
مکانیزیم Attention در یادگیری عمیق
- دسته:اخبار علمی
- هما کاشفی
با پیچیدهتر شدن مدلهای یادگیری عمیق، نیاز به روشهای موثر پردازش میزان زیادی داده، اهمیت فزایندهای پیدا کرده است. یکی از این روشها، مکانیزیم توجه است که به مدل امکانی میدهد تا در هنگام پیش بینی بر مرتبطترین اطلاعات، تمرکز کند و پیشبینی را بر اساس آنها انجام دهد.
مکانیزیم Attention تلاشی برای پیادهسازی عمل تمرکز انتخابی بر روی اطلاعات مرتبطتر و در عین حال، نادیدهگرفتن اطلاعات با اهمیت کمتر در شبکههای عصبی عمیق است.
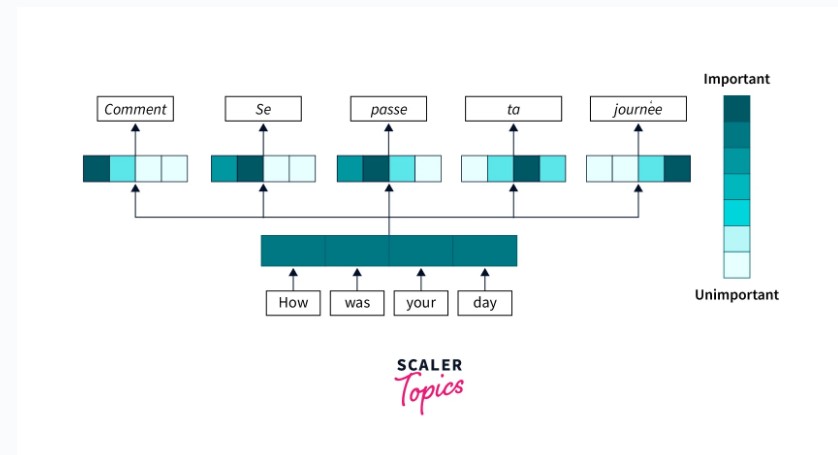
مکانیزیم Attention چیست؟
هدف از توسعهی مکانیزیم Attention در یادگیری عمیق آن است که به مدل کمک کنند تا بر روی مرتبطترین بخشهای ورودی تمرکز کند و پیشبینی را بر اساس این بخشها انجام دهد. در بسیاری از مسائل، دادهی ورودی ممکن است بسیار بزرگ و پیچیده باشد. ممکن است پردازش کل داده برای مدل دشوار باشد. مکانیزیمهای Attention به مدل این امکان را میدهند تا به طور انتخابی بر روی بخشهایی از ورودی تمرکز کند که برای پیش بینی مهمتر هستند و بخشهای کمتر مرتبط را نادیده بگیرد. این میتواند به مدل کمک کند تا پیشبینی های دقیقتری داشته باشد و به مدل کارآمدتری تبدیل شود.
نیاز به مکانیزیم Attention
در بسیاری از مدلهای یادگیری عمیق، داده با عبور از لایههای متعدد شبکههای عصبی پردازش میشود. این شبکهها از نورونهای به هم پیوستهی زیادی تشکیل شده اند که در لایهها سازماندهی شدهاند. هر نورون، داده را پردازش میکند و آن را به لایهی بعد انتقال میدهد. این روند امکانی را برای مدل فراهم میآورد تا ویژگیهای پیچیدهتری را از داده استخراج کند هنگامی که داده از شبکه، عبور داده میشود. با این حال، با عبور داده از این لایهها، شناسایی مرتبطترین اطلاعات برای مدل، به میزان زیادی دشوار میشود.
مکانیزیمهای Attention به عنوان راهی برای رفع این محدودیت در مدلها معرفی شد. در مدلهای مبتنی بر Attention، مدل میتواند هنگام پیش بینی به طور انتخابی روی بخشهای خاصی از ورودی تمرکز کند. ترجمهی ماشینی را به عنوان یک مثال در نظر بگیرید که در آن از مدل سنتی seq2seq استفاده میشود. مدلهای seq2seq معمولاً از دو جز تشکیل شدهاند: یک رمزگذار (Encoder) و یک رمزگشا (Decoder)
رمزگذار، توالی ورودی را پردازش میکند و آن را به صورت یک بردار با طول ثابت (بردار Context) ارائه میدهد و سپس به رمزگشا ارسال میشود. رمزگشا از این بردار زمینه با طول ثابت برای تولید خروجی استفاده میکند.
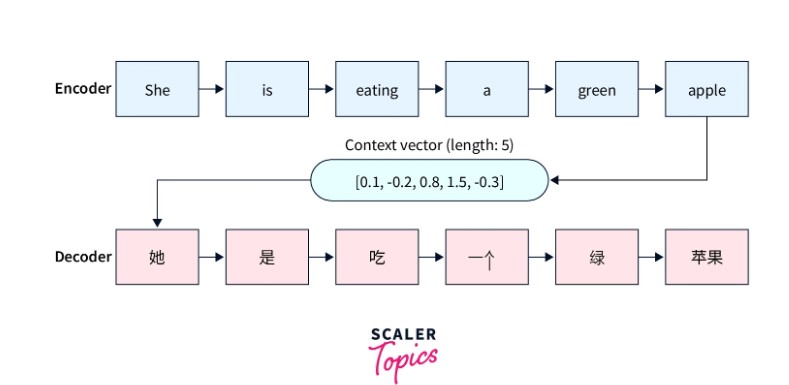
شبکههای رمزگذار و رمزگشا، شبکههای عصبی بازگشتی مانند GRU و LSTM هستند.
نکته: یکی از معایب آشکار این رویکرد، ناتوانی مدل در به خاطر سپردن توالیهای طولانی است زیرا بردار زمینه طول ثابت است.
بررسی اجمالی مکانیزیم Attention
مکانیزیم Attention، مشکل بحث شده در بالا را حل میکند. مکانیزیم Attention به مدل امکانی میدهد تا به بخشهای خاصی از داده «توجه کند» و هنگام پیش بینی به این بخشها، وزن بیشتری دهد.
به طور خلاصه، مکانیزیم Attention به حفظ زمینهی هر کلمه در جمله کمک میکند و برای این منظور وزن Attention به همهی کلمات دیگر میدهد. به این ترتیب، حتی اگر جمله خیلی طولانی باشد، مدل میتواند اهمیت زمینهای هر کلمه را حفظ کند.
برای مثال در تسکهای پردازش زبان طبیعی، تسکهایی مانند ترجمه زبان، مکانیزیم Attention میتواند به مدل کمک کند تا معنای کلمات در متن را درک کند. به جای پردازش هر کلمه به طور جداگانه، مکانیزیم Attention به مدل امکانی میدهد تا کلمات مربوط به سایر کلمات را در جمله در نظر بگیرد و به آن کمک میکند تا معنای کلی جمله را درک کند.
ما میتوانیم مکانیزیم Attention را به روشهای مختلفی پیادهسازی کنیم. اما یک رویکرد رایج استفاغده از شبکه عصبی است برای درک آنکه کدام بخش از دادهها، برای پیش بینی مرتبطتر هستند. این شبکه طوری آموزش داده میشود تا به مهمترین بخشهای داده توجه کند و در هنگام پیش بینی به آنها وزن بیشتری بدهد.
به طور کلی، مکانیزیم Attention ابزار قدرتمند برای بهبود عملکرد مدلهای توالی است. با فراهم آوردن امکانی برای مدل تا به مرتبطترین اطلاعات تمرکز کند، مکانیزیم Attention میتواند به بهبود دقت پیش بینی کمک کندا و با پردازش مهمترین دادهها، مدل را کارآمدتر کند. با پیشرفت یادگیری عمیق، ممکن است شاهد کاربردهای پیچیدهتری از مکانیزیم Attention باشیم.
مکانیزیم Attention چطور کار میکند؟
برای اینکه بتوانید مکانیزیم Attention را با جزئیات درک کنید، لازم است که مدلهای Sequence to Sequence مانند LSTM و GRU را به خوبی درک کرده باشید.
در دورهی جامع و پروژه محور شبکههای عصبی بازگشتی، این شبکهها را با جزئیات توضیح دادهایم.
اولین مقالهای که ایدهی مکانیزیم Attention را به دنیا معرفی کرد مقالهی Bahdanau و همکاران سال 2015 بود. این مقاله، مدل رمزگذار-رمزگشا را با مکانیزیم Additive Attention پیشنهاد میکند.
بیایید یک مثال ترجمه ماشینی را در نظر بگیریم که در آن x جملهی مبدآ با طول n و y نشانگر طول دنباله هدف با طول m است.

برای یک مدل توالی دو جهته که میتوان برای این تسک استفاده کرد، دو hidden state وجود دارد، backward و Forward. در کار Bahdanau و همکاران در سال 2015، یک ادغام ساده این دو hidden state نشانگر وضعیت رمزگذار است. به این ترتیب، هر دو کلمهی قبل و بعد را میتوان برای محاسبهی attention هر کلمه در ورودی استفاده کرد.
![]()
نکته: در یک مدل رمزگذار-رمزگشا معمولی، تنها آخرین hidden state رمزگذار نشانگر وضعیت رمزگذار است.
hidden state شبکه رمزگشا به صورت زیر است:
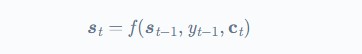
که در رابطه فوق t نشانگر طول توالی و ct بردار زمینه (برای هر خروجی yt) است که مجموع hidden stateهای توالی ورودی hi است که وزندار شده است.
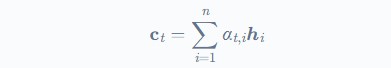
حال چطور این وزنها روی عملکرد شبکه اثر میگذارند؟ برای تعیین این وزنها از شبکه عصبی ساده feed-forward استفاده میشود که در امتداد بخشهای دیگر مدل، آموزش دیده است.
این مدل که مدل Alignment نام دارد به هر جفت ورودی i و خروجی در موقعیت t یعنی (yt, xi) بر اساس مرتبط بودن آنها یک امتیاز نسبت میدهد. مجموع این امتیازها تعیین میکنند که هر hidden state منبع چقدر باید در تعیین خروجی، دخالت داشته باشد.
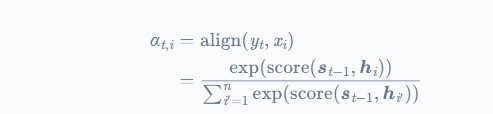
شبکه عصبی ساده feed-forward این وزنهای مرتبط بودن را یاد میگیرد و hidden state آن یک تابع softmax است که احتمالات را بدست آورد.

تصویر فوق یک ماتریس alignment را نشان میدهد که با استفاده از مکانیزیم Attention آموخته شده است.
سه جز اصلی معادله عبارتند از:
بردار Query یا Q که در برابر یک مجموعه مقادیر key تنظیم میشود تا امتیاز بدست آید.
بردار Key یا K که مجموعه وزنهایی است که اهمیت هر المان query را مشخص میکند.
بردار Value یا V
مفهوم key/value/query مشابه سیستمهای بازیابی است. برای مثال زمانی که شما برای ویدیویی در یوتیوب سرچ میکنید، موتور جستجو، query شما (متن در نوار جستجو) را در برای یک مجموعه مقادیر key نگاشت میکند (عنوان ویدیو، توصیف و …) که با ویدیوهای کاندید در دیتابیس همراه است و سپس منطبقترین ویدیوها (value) را برای شما برمیگرداند.
مکانیزیم Attention را میتوان به عنوان فرآیند بازیابی در نظر گرفت.
در مکانیزیم Attention مقاله Bahdanau و همکاران سال 2015، مقدار V و بردارهای K اساساً مشابه هستند و hidden stateهای رمزگذاری شده همان hها هستند و بردار Query، خروجی رمزگذار قبلی است.
انواع Attention
انواع مختلفی از مکانیزیم Attention وجود دارد که میتوان آنها را در مدلهای یادگیری عمیق استفاده کرد. برخی از رایجترین انواع آن عبارتند از:
Self-Attention
تصور کنید که جملهی زیر به عنوان ورودی برای مدل ترجمه ماشینی استفاده میشود:
The driver could not drive the car fast enough because it had a problem.
در جملهی فوق آیا it به driver اشاره دارد یا به car؟ کدامیک مشکل دارند؟
برای انسانها، این یک پاسخ ساده است اما برای ماشینها اگر نتوانند اطلاعات زمینه را یاد بگیرند ممکن است خیلی واضح نباشد.
به عنوان مثال به هنگام ترجمه ماشینی، بسیار مهم است که امتیاز Attention را برای توالیهای منبع و هدف داشته باشیم و آن را بین خود توالیهای منبع قرار دهیم که معنی آن self-attention است.
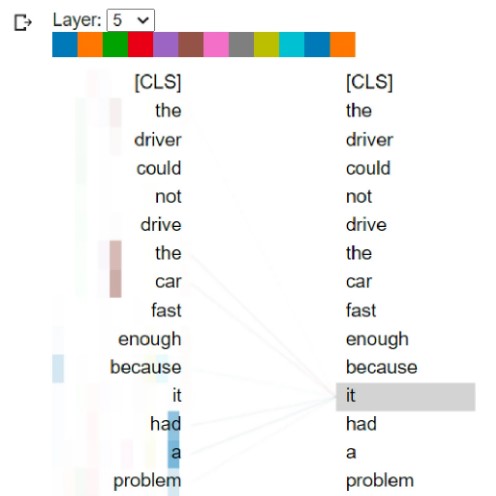
تصویر فوق نشانگر وزنهای attention مدل آموخته است و ما میتوانیم ببینیم که چه زمانی کلمه it رمزگشایی شده است و مدل به درستی به کلمه car بیش از هر کلمهی دیگری توجه کرده است.
Dot-product Attention
مکانیزیم Dot-product Attention، وزنهای Attention را به صورت ضرب نقطهای بردارهای query و key محاسبه میکند.
Scaled dot-product Attention
این نوع Attention که نوعی از dot-product Attention است و ضرب نقطهای را با ریشه مربع بعد key مقیاس بندی میکند.
Multi-head Attention
این نوع Attention، بردارهای query, key, value را به چندین سر جدا میکند و dot-product attention را به هر سر به طور جداگانه اعمال میکند.
Self-Attention
نوع Self-Attention نوعی از مکانیزیم Attention است که در بخشهای قبلی مورد بحث قرار گرفته است. در اینجا توالی ورودی هم به عنوان query و هم به عنوان key استفاده میشود.
Structured Attention
نوع Structured Attention امکانی فراهم میآورد تا وزنهای Attention با استفاده از مدل پیش بینی ساختاریافته آموخته شوند.
این مکانیزیمهای مختلف Attention را میتوان در ترکیبات و ساختاربندیهای مختلف استفاده کرد تا به عملکرد خوبی رسید.
دوره های مرتبط

دیدگاه ها