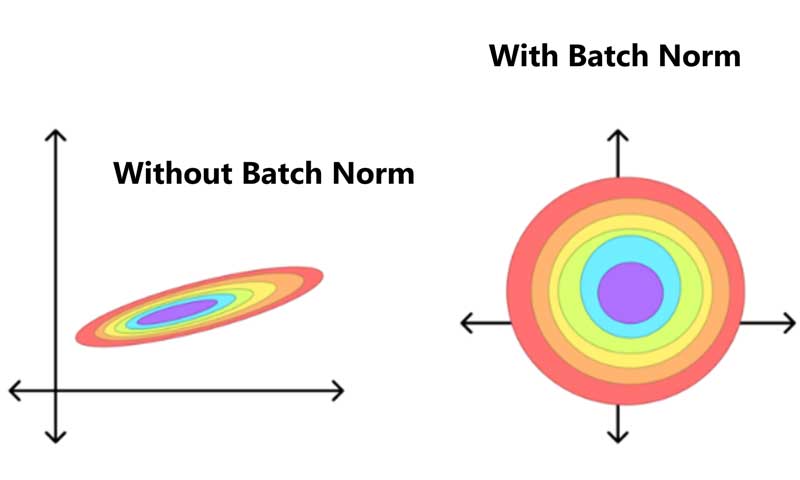
مفهوم Batch normalization در یادگیری عمیق
Batch Normalization یا نرمالسازی دستهای به عنوان یکی از تکنیکهای Generalization در یادگیری عمیق محسوب میشود که بطور مستقیم، در بهینهسازی مدلها نقش دارد. در واقع، پارامترهای ورودی را به کمک Adaptive normalization در مقیاسی مشابه قرار میدهد و اینگونه مشکلات ناشی از تغییر توزیع دادهها، طی مراحل آموزش را کاهش میدهد. اهمیت این تکنیک بهدلیل اینکه بطور همزمان، سه مزیت Preprocessing ، Numerical stability و Regularization را به ساختار مدل تزریق مینماید، بسیار مورد توجه محققان در این حوزه یادگیری عمیق قرارگرفته است. در ادامه، ابتدا به بیان مقدمهای در مورد چالش موجود و ایدهی حل آن توسط این تکنیک Batch Normalization میپردازیم. سپس، نکاتی در مورد تفاوتهای استفاده از این لایه در convolutional layer/ layer Dense و پیادهسازی آن به کمک کتابخانه پایتورچ ارائه میدهیم.
نقش Batch Normalization در Generalization مدلهای یادگیری عمیق
در فرآیند آموزش، همگرایی شبکههای عصبی عمیق در مدت زمان معقول میتواند یک چالش کلیدی محسوب گردد و شبکه ها به راحتی میتوانند دچار Overfitting شوند. بهدلایلی که هنوز از نظر تئوری به خوبی مشخص نشدهاند، منابع مختلف نویز در بهینهسازی، اغلب منجر به آموزش سریعتر و کاهش Overfitting میشوند. بهنظر میرسد که این تنوع، بهعنوان شکلی از regularization عمل میکند. یک تکنیک رایج برای regularization ، میتواند noise injection باشد، که اساس کار تکنیک Dropout را تشکیل میدهد و در پست قبلی به آن پرداخته شد.
ابتدا با این سوال بحث را آغاز میکنیم که Batch Normalization و Data Normalization چه تفاوتی با یکدیگر دارند؟
Data Normalization، یک مفهوم آماری است که در مدلهای یادگیری ماشین، یک روش معمول به منظور قرار دادن مقادیر ویژگیهای دیتاست، در scaleهای مشابه، پیش از ورود به فرآیند آموزش مورد استفاده قرار میگیرد و یکی از گامهای پیشپردازش محسوب میشود.
در واقع فرآیند آموزش، با ضرب وزنهای تصادفی اولیه در مقادیر(ویژگیهای) هر ورودی آغاز میگردد و با هر بار تخمین مدل، این وزنها در جهت رسیدن به خروجی مطلوب، توسط تابع هزینه، بهروزرسانی میشوند. در فرآیند بهروزرسانی وزنها (یادگیری شبکه های عصبی)، در مورد میزان تاثیر هر یک از این ورودیها در تخمین خروجی، تجدید نظر صورت میگیرد.
حال فرض کنید، بطور ذاتی، محدودهی مقادیر ویژگیهای یک دیتاست از یکدیگر بسیار متفاوت باشند. بطور مثال دو ویژگی وزن و سن افراد اگر در امکان ابتلا به بیماری دیابت مورد بررسی قرار گیرند، آنگاه در یک scale نبودن مقادیر این دو ویژگی، به شکل نامطلوبی میتواند در عملکرد مدل طراحی شده اثرگذار باشد. در چنین مواردی، با توجه به الگوی بهروزرسانی در مشارکت دادن بیشتر ویژگیهایی با مقادیر بزرگتر، در تخمین خروجی مطلوب، یک ارزشگذاری نادرست و به دنبال آن، یک بهروزرسانی غیرواقعی صورت میگیرد. ازاینرو، به منظور ایجاد یک نگاه عادلانهتر به تمام این ویژگیهای ورودی، یکیاز گامهای موثر در پیش پردازش، Data Normalization با توجه به نوع داده ورودی بهشمار میآید. روشهای متعددی برای نرمالسازی داده وجود دارد اما روش data standardization یکی از روشهای رایج در یادگیری ماشین/عمیق میباشد که در این روش، میانگین داده ها 0 و وارایانس یا محدودهی پراکندگی آنها، 1 در نظر گرفته میشود و پس از اعمال آن، مقادیر تمام ویژگیها، میانگین صفر و واریانس یک خواهند داشت. اینگونه، ویژگیها قبل از ورود به شبکه، به یک وحدت و یکپارچگی اولیه دست مییابند.
اما برای مدلهای عمیق تر یا به اصطلاح Deep Learning، آیا امکان بهمریختن scale خروجی لایهها، بعد از گذر از لایههای متعدد Dense/Convolution وجود دارد؟
در روشهای یادگیری ماشین مانند MLP، ما با یکسری لایههای نسبتا محدودی روبرو بودیم و تکنیک Data Normalization با توجه به نوع داده، میتوانست تاثیر زیادی در بهینهسازی مدل ایجاد نماید. اما در روشهای یادگیری عمیق، مخصوصا در مواردی که با لایههای عمیقتری مواجه میشویم، این مساله عنوان شد که در هر تکرار فرآیند آموزش، ویژگیهای ورودی در عبور از لایههای متوالی و ضرب در وزنهای جدید، ممکن است Regularization مد نظر خود را از دست بدهند. در نتیجه، هرقدر تعداد لایهها در معماری یک مدل بیشتر شود، با یک شبکه عمیق تری مواجه خواهیم شد که ممکن است شاهد تغییراتی در نوع توزیع داده ها در فرآیند بروزرسانی باشیم. بدین ترتیب، نیاز به نرمال سازی در اشل های کوچکتری همچون mini-batch احساس و تکنیک جدیدی با عنوان Batch Normalization متولد شد.
در سال 2015 تکنیک Batch Normalization به منظور نرمال سازی ورودیهای هر لایه(Convolution/Dense) با توجه به نمونههای موجود در هر batch، در هر تکرار فرآیند آموزش عنوان شد، که بر اساس قوانین آمار در ریاضیات، تغییراتی در Scale آنها بوجود میآورد. الگوریتم ارائه شده در این مقاله، در شکل 2 آمده است.

Batch Normalization تاثیر وزنهای تصادفی اولیه را کاهش میدهد، زیرا نمودار هزینه smooth تر میشود، بنابراین مهم نیست از کجا شروع کنید، کم و بیش با همان تعداد تکرار در هر نقطه شروع، به نقطه حداقل خواهید رسید. نهایتا، با Scaling مقادیر ویژگیهایی ورودی، نویزی به ورودی های مدل در حین آموزش وارد می شود که آن را در گروه تکنیکهای Generalization، به منظور افزایش پایداری مدل قرار میدهد.
تفکیک استفاده از تکنیک Batch Normalization در لایه های Convolution و لایههای Dense
اعمال لایه Batch Normalization، برای لایه های Convolution و لایههای Dense کمی متفاوت است. تفاوت اصلی این تکنیک در لایههای Convolution با لایههای Dense این است که عملیات را بر اساس هر کانال، در همه مکانها اعمال میکنیم. این نکته، بر پایه این فرض اساسی در روشهای کانولوشنال مطرح شده است که، مکان خاص یک الگو در یک تصویر، در یادگیری آن نقش کلیدی ندارد و مدل پس از آموزش باید بدون وابستگی به مکان قرارگیری، الگو را تشخیص دهد.
حال فرض کنید که mini-batch های ما حاوی m ترایال است و برای هر کانال، خروجی کانولوشن دارای pکانال و q نمونه است. برای لایههای کانولوشن، ما هر Batch Normalization را روی مجموع عناصر بصورت m · p · q در هر کانال خروجی، به طور همزمان انجام میدهیم. بنابراین، هنگام محاسبه میانگین و واریانس، مقادیر را روی همه مکانهای فضایی جمعآوری میکنیم و در نتیجه همان میانگین و واریانس را در یک کانال معین اعمال مینمائیم تا مقدار را در هر spatial location نرمال سازیم. هر کانال دارای پارامترها scale و shift خاص خود است که هر دو اسکالر هستند.
تفاوت کلیدی دیگر بین Batch Normalization layer و لایههای دیگر مانند Dropout layer این است که بهدلیل اعمال این لایه روی یک mini-batch کامل، در یک زمان، ما نمیتوانیم ابعاد batch ها را نادیده بگیریم زیرا، ورودیهای این دو لایه (Convolution/Dense) از نظر ابعاد متفاوتند.
در عمل، هنگام اعمال این تکنیک دو پارامتر باید مشخص گردد. پارامتر اول، تعداد ویژگیهای خروجی (برای یک لایه کاملا متصل) یا تعداد کانالهای خروجی (برای یک لایه کانولوشن) است. این پارامتر به لایه Batch Normalization کمک میکند تا توابع فعال را در امتداد این محور به طور مناسب scale و normalize کند.
پارامتر دوم، ابعاد دادههای ورودی است که برای یک لایه Dense معمولا روی 2 تنظیم میشود زیرا دادههای ورودی معمولاً به شکل یک ماتریس (داده های دو بعدی) هستند. اما برای لایههای کانولوشن، که دادههای ورودی به شکل تنسور هستند، باید این مقدار با توجه به ابعاد داده ورودی تنظیم شود تا ابعاد تنسور ورودی را بدرستی منعکس نماید. بطور مثال اگر داده ورودی یک سیگنال مغزی برای سیستم های BCI باشد، معمولا به صورت یک تنسور 4 بعدی (تعداد نمونه، تعداد کانال، تعداد ترایال، سایز هر batch) به مدل ارائه خواهد شد.
با تعیین مقادیر صحیح این دو پارامتر (تعداد خروجی و ابعاد داده ورودی) هنگام اجرای Batch Normalization، این لایه میتواند عملیات normalization و scaling را به طور موثر، بر اساس ساختار دادههایی که از لایههای کاملا متصل یا لایههای کانولوشن دریافت میکند، انجام دهد. در نتیجه، این تکنیک تضمین میکند که فرآیند نرمالسازی دستهای با ویژگیهای خاص معماری شبکه در حال استفاده تنظیم شده است.
کتابخانه پایتورچ، برای تفکیک نمودن این دو حالت یعنی اعمال این تکنیک روی لایه های Convolution و Dense، دو نوع متد معرفی کرده است که از نظر ابعاد، بصورت متفاوت نامگذاری شدهاند. هنگامیکه قصد داریم از این تکنیک، روی خروجی لایه Convolution استفاده نمائیم، از متد ()BatchNorm2d استفاده میشود اما هنگام بکارگیری این تکنیک روی خروجی لایه Dense متد ()BatchNorm1d، فراخوانی میشود.
پیاده سازی تکنیک Batch Normalization در پایتورچ
اولین نکته در استفاده از این تکنیک، در مورد رفتار متفاوت آن در training mode و prediction mode است. زیرا در مرحله آموزش، ما معمولاً از دستههای کوچک (mini-batches) برای محاسبه میانگین و واریانس استفاده میکنیم و نرمالسازی به صورت پویا و بر اساس دادههای هر دسته بهروزرسانی میشود. این محاسبات ممکن است شامل نویز باشند، زیرا هر دسته، کل دادهها را نمایندگی میکند و ممکن است تفاوت زیادی با کل دیتاست داشته باشد. این نویز در نهایت میتواند بر کیفیت آموزش تأثیر بگذارد. اما پس از اینکه مدل آموزش دیده و به مرحله تست میرسد، دیگر نیازی به محاسبه این آمار برای هر دسته نیست و میتوانیم از آمار کلی (نرمالسازی کل داده تست) استفاده نمائیم که رویکرد پایدارتر و دقیقتری است.
مورد دیگر اینکه، در برخی موارد، ممکن است نیاز داشته باشیم که مدل را برای پیشبینی تکتک ورودیها استفاده نمائیم. در این مواقع، محاسبه آمار نرمالسازی برای هر ورودی غیرعملی است. بنابراین، پس از آموزش، معمولاً از دادههای نرمالایز شده در فرآیند تست استفاده میشود. از این رو، به منظور فعال نمودن این لایه، مانند تکنیک Dropout، باید قبل از شروع فرآیند آموزش، متد train() را فراخوانی نموده و به منظور غیرفعال نمودن آن، در هنگام تست مدل، از متد eval()، پیش از شروع فرآیند تست، استفاده نمائیم.
نکته آخر، در خصوص جایگذاری این لایه در ساختار مدل است. طبق فرمول زیر، این لایه، ابتدا روی خروجی لایه Convolution/Dense اعمال میشود و پس از نرمالسازی ویژگیها، تحویل تابع فعال خواهند شد.
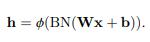
به منظور اعمال این تکنیک در طراحی مدل، باید ابتدا کتابخانه مورد نیاز را بصورت زیر وارد نمائیم:
Python
import torch.nn as nn
سپس به ترتیب، ابتدا Dense layer/Convolutional layer، سپس Batch normalization layer و بعد از آن Activation function قرار میگیرد. با توجه به اینکه در پست قبلی تکنیک Dropout مورد بررسی قرار گرفت، یک نمونه از نحوه استفاده از هر دو لایه، هنگام طراحی مدل بصورت Sequentioal() در ادامه نشان داده شده که در برخی مقالات به تاثیر بهتر در regularization مدل، با استفاده از هر دو لایه بطور همزمان نیز اشاره شده است.
Python
nn.Sequentioal(nn.Conv2D(),nn.BatchNorm2D(),nn.ELU(),nn.Dropout(p=0.5)) nn.Sequentioal(nn.Linear(),nn.BatchNorm1D(), nn.ELU(), nn.Dropout(p=0.5))
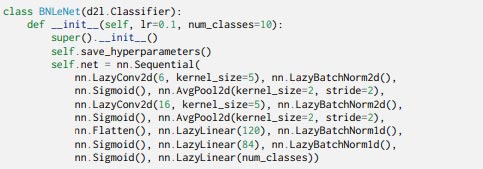
همچنین، یک نمونه پیاده سازی این تکنیک روی شبکه معروف LeNet در ادامه آمده است که هر دو نوع متد Batch Normalization روی خروجی لایه Convolution و لایه Dense مورد استفاده قرار گرفت.
تاثیر سایز batch ها در عملکرد Batch Normalization
یکی از نکات مهم هنگام استفاده از تکنیک Batch Normalization انتخاب سایز مناسب batchها است. یا حداقل، به کالیبراسیون مناسب نیاز است تا بتوانیم آن را تنظیم نمائیم. توجه داشته باشید که اگر بخواهیم نرمالسازی دستهای را با mini-batch هایی با سایز 1 اعمال نمائیم، مدل نمیتواند چیزی یاد بگیرد. زیرا پس از تفریق میانگین ها، ورودی مقدار 0 میگیرد. همانطور که ممکن است حدس بزنید، از آنجایی که ما یک لایه کامل را به نرمالسازی دستهای اختصاص میدهیم، با mini-batchهای به اندازه کافی بزرگ، این رویکرد موثر و پایدارتر است. نرمالسازی دستهای برای اندازههای mini-batchهای متوسط در محدوده ۵۰ تا ۱۰۰ بهترین کارایی را دارد. یک mini-batch بزرگتر از این محدوده، به دلیل برآوردهای پایدارتر، کمتر regular میشود، درحالیکه mini-batchهای کوچک، سیگنال مفید را به دلیل واریانس بالا از بین میبرند.
دوره های مرتبط

پیادهسازی شبکه های عصبی با پایتورچ PyTorch

دوره جامع و پروژه محور کاربرد شبکه های عمیق در بینایی ماشین

دوره جامع و پروژه محور شبکه عصبی بازگشتی RNN

شناسایی الگو (فصل4 بخش دوم): تئوری و پیادهسازی ماشین بردار پشتیبان(SVM) و شبکه عصبی MLP
دیدگاه ها