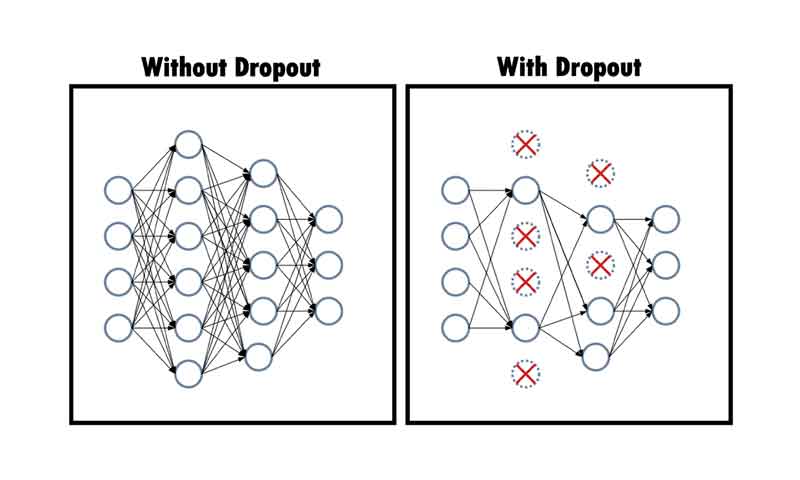
مفهوم Dropout در یادگیری عمیق
یکی از موانع بزرگ در الگوریتم های یادگیری عمیق، Overfitting است که برای مقابله با این پدیده، راهکارهای متعددی تاکنون توسط محققان ارائه شده است که در قالب تکنیکهای Generalization معرفی و در مقالات مورد استفاده قرار میگیرد. در این پست، به بررسی و نحوه پیاده سازی یکی از این تکنیکها با عنوان Dropout میپردازیم که تاثیر زیادی در مقاوم کردن مدل (شبکه های عصبی) طراحی شده در مواجهه با داده های واقعی دارد. در انتها هم توضیح میدهیم که چطور میتوانیم از Droupout در پایتورچ استفاده کنیم.
تعمیم پذیری یا Generalization در یادگیری عمیق
بطور کلی، مراحل آموزش یک مدل به دو بخش تقسیم میگردد. بخش اول مربوط به fit کردن داده های آموزشی است که در این مرحله، مدل به داده های آموزش تطبیق داده میشود و بخش دوم مربوط به ارزیابی مدل بر روی داده های تستی است که تاکنون آنها را ندیده و برآوردی از عملکرد مدل روی داده های واقعی به ما ارائه خواهد کرد. Generalization به گپ یا فاصله بین عملکرد مدل بر روی داده های آموزش و تست اشاره دارد که هرقدر این گپ بزرگتر باشد نشان دهنده این است که مدل به داده های آموزشی بیش از حد تطبیق داده شده است تا حدی که ممکن است مدل روی داده های آموزش بسیار خوب عمل نماید ولی خطای آن روی داده های تست قابل توجه باشد. به این پدیده در الگوریتم های یادگیری Overfitting میگویند.
در واقع Generalization به توانایی یک مدل برای عملکرد خوب بر روی دادههای جدید و دیدهنشده اشاره دارد و پاسخی برای مقابله با پدیده Overfitting است. برای بهبود Generalization یا تعمیم پذیری مدلها، تکنیکهای متعددی تاکنون پیشنهاد شده که از جمله آنها میتوان به موارد زیر اشاره نمود.
- Dropout
- Batch Normalization
- Early Stopping
- Regularization
با توجه به اهمیت دانستن در مورد فلسفه خلق هر یک از این تکنیک ها به همراه نحوه پیاده سازی و بکارگیری آنها در طراحی مدلها ، قصد داریم در هر پست بر روی یکی از این تکنیک ها متمرکز شده و اطلاعاتی را در اختیار دوستداران این حوزه قرار بدهیم.
قبل از توضیح این تکنیک بهتر است اشاره ای به مفهوم Dense layer داشته باشیم که به عنوان لایه کاملاً متصل یا همان Full connection نیز شناخته می شود. نوعی لایه در شبکه عصبی، که در آن هر نورون در لایه، به هر نورون در لایه قبلی متصل است. این بدان معنی است که تمام نورون های ورودی به تمام نورون های خروجی در یک Dense layer متصل هستند. در CNN (شبکه عصبی کانولوشن)، Dense layer ها در انتهای شبکه برای انجام وظایف طبقهبندی بر اساس ویژگیهای استخراجشده توسط لایههای کانولوشنال و پولینگ استفاده میشوند. در ادامه به این موضوع می پردازیم که چه مشکلی در طراحی یک مدل پیش روی ما قرار دارد و راهکار این تکنیک چیست؟
نحوه عملکرد Dropout در مقاوم سازی مدل
درفرآیند Forward propagation، اطلاعات هر نورون در وزن مربوط به همان نورون ضرب، و خروجی هر لایه از مجموع این حاصلضربها بدست می آید. به نوعی میتوان گفت گویی یک ذهن اشتراکی بین نورونها، در پس خروجی هر لایه نهفته است که میتوان گفت نورونهای هر لایه در فرآیند یادگیری، به نوعی همتکاملی یا Co-adaptation دچار میشوند. تکنیک Dropout برای حل این مشکل آمده است.
بدین گونه که، با غیرفعال کردن درصدی از نورونها بهصورت تصادفی، در هر بار آموزش، هر نورون برای یادگیری بیشتر، به ویژگیهای ورودی وابسته می شود نه به ویژگیهای نورونهای دیگر آن لایه. در واقع، در این تکنیک تمرکز روی حساس نبودن مدل به تغییرات کم در ورودی خود است. یعنی در برابر تغییرات کوچک در محیط واقعی، مقاوم و انعطاف پذیر باشد.
این تکنیک شامل تزریق نویز در حین محاسبه هر لایه داخلی در طول Forward propagation است و به یک تکنیک استاندارد برای آموزش شبکه های عصبی تبدیل شده است. این روش به این دلیل Dropout نامیده می شود که ما در حین training برخی از نورون ها را از بین می بریم. در طول آموزش، در هر تکرار، Dropout استاندارد، شامل صفر کردن بخشی از گرهها در هر لایه پنهان قبل از محاسبه لایه بعدی است.
ارائه دهندگان این روش استدلال میکنند ، Overfitting زمانی رخ می دهد که در آن هر لایه به الگوی خاصی در لایه قبلی متکی است و این شرایط را سازگاری همزمان نیز می نامند.
پیاده سازی تکنیک Dropout در پایتورچ
اما سئوالی که در هنگام طراحی یک مدل مطرح می شود این است که در کدام بخش از معماری طراحی شده این تکنیک را بگنجانیم و نحوه پیاده سازی آن چگونه است؟
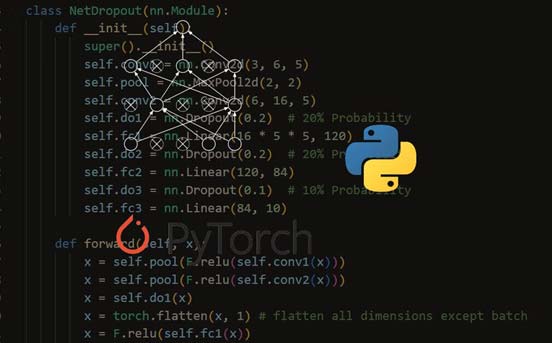
معمولا یک لایه Dropout را بعد از یک Dense layer یا یک Convolutional layers اضافه می کنیم. با حذف برخی از اتصالات بین نورونها در یک Dense layer ، مدل مجبور میشود ویژگیهای قویتر و تعمیمیافتهتری را بیاموزد، زیرا زیرمجموعههای مختلفی از نورونها در طول هر مسیر Forward و Backward استفاده میشوند. ما میتوانیم این تکنیک را برای هر یک از لایه های پنهان یا کانولوشنال قرار بدهیم و برای هر کدام هم احتمال حذف تعداد نورونها را اعداد متفاوتی در نظر بگیریم. اما معمولا اعداد نزدیک به لایه ورودی با احتمال حذف پایینتری مقداردهی میشوند.
اما نکته کلیدی این است که ما قصد داریم عمل Dropout روی داده های آموزش و هنگام آموزش مدل اعمال شود تا مدل مقاوم تری ایجاد شود. از این رو، این کد باید به گونه ای نوشته شود که زمان تست مدل، لایه یا حتی لایه های Dropout تاثیری روی نمونه های تست نداشته باشند و هنگام تست مدل به نحوی این لایه ها نادیده گرفته شوند.
بدین منظور، کتابخانه PyTorch دو متد ارائه کرده است که ما را قادر به سوئیچ کردن میان دو فاز آموزش و تست می نماید.
به کمک متد ()train در ابتدای حلقه آموزش، بصورت خودکار لایه Dropout فعال و با متد ()eval در هنگام تست شبکه، این لایه غیرفعال میگردد.
برای استفاده از این متدها نیز کافیست آبجکت ساخته شده از مدل را به همراه نام این متدها بصورت ()model.train و ()model.eval در ابتدای حلقه آموزش و حلقه تست شبکه فراخوانی نمائیم و بدین ترتیب، رفتار لایه های Dropout را کنترل نموده و با اطمینان بین این دو مد سوئیچ کنیم به گونه ای که در مد آموزش، لایه های Dropout روی نودها عمل میکنند ولی در مد ارزیابی، به منظور پیش بینی دقیق شبکه، غیرفعال میشوند و تاثیری روی نورونهای لایه های Dense/convolution ندارند.
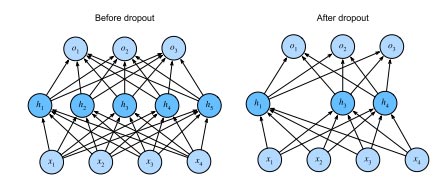
چالش کلیدی نحوه تزریق این نویز است. یکی از روشهای ساده و پرکاربرد، روش Standard dropout regularization است که تعدادی از گره های هر لایه با احتمال p مقدار 0 میگیرند. در شکل 1 نمایی از مفهوم Dropout در MLP یا Dense layer با فرض داشتن یک لایه پنهان با پنج نورون میان لایه ورودی و لایه خروجی نشان داده شده است.
در پایان این بخش، به نحوه پیاده سازی این تکنیک به کمک کتابخانه پایتورچ می پردازیم. برای اعمال این تکنیک در طراحی مدل، باید ابتدا کتابخانه مورد نیاز را بصورت زیر وارد نمائیم:
Python
import torch.nn as nn
سپس به ترتیب، ابتدا Dense layer/Convolutional layer، سپس تابع فعال و بعد از آن Dropout layer قرار میگیرد. به عنوان مثال، یک نمونه آن در هنگام طراحی مدل بصورت Sequentioal() در ادامه نشان داده شده است.
Python
nn.Sequentioal(nn.Linear(), nn.ELU(), nn.Dropout(p=0.5))
در پست بعدی، تکنیک Batch Normalization را مورد بررسی قرار میدهیم که در ورودی هر لایه اعمال و از طریق تغییر مرکز توزیع دیتاها یا تغییر دادن مقیاس آنها، به عنوان یکی دیگر از راهکارهای مورد توجه در تعمیم پذیری مدلهای یادگیری عمیق محسوب میگردد.
دوره های مرتبط

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN
شبکه عصبی PNN (جلسه 10)
شبکه عصبی ELM (جلسه نهم)
شبکه عصبی RBF(جلسه هشتم)
mlp با قانون یادگیری دلتا بار دلتا (جلسه هفتم)

دیدگاه ها