اخبار علمی
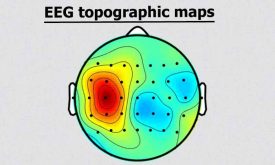





نحوه رسم نقشه توپوگرافی مغزی(EEG topographic maps)
نقشه توپوگرافی مغزی(EEG topographic maps) توزیع مکانی از فعالیت ایجاد شده در سیگنال مغزی(eeg) را برحسب ولتاژ، ویژگی و یا سایر پارامترها نمایش می دهد. نقشه توپوگرافی مغز به ما این امکان را میدهد تا متوجه شویم که در هر…
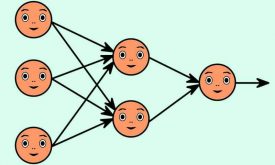
شبکهی عصبی مصنوعی
شبکه های عصبی مصنوعی مدلهای ساده شده ساختارهای مغز هستند و امروزه شبکه عصبی نشان داده است که کارهایی نظیر شناسایی الگو را به خوبی انجام میدهد. امروزه در بخشهای مختلف زندگی ما از شبکه مصنوعی استفاده میشود، برای مثال…
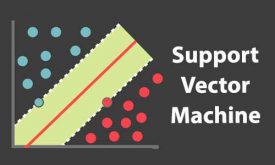
ماشین بردار پشتیبان svm
ماشین بردار پشتبیان(svm) یکی از طبقهبندهای معروف در حوزه شناسایی الگو جهت دسته بندی دادهها است. طبقهبند svm پایه ثابت اکثر مقالات تخصصی است و می بینیم که از طبقهبند svm برای طبقه بندی در اکثر کارها استفاده میکنند. در…
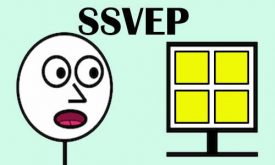
پتانسیل برانگیخته بینایی حالت پایدار،SSVEP چیست؟
پتانسیل برانگیخته بینایی حالت پایدار یا Steady State Visual Evoked Potential (SSVEP) پاسخ نورلوژیکی مغز به یک محرک بینایی است. وقتی یک محرک بینایی با فرکانس بالای 6 هرتز روشن خاموش و شود و فرد به این محرک بینایی خیره…
انجام بازی ویدیویی به صورت ذهنی توسط میمون با کمک نورالینک ایلان ماسک
ایلان ماسک ویدیویی از یک میمون را به اشتراک گذاشته که بازی های ویدیویی را با ذهن خود انجام می دهد. استارت آپ مغز و کامپیوتر Elon Musk ، کمپانی Neuralink ، از میمونی رونمایی کرده است که قادر است…
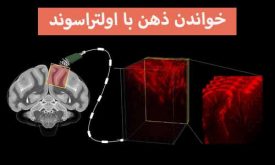
نقشه بردای مغز با اولتراسوند: Caltech واسط جدید مغز و کامپیوتر
یک محدودیت عمده در ایجاد واسط مغز-کامپیوتر این است که، دستگاهها برای خواندن فعالیتهای عصبی به جراحی مغزی، از نوع تهاجمی، نیاز دارند. اما اکنون در Caltech یک گروهی توانستهاند تا نوع جدیدی از واسط مغز و ماشین را با…
چطور یک مقاله تخصصی را در سریعترین زمان ممکن پیادهسازی کنیم!
پیادهسازی مقاله یکی از چالشهای اساسی برای دانشجویان میباشد. معمولا اکثر دانشجویان در پیادهسازی مقالات تخصصی مشکل دارند و شروع کار براشون سخت هست. در این بخش توضیح میدهیم که چطور میتوان یک مقاله تخصصی را در کوتاهترین زمان ممکن…
چرا ماشین بردار پشتیبان (SVM) در بین طبقهبندها جزء بهترینا هست؟
ماشین بردار پشتیبان(svm) یکی از معروفترین الگوریتمها در مسائل طبقهبندی هست که برای اولین بار توسط آقای Vladimir Vapnik در سال 1995 با عنوان support vectors networks مطرح شد. SVM در ابتدا برای مسائل طبقهبندی دو کلاسه خطی مطرح شده…
چطور با داده نامتعادل در آموزش مدلهای یادگیری ماشین مقابله کنیم؟
وقتی یک دادهای دارید که تعداد نمونههای گروهها خیلی متفاوت هستند، یا به اصطلاح یک داده نامتعادل دارید، دقت کلاسبندی به تنهایی به هیچ عنوان نمیتواند پارامتر مناسبی برای ارزیابی باشد. در این حالت بهترین کار اینه که سایر پارامترهای…
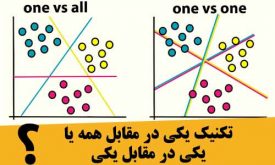
تفاوت تکنیک یکی در مقابل همه با تکنیک یکی در مقابل یکی
برخی از طبقهبندهای یادگیری ماشین، مثل SVM برای مسائل دو کلاسه طراحی شدهاند و اگر یکی بخواهد از این الگوریتمها در مسائل چند کلاسه استفاده کند، مجبور است که با کمک تـکنیکهایی طبقهبند را برای مسائل چندکلاسه تعمیم دهد. تکنیک…
انتخاب مدل یادگیری ماشین مناسب با کمک تیغ اوکام
احتمالا تا الان براتون پیش اومده که در یک پروژهای از دو مدل یادگیری ماشین استفاده کردهاید و مشاهده کردید هر دو تقریبا مثل هم عمل میکنند و بعد در انتخاب بین دو مدل به مشکل خوردهاید یا براتون سوال…
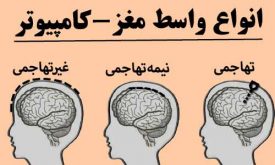
انواع واسط مغز و کامپیوتر(غیرتهاجمی-نیمه تهاجمی-تهاجمی)
بسته به اینکه از چه روش برای ثبت سیگنالهای مغزی استفاده میشود، واسط مغز و کامپیوتر را (BCI) را میتوان به سه دسته کلی تقسیمبندی کرد. روشهای زیادی برای ثبت سیگنالهای مغزی وجود دارد که به طور کلی میتوان BCI…