مدلهای یادگیری ماشین خیلی خنگ هستند و به راحتی یاد نمیگیرند! وظیفه ما اینه که کار رو براشون راحت بکنیم!
چطوری! حذف اطلاعات مشترک!
در مثال اول به جای اینکه کل بخشهای دو تصویر رو به الگوریتم بدهیم، فقط بخشهایی که احتمال میدهیم دو تصویر باهم اختلاف دارن را به الگوریتم ارائه دهیم!
حالا می بینید که چقدر کار االگوریتم راحت شد؟
ما در انجام پروژهها همچین وظیفه ای داریم و باید اطلاعاتی که مهم هستند رو نگه داریم و بقیه رو حذف کنیم که کار تصمیمگیری رو برای طبقه بند راحت بکنیم!
اجازه بدهید با یک مثال ساده تری موضوع رو بررسی کنیم، فرض کنید که در یک کارخانهای از شما خواستهاند که سیستمی طراحی کنید که بتواند به طور خودکار ماهی Salmon و seabass رو از هم تفکیک کند و در بسته خودشون قرار دهد.

خب همچین پروژهای رو میتونیم در قالب یک پروژه شناسایی الگو انجام دهیم که از مراحل زیر تشکیل میشود:
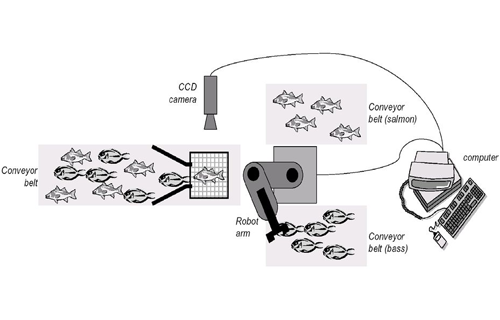
میتوانیم که یک دوربین قرار دهیم و این دوربین تصویر ماهی را ثبت کند و به بدهد به کامپیوتر که با تجزیه و تحلیل تصویر ماهی را شناسایی کرده و در دسته سالمون یا سیباس قرار دهد.
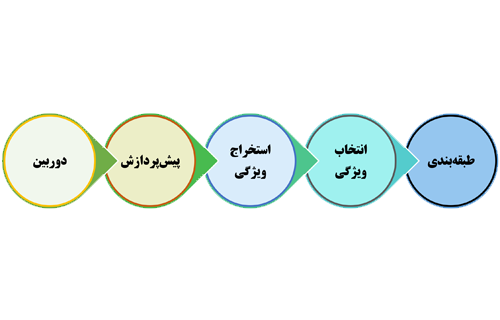 کار تصمیم گیری را در این سیستم طبقه بند انجام میدهد، و لازم است که به ازای هر تصویر ورودی تعدادی ویژگی استخراج کنیم و به عنوان نماینده تصویر به طبقهبند بدهیم تا براساس مقادیر آنها طبقه بند تشخیص دهد که تصویر ورودی مربوط به چه کلاسی هست!
کار تصمیم گیری را در این سیستم طبقه بند انجام میدهد، و لازم است که به ازای هر تصویر ورودی تعدادی ویژگی استخراج کنیم و به عنوان نماینده تصویر به طبقهبند بدهیم تا براساس مقادیر آنها طبقه بند تشخیص دهد که تصویر ورودی مربوط به چه کلاسی هست!
خب لازم است که ما ویژگی(پارامترهای قابل اندازهگیری) از تصاویر استخراج کنیم و به طبقه بند ارائه دهیم!
الان سوال این است که ما از کجای تصویر و چه پارامتری از تصویر استخراج کنیم!
میبینیم که رنگ پوست ماهی ها باهم متفاوت است و اگر بتوانیم رنگ سطح پوست ماهی ها را اندازه گیری کنیم براساس مقدار رنگ مدل میتواند ماهی را شناسایی کند!
ولی سوال این است که من رنگ سطح پوست ماهی را چطوری محاسبه کنم؟
هر تصویر از تعدادی پیکسل تشکیل شده که هر کدام یک مقداری عددی دارند که نوع رنگ رو مشخص میکند.
راه اول: میتوانیم از تمام مقدار تمام پیکسلهای تصویر میانگین بگیریم و به عنوان رنگ تصویر ماهی ها استفاده کنیم!
اگر به این شکل عمل کنیم، احتمالا ویژگی درگروه یک و گروه دو همچین توزیعی خواهد داشت!
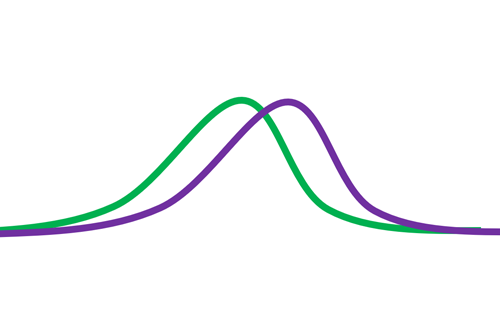
و اگر طبقه بند بخواهد براساس مقدار این ویژگی تصمیم بگیرید خطای زیادی خواهد داشت!
چرا؟ مگه رنگ ماهی ها باهم متفاوت نبود! پس چرا ویژگی رنگ نتوانست مناسب باشد!
دلیل این کار هست که ما به خوبی نتوانستیم مقدار این ویژگی را استخراج کنیم! و مسئله این است که باید بدانیم از کجای تصویر ویژگی استخراج کنیم!
اجازه بدهید مسئله را ساده تر بکنیم و ببینیم تصویر ورودی از چه اطلاعاتی تشکیل شده است!

تصویر از دو بخش تشکیل شده است، پس زمینه و ماهی! پس زمینه بخش بزرگی از اطلاعات تصویر را تشکیل داده است و در هر دو گروه تقریبا یکسان هست. و موقع استخراج ویژگی بخش پس زمینه تصویر عمده ترین تاثیر را در محاسبه ویژگی رنگ دارد. و چون در هر دو گروه یکسان هست باعث میشود که ویژگی مقدار تقریبا یکسانی در دو گروه داشته باشد!
در این مثال، پس زمینه اطلاعات مشترک بین دو گروه هست و اطلاعاتی که در این مسئله ارائه میدهد هیچ کمکی به ماشین در تفکیک دو کلاس ارائه نمیدهد!
یعنی اگر ما فقط اطلاعات پس زمینه دو تصویر را استفاده کنیم متوجه نخواهیم شد که ماهی مربوط به کلاس یک هست یا دو!

راه چاره چیه؟ حذفشون کنیم؟
باید در محاسبه ویژگی، تنها از بخشهایی استفاده کنیم که مربوط به ماهی هست! به عبارتی باید از اطلاعاتی در محاسبه ویژگی استفاده کنیم که مربوط به مسئله هستند و مهم!
پس در ابتدا قبل اینکه وارد مرحله استخراج ویژگی بشویم، اطلاعات مشترک، اطلاعاتی که در گروههای مختلف یکسان هست را حذف میکنیم!
مثلا در این پروژه ناحیه بندی انجام میدهیم و بخش مربوط به ماهی را از تصویر جدا می کنیم و بعد وارد استخراج می شویم.

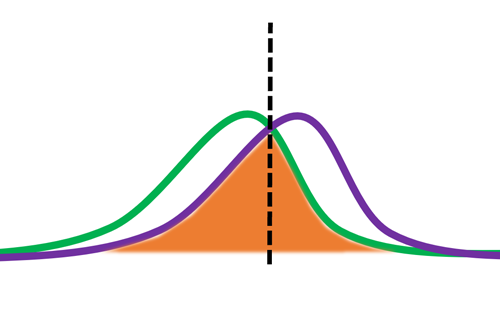
حال اگه بیاییم در هر دو تصویر فقط از قسمتهایی که مربوط به ماهی هست ویژگی رنگ را استخراج کنیم، احتمال ویژگی همچین توزیع در هر دو گروه خواهد داشت!
میینیم که ویژگی مقدار متفاوتی در دو گروه داره و اگر بنا باشد الگوریتم تنها باز روی مقدار این ویژگی تصمیم گیری کند، به احتمال زیاد دقت بالایی خواهد داشت.
در یک پروژه شناسایی الگو ورودی لزوما تصویر نیست و میتونه یک سیگنال مغزی، یا سیگنال قلبی یا صوت و غیره باشه!
حال اونجا چجوری اطلاعات مشترک را حذف کنیم؟!
در همه مسائل ما اطلاعات مشترک داریم و به نوعی باید از دستشون خلاص شویم…
یک راه اینه که در ابتدا یک شناخت درستی از مسئله داشته باشیم و اطلاعاتی که مربوط به مسئله هست رو شناسایی کنیم و بعد با کمک روشهای پیش پردازش مثل فیلترینگ اطلاعات غیر مفید و مشترک را حذف کنیم و تنها اطلاعاتی رو نگه داریم که مربوط به مسئله مورد نظر است.
نتیجه گیری:
مثالی که زدیم صرفا جهت درک بهتر اطلاعات مشترک هست و در در عمل ممکن است مسئله ای به این سادگی نداشته باشیم. هدف ما استخراج ویژگی از داده ورودی هست تا طبقه بند بتواند با کمک این ویژگی داده رو دسته بندی کند.
ما باید ویژگیهایی استخراج کنیم که مقدار متفاوتی در گروههای مختلف داشته باشد و برای اینکه بتوانیم ویژگی مناسب استخراج کنیم، بهتر است از اطلاعاتی در محاسبه ویژگیها استفاده کنیم که مربوط به مسئله باشد و همچین مربوط به اطلاعاتی باشد که دو تا یا چند گروه در اون بخش از اطلاعات باهم تفاوت داشته باشند و وقتی از این اطلاعات ویژگی استخراج میکنیم منجر به استخراج ویژگیای شود که مقدار متفاوتی در گروههای مختلف دارد.
اطلاعات مشترک، اطلاعاتی که در گروه های مختلف یکسان است رو باید در همان ابتدا در بخش پیشپردازش حذف کنیم.
در دورهی جامع پردازش سیگنال مغزی(EEG)، دوره پردازش سیگنال EEG مبتنی بر تصور حرکتی و دوره پردازش سیگنال EEG مبتنی بر SSVEP این مسئله رو همیشه در نظر گرفتیم و در هر مسئله با شناختی که به آن داشتیم اطلاعات مشترک رو حذف کردیم و به طور عملی اثبات کرده ایم که حذف اطلاعات نامرتبط و مشترک چقدر میتواند در عملکرد نهایی تاثیر مثبتی بگذارد.
در این بخش میخواهیم مسئله اطلاعات مشترک رو بررسی کنیم. اطلاعات مشترک اطلاعاتی هستند که در پروژههای شناسایی الگو برای الگوریتمهای یادگیری ماشین گمراه کننده هستند و کار تصمیم گیری را برای این الگوریتمها دشوار میکنند. میخواهیم در این جلسه نگاهی به این اطلاعات مشترک داشته باشیم و با یک مثال ساده توضیح دهیم که این اطلاعات چی هستند و چطور میتوان تاثیر آنها را در پروسه استخراج ویژگی و تصمیم گیری حداقل کرد.
دوره های مرتبط
پردازش سیگنال مغزی(EEG)

پردازش سیگنال EEG مبتنی بر تسک تصور حرکتی
واسط مغز-کامپیوتر مبتنی بر SSVEP

پکیج جامع شناسایی الگو و یادگیری ماشین( فصل های اول تا چهارم- از بیزین تا SVM)

[…] زیادی در نتیجه نهایی میگذارند. در جلسه قبل در مورد اهمیت پیش پردازش و حذف اطلاعات مشترک صحبت کردیم، حال در این بخش میخواهیم اهمیت feature conditioning […]
[…] که قبلا در بخش “چطور ویژگی استخراج کنیم ” هم گفتهایم، سیگنال ثبت شده علاوه بر اطلاعات […]