مفهوم Early Stopping در یادگیری عمیق
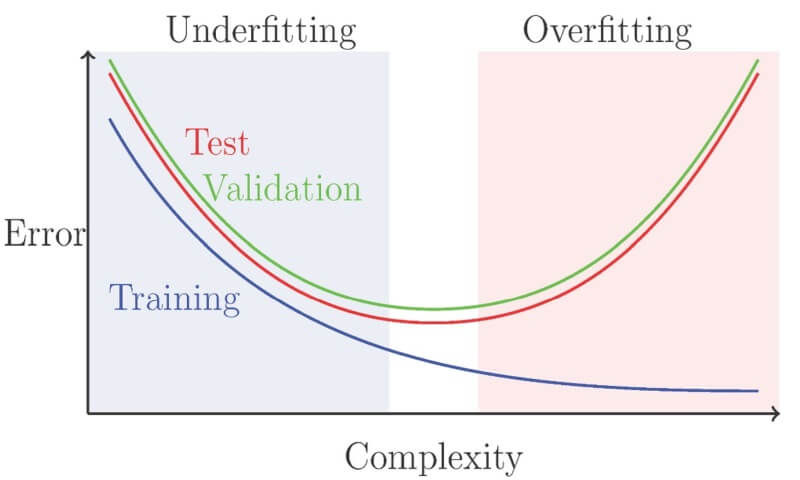
بیش برازش (Overfitting) یکی از بزرگترین چالشها در یادگیری ماشین است مخصوصا زمانی که مدل آموزش دیده، به جای یادگیری الگوهای عمومی از دادهها، فقط به جزئیات و نویزهای موجود در دادههای آموزشی وابسته میشود. این امر سبب میگردد که مدل در دادههای جدید یا تست عملکرد خوبی نداشته باشد. با افزایش تعداد پارامترها و پیچیدگی مدلها، احتمال Overfitting نیز بیشتر میشود و تکنیکهای کلاسیک ممکن است به تنهایی کافی نباشند و باید در ترکیب با استراتژیهای دیگری مانند Early Stopping مورد استفاده قرار گیرند تا به نتایج بهتری منجر شوند. در این پست در مورد سومین تکنیک generalization یعنی Early Stopping صحبت میکنیم که سعی دارد برای مدلهایی که احتمالاً به سمت Overfitting میروند، آموزش را متوقف کند.
نقش Early Stopping در Generalization مدلهای یادگیری عمیق
این متن به بررسی یک پدیده جالب در یادگیری عمیق میپردازد که به “نوعی از توقف زودهنگام” مربوط میشود. شبکههای عصبی عمیق توانایی یادگیری و تطبیق با برچسبهای دلخواه حتی برچسبهای نادرست یا تصادفی را دارند. به این معنی که اگر شما به شبکه دادههای آموزشی بدهید که برچسبهای آنها اشتباه هستند، این شبکه میتواند آن برچسبها را نیز یاد بگیرد. این توانایی معمولاً تنها در طی چندین مرحله آموزش ایجاد میشود. این نشان دهندهی تأثیر تکرار در فرآیند آموزش است. تحقیقات اخیر نشان دادهاند که در مواردی که دادهها دارای نویز برچسب باشند، شبکههای عصبی ابتدا برچسبهای صحیح (تمیز) را به خوبی یاد میگیرند و سپس به سراغ برچسبهای نادرست میروند. از اینرو، اگر یک مدل بتواند برچسبهای صحیح و تمیز را شناسایی کند اما شرایط آموزش را به گونهای مدیریت نمائیم که مانع از یادگیری برچسبهای تصادفی شویم، این پدیده میتواند نوعی تضمین در مواجهه با دادههای جدید، برای generalization محسوب گردد.
Early Stopping ، یک تکنیک کلاسیک برای تنظیم و بهبود عملکرد شبکههای عصبی عمیق است. بهجای اینکه به طور مستقیم، مقادیر وزنها را محدود کنیم، تعداد دورههای آموزشی (epochs) را محدود میکنیم. یکی از روشهای رایج برای تعیین زمان توقف، نظارت بر خطای اعتبارسنجی (validation error) در طول آموزش است. معمولاً این کار بعد از هر دوره آموزشی انجام میشود و وقتی که خطای اعتبارسنجی برای چند دوره متوالی (با یک مقدار کوچک ε) کاهش نیافت، آموزش متوقف میشود.
دو مورد از مزایای مهم استفاده از تکنیک توقف زودهنگام
- این تکنیک میتواند به بهبود generalization به ویژه در شرایطی که برچسبها دارای نویز هستند، موثر باشد.
- کنترل تعداد epochها در فرآیند آموزش مدل، به ویژه برای مدلهای بزرگ که ممکن است نیاز به روزها آموزش در چندین GPU داشته باشند، بسیار مهم است. با تنظیم صحیح پارامترها در این تکنیک، محققان قادر به مدیریت بهتر زمان خواهند بود.
اما آیا همواره روی تمام مدلها، این تکنیک میتواند اثر مثبتی داشته باشد؟
هنگامی که دادهها نویز ندارند و کلاسها به طور واقعی قابل تفکیک هستند (مثل تشخیص گربهها از سگها)، توقف زودهنگام معمولاً به بهبود قابل توجهی در generalization منجر نخواهد شد. اما در شرایطی که نویز در برچسبها وجود دارد یا تغییرات ذاتی در برچسبها وجود دارد (مثل پیشبینی مرگ و میر در بیماران)، توقف زودهنگام بسیار حیاتی است زیرا آموزش مدلها تا زمانی که حتی به دادههای نویزدار تطبیق پیدا کنند، نمیتواند ایده قابل قبولی باشد.
نحوه عملکرد این تکنیک چگونه است؟
پس از صحبت در مورد فلسفه یا همان چرایی وجود این تکنیک، نوبت آشنایی با نحوه چگونگی اعمال این تکنیک است. بدینمنظور، بد نیست اشارهای داشته باشیم به یک روش مرسوم در تقسیم دیتاست به دادههای آموزش و تست. بطور معمول، پیش از شروع فرآیند آموزش مدل، یکی از گامها، تقسیم دیتاست به دو دسته داده آموزش و دادهی تست میباشد که از داده آموزش به منظور آموزش مدل، و از داده تست هنگام ارزیابی مدل استفاده میشود. اما یک راهکار بهتر که نزد کارشناسان این حوزه معقولتر نیز بهنظر میرسد، این است که بعد از تقسیم دیتاست به داده آموزش و تست، یک تقسیم بندی دیگر روی دادهآموزش انجام شود. در واقع در این رویکرد، خود داده آموزش، دوباره به دو دسته داده آموزش و ارزیابی تقسیم میگردد. اینگونه، تقسیم کل داده ها به سه زیر مجموعه اصلی انجام خواهد شد: آموزش، اعتبار سنجی و مجموعه تست. بزرگترین زیر مجموعه، مجموعه دادههای آموزشی است. ما از آن برای آموزش مدل استفاده میکنیم. به این معنی که وزنها در مسیر backpropagation با هدف رسیدن به بهترین عملکرد، بهروزرسانی میشوند. با مجموعه اعتبارسنجی، ما مجاز به انجام ارزیابی در هر تکرار، در فرآیند یادگیری مدل هستیم. مدل، از مجموعه داده های اعتبار سنجی یاد نمیگیرد، تنها به کمک آن، نتیجه آموزش را میبیند. گاهی اوقات به مجموعه اعتبارسنجی، مجموعه توسعه نیز گفته میشود. در نهایت، مجموعه دادههای تست هستند. این زیر مجموعه، برای ارزیابی از مدل نهایی برازش شده (آموزش داده شده) در مجموعه دادههای آموزشی مورد استفاده قرار میگیرد. ما از مجموعه دادههای تست، فقط یک بار استفاده میکنیم آن هم زمانیکه، مدل ما کاملاً آموزش داده شده باشد. شکل زیر نمایی از این شیوه تقسیمبندی دیتاست است.
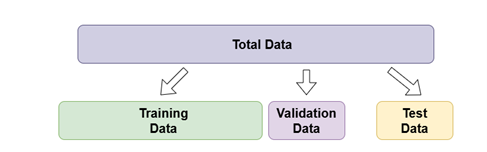
با این توضیحات اینگونه به نظر میرسد که خالق این تکنیک، با اضافه نمودن چند شرط و ایجاد یکسری محدودیت در فرآیند آموزش با تقسیمبندی به شیوه مذکور، توانسته این ایده جالب را به یک رویکرد ساده و محبوب در generalize کردن مدلهای یادگیری عمیق مبدل سازد که در سال 2012 ارائه شد.Early Stopping به طور عمده از طریق نظارت بر عملکرد مدل در مجموعهی اعتبارسنجی (Validation Set) به تعمیمسازی مدل کمک میکند. مراحل اصلی این فرآیند را در چهار مرحله خلاصه میشود:
- تقسیم دادهها: دادهها به سه قسمت یک مجموعه آموزشی و یک مجموعه اعتبارسنجی و یک مجموعه تست تقسیم میشوند.
- آموزش مدل: مدل بر روی مجموعه آموزشی آموزش دیده و در هر دوره (Epoch) عملکرد آن بر روی مجموعه اعتبارسنجی بررسی میشود.
- نظارت بر عملکرد: بعد از هر دوره، عملکرد مدل (معمولاً با استفاده از یک معیار مانند دقت یا خطا) بر روی مجموعه اعتبارسنجی محاسبه میشود.
- متوقف کردن آموزش: اگر عملکرد بر روی مجموعه اعتبارسنجی در یک تعداد مشخص دوره که به آنpatience criteria یا به اصطلاح “معیار صبر” میگویند بهبود نیابد و میزان خطا افزایش یابد یا معیار کارایی به صورت پیوسته کاهش یابد، آموزش متوقف میشود.
پیاده سازی تکنیک Early Stopping در پایتورچ
در پیادهسازی این تکنیک به کمک کتابخانه پایتورچ، کافیست در بدنه آموزش مدل در هر epoch، حلقه مربوط به تست مدل نیز گنجانده شود و اینگونه، میزان تغییرات در جهت رسیدن به کمترین مقدار در تابع هزینه (افزایش دقت یا کاهش خطا )مانیتور شود. سه پارامتر در این پیادهسازی، به منظور محدود نمودن تکرارها در فرآیند آموزش نقش دارند که ابتدا به معرفی آنها میپردازیم.
Python
patience = 7 best_accuracy = 0.0 early_stop_counter = 0
- patience: این پارامتر تعیین کنندهی تعداد epochهایی است که آموزش میتواند ادامه یابد، بدون اینکه بهبود قابل توجهی مشاهده شود. در این نمونه کد، مقدار این پارامتر 7 درنظر گرفته شد. با تغییر در این پارامتر، میتوان سرعت واکنش به عدم بهبود عملکرد مدل را تنظیم نمود.
- Best_accuracy : به منظور ذخیره بهترین دقت مشاهده شده در طول آموزش، براساس معیار accuracy از این پارامتر ستفاده میشود. به کمک این پارامتر، میتوان مشخص نمود که آیا مدل در حال بهبود است یا خیر. در ابتدای آموزش، مقدار این پارامتر را معمولاً به بینهایت (np.inf) یا مقدار 0 تنظیم میکنیم که نشاندهنده این است که هنوز هیچ امتیاز بهتری مشاهده نشده است. در طول هر دوره آموزش، در صورت بهبود امتیاز نسبت به مقدار دوره قبل(یا اولیه)، این مقدار به روز میشود، بدون آنکه تغییری در مقدار پارامتر سوم (early_stop_counter) ایجاد نمائیم.
- early_stop_counter: این پارامتر به شمارش تعداد دورههایی که در آنها هیچ بهبودی بر حسب معیار مورد نظر مشاهده نشده، اختصاص داده میشود. از روی این پارامتر، امکان تعیین این موضوع را فراهم میشود که آیا زمان آن رسیده که آموزش متوقف شود؟ اگر شمارنده به یک مقدار خاص (که با متغیر patience مشخص میشود) برسد، آموزش متوقف میشود. هر بار که امتیاز فعلی بهتر از Best_accuracy نباشد، مقدار شمارنده یک واحد افزایش مییابد. در صورت مشاهدهی یک امتیاز بهتر، شمارنده به صفر برمیگردد. هنگامیکه شمارنده به مقدار تعیین شده در پارامتر patience (تعداد حداکثر مجاز دورههای بدون بهبود) برسد، آموزش متوقف میشود.
در واقع، Best_accuracy به ما کمک میکند تا بهترین عملکرد موجود را نگه داریم، در حالی که early_stop_counter به ما میگوید که آیا مدل در حال بهبود است یا خیر. با استفاده از این دو پارامتر، میتوانیم از Overfitting جلوگیری و اطمینان حاصل کنیم که مدل تا زمانی که در حال یادگیری است، آموزش ببیند و به محض اینکه از مدار آموزش خارج شد، آموزش متوقف میشود.
در پایان، بخش مربوط به حلقه آموزش یک مدل که از این تکنیک استفاده کرده است، به عنوان نمونه ارائه شده است.
Python
# Training NN patience = 5 best_accuracy = 0.0 early_stop_counter = 0 for epoch in range(epochs): mdl.train() for i, (xbatch, ybatch) in enumerate(train_loader): xbatch = xbatch.to(device) ybatch = ybatch.to(device) optimizer.zero_grad() ypred = mdl(xbatch) loss = criteria(ypred, ybatch) loss.backward() optimizer.step() # Validation and early stopping with torch.no_grad(): correct = 0 total = 0 mdl.eval() for samples, labels in test_loader: samples = samples.to(device) labels = labels.to(device) outputs = mdl(samples) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = correct / total * 100 if accuracy > best_accuracy: best_accuracy = accuracy early_stop_counter = 0 else: early_stop_counter += 1 print(f'Epoch [{epoch+1}/{epochs}], Test Accuracy: {accuracy:.2f}') if early_stop_counter >= patience: print(f'Early stopping - No improvement in accuracy for {patience} epochs')
تاکنون، در مورد سه تکنیک پرکاربرد در بهبود تعمیمپذیری یک مدل در روشهای یادگیری عمیق، با عناوین Dropout، Batch Normalization و Early Stopping صحبت شده است. در پست بعدی چهارمین و البته آخرین تکنیک generalization یعنی Regularization مورد بررسی قرار خواهد گرفت که با اضافه نمودن یک عبارت جریمه به تابع loss در طول تمرین، مدل را از یادگیری الگوهای بیش از حد پیچیده از روی دادههای train منع میکند. اینگونه مرزهای تصمیمگیری سادهتر و هموارتری میآموزد که بهتر به دادههای دیده نشده تعمیم مییابند.
دوره های مرتبط

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

دیدگاه ها